pi0
Paper: https://arxiv.org/pdf/2410.24164
Links:
- https://www.physicalintelligence.company/blog/pi0
- https://www.physicalintelligence.company/download/pi0.pdf
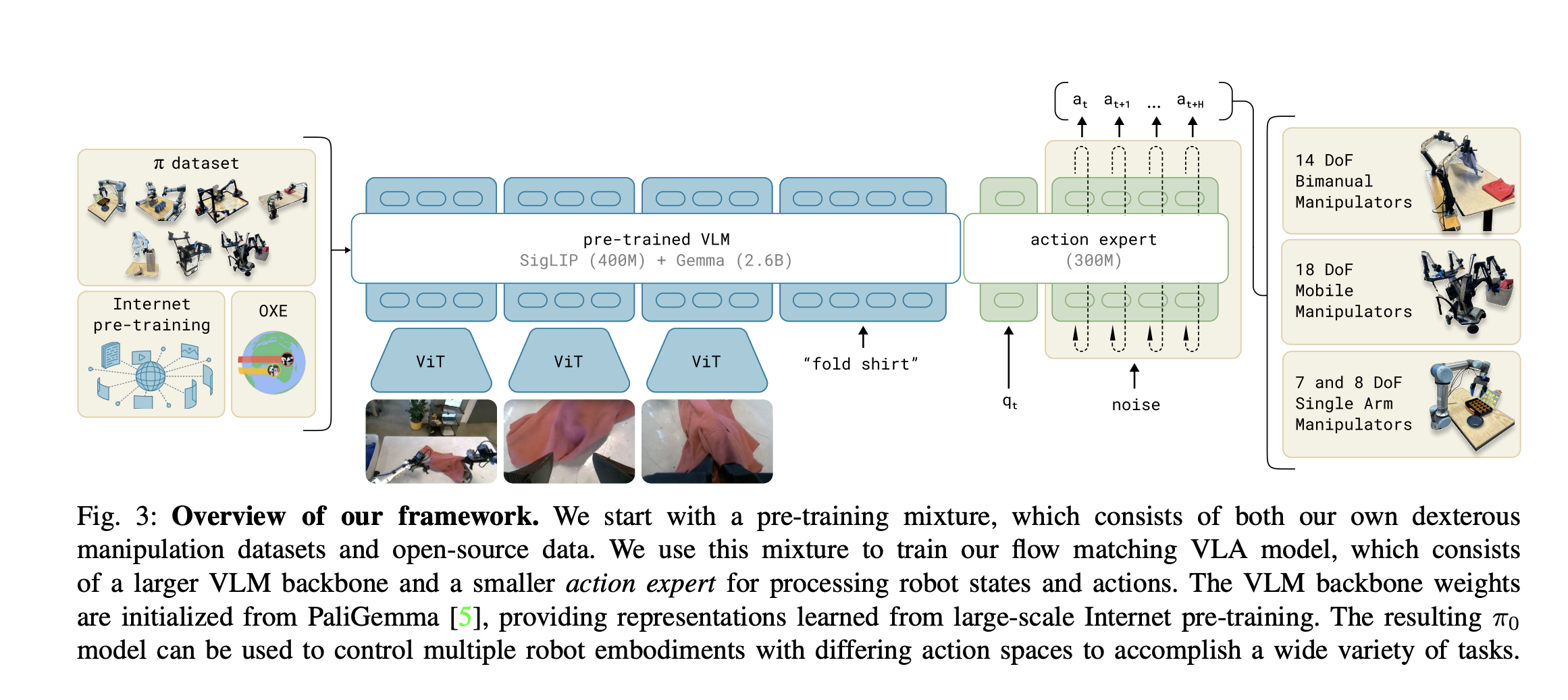
The images and proprioceptive state are encoded via corresponding encoders and then projected via a linear projection layer into the same embedding space as the language tokens.
Model Architecture
” averaging over 10 trials per task”
- This is how many trials they do to get success rate
Why flow-matching?
- To ensure /constrain smooth robot outputs as opposed to random jumps in values