Inverted Index
An inverted index is a data structure mapping each term to the list of documents containing that term, enabling fast boolean queries. Learned in CS451 and revisited in ECE459 L17.
Why "inverted"?
A book’s normal index maps terms to page numbers, so it’s already inverted relative to reading the book cover-to-cover. A forward index maps documents to terms, which is the direction you’d read. The inverted index is what you query.
A posting is a record that associates a specific term with a set of documents it appears in.
Terminology:
- Inverted Index: terms to documents
- Forward Index: documents to terms
Postings size follows Zipf’s Law:
- a few terms occur very frequently
- many terms occur very infrequently
- like the 80-20 Rule
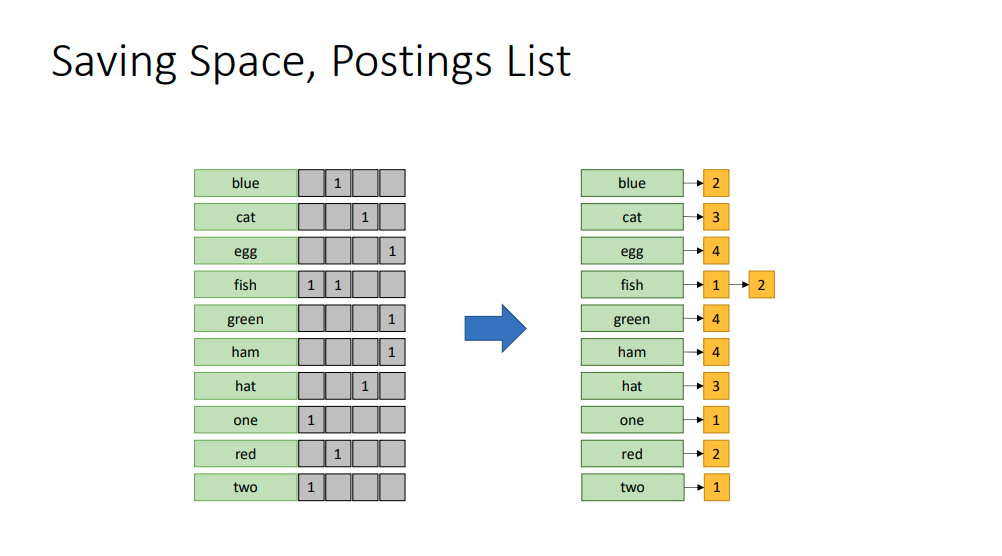
Instead of using that structure, use a linked list.
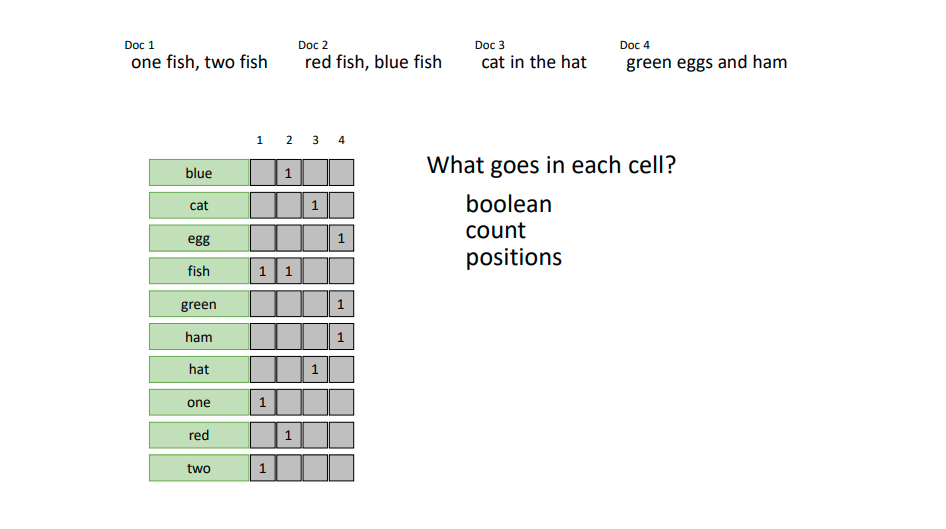
L17 example
Setup for Stream VByte:
| docid | terms |
|---|---|
| 1 | dog, cat, cow |
| 2 | cat |
| 3 | dog, goat |
| 4 | cow, cat, goat |
becomes
| term | docs |
|---|---|
| dog | 1, 3 |
| cat | 1, 2, 4 |
| cow | 1, 4 |
| goat | 3, 4 |
Posting lists contain many small integers. Sort the doc IDs and store deltas between successive IDs. The deltas are typically small, which opens the door to variable-byte integer encodings like VByte / Stream VByte.