Normalizing Flow
A normalizing flow transforms a simple distribution (generally a Unit Gaussian) into a complex, data-like distribution using a sequence of invertible and differentiable functions.
Intuition
Build a complex distribution by stacking invertible transforms on a simple one (Gaussian). Because every transform is invertible and you can compute its Jacobian, you get exact log-likelihoods via change of variables, unlike GANs (no density) or VAEs (only a lower bound). The price: every layer has to be invertible, which constrains the architecture (coupling layers, 1×1 convs, etc.)
Why an invertible transform instead of a separate encoder/decoder?
Invertibility lets us evaluate exact log-likelihood via change of variables, so training is MLE with a tractable objective, no ELBO or adversary needed
This is an idea I saw Billy Zheng write about: https://hongruizheng.com/2020/03/13/normalizing-flow.html
Resources
Normalizing flow learns an invertible transformation between data and latent variables:
where:
- is a data sample
- is a latent variable sampled from a simple distribution
You can't just have
zThe function in normalizing flows is perfectly invertible. We care about density estimation, not reconstruction. The loss is based on the log-likelihood of data under the model (more below). A flow with a separate encoder/decoder would basically be an Autoencoder
We can write this in terms of probability density function (comes from the Change-of-Variable Formula theorem in probability):
Geometric picture
Probability mass has to be conserved. If stretches a tiny volume around by a factor of , the density at must drop by the same factor so the total still integrates to 1. The Jacobian determinant is exactly the local volume-stretch of the transform.
Where does
\det(\frac{\delta f^{-1}}{\delta x})come from?
- In training, data flows : apply the inverse flow and minimize the loss over . Compute the Log Likelihood using the change-of-variable formula: . Notice the magic, because below, we can then use , all thanks to the fact that is invertible
- In sampling / generation, data flows : sample from the base distribution and apply the forward flow
Difference with VAE?
It comes down to how we formulate the loss. In a VAE the encoder and decoder are separate networks:
- Normalizing flow is deterministic: no randomness is added when transforming , we know exactly what happens
- VAE is stochastic: the encoder samples from a learned distribution and outputs a distribution
Both model Gaussians:
- In flows, the Gaussian is transformed through exact, invertible functions to match the data
- In VAEs, the model approximates the mapping between data and latent Gaussian through separate encoder/decoder networks
Sampling:
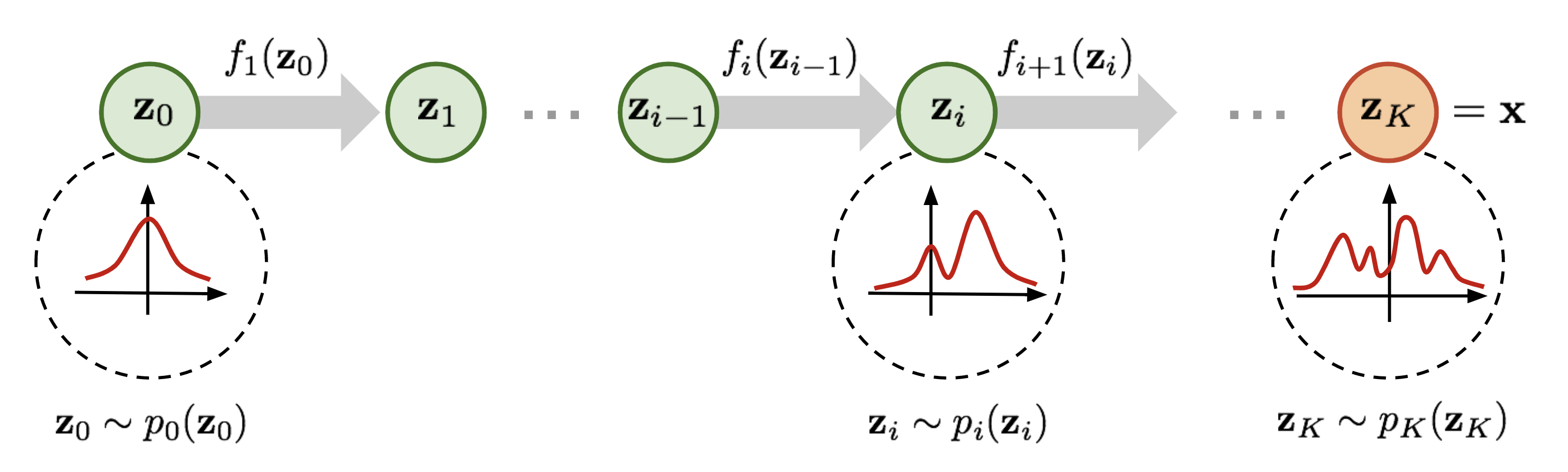 We apply a chain of invertible transformations:
We apply a chain of invertible transformations:
where:
- is a latent variable sampled from a standard Gaussian
- Each is an invertible transformation (e.g. affine coupling layer)
- Output is a realistic-looking data sample
What does look like? Depends on the model. They’re generally just Affine Transforms, since those are differentiable.
The trick of a coupling layer: split the input in half, leave the first half alone, and use it to compute a scale and shift for the second half. The first half is unchanged, so inversion is trivial; and because only depends on (not vice versa), the Jacobian is triangular and its determinant is just the product of the diagonal ( entries). That’s why can be arbitrarily complex neural nets without wrecking invertibility.
Forward pass:
Inverse pass:
where:
- and are neural networks (often small CNNs or MLPs)
- Same parameters are reused in both directions
How Weight Updates Work in Flow-Based Models
Training is done via maximum likelihood estimation (MLE) using the change-of-variables formula.
Change of Variables
Given and :
Rewriting using forward Jacobian:
The fundamental difference
This loss uses a Jacobian, derived from the change of variables formula. We’re not just doing
Training Steps
- Inverse pass: given data , compute
- Compute log-likelihood loss:
- Backpropagate through:
- the inverse transformations
- the neural nets and
- the log-determinant term (structured for easy computation in RealNVP/Glow)
- Gradient Descent: use Adam/SGD to update parameters in and
Normalizing flow gives you an explicit representation of density functions.
Used a lot in Generative Model.