Pipeline Hazard
Pipeline Hazards are situations in pipelining when the next instruction cannot execute in the following clock cycle. There are 3 types of pipeline hazards:
- Structural Hazard
- This happens when the hardware cannot support the combination of instructions we want to execute in the same clock cycle
- RISC-V is designed to be pipelined, so structural hazards are fairly easy to avoid
- Data Hazard (MOST IMPORTANT)
- Occurs when a planned instruction cannot execute in the proper clock cycle because data that are needed to execute the instruction are not yet available
- This is a very Common thing
- Control Hazard (Branch Hazard)
- When the proper instruction cannot execute in the proper pipeline clock cycle because the instruction that was fetched is not the one that is needed; that is, the flow of instruction addresses is not what the pipeline expected.
sub x2, x1, x3 // Register z2 written by sub
and x12, x2, x5 // 1st operand(x2) depends on sub
or x13, x6, x2 // 2nd operand(x2) depends on sub
add x14, x2, x2 // 1st(x2) & 2nd(x2) depend on sub
sw x15, 100(x2) // Base (x2) depends on sub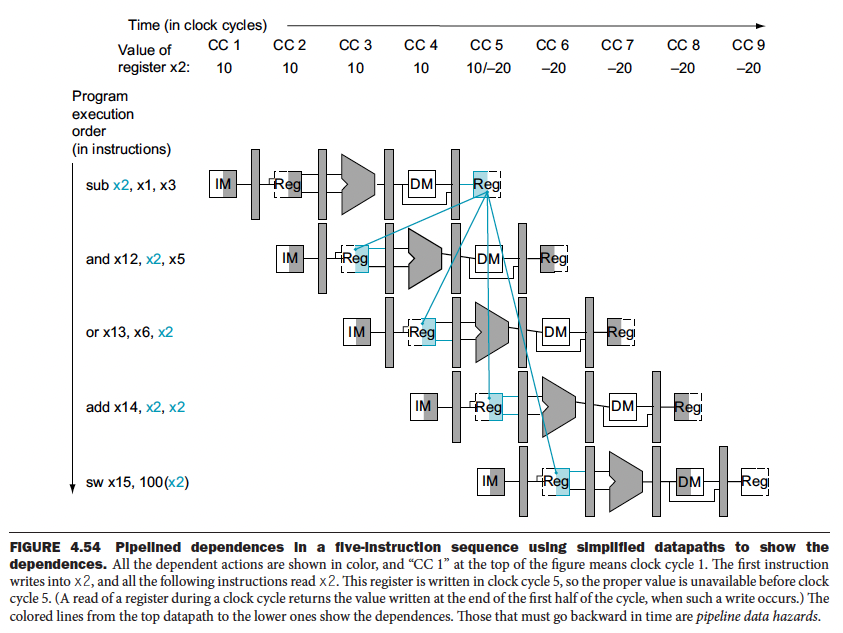
- Whenever the arrow goes backwards, you have a data hazard
In the example below, we would have a pipeline data hazard because x19 is immediately used afterwards.
add x19, x0, x1
sub x2, x19, x3The solution to a data hazard is to do Data Forwarding. The insight is that we don’t need for the instruction to complete before trying to resolve the data hazard. For the code sequence above, as soon as the ALU creates the sum for the add, we can supply it as an input for the subtract. We add extra hardware to support Data Forwarding. The insight is that we don’t need for the instruction to complete before trying to resolve the data hazard. For the code sequence above, as soon as the ALU creates the sum for the add, we can supply it as an input for the subtract. We add extra hardware to support Data Forwarding, see image below.
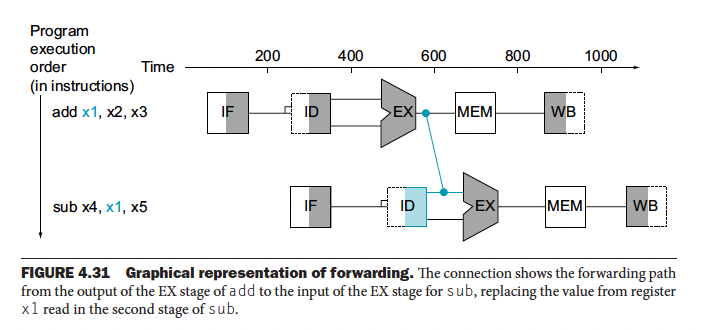
The above example is simple, in the context without pipelining drawings??
There are two parts:
- Detecting a data hazard
- Forwarding the proper data
You need a forwarding unit to do Data Forwarding.
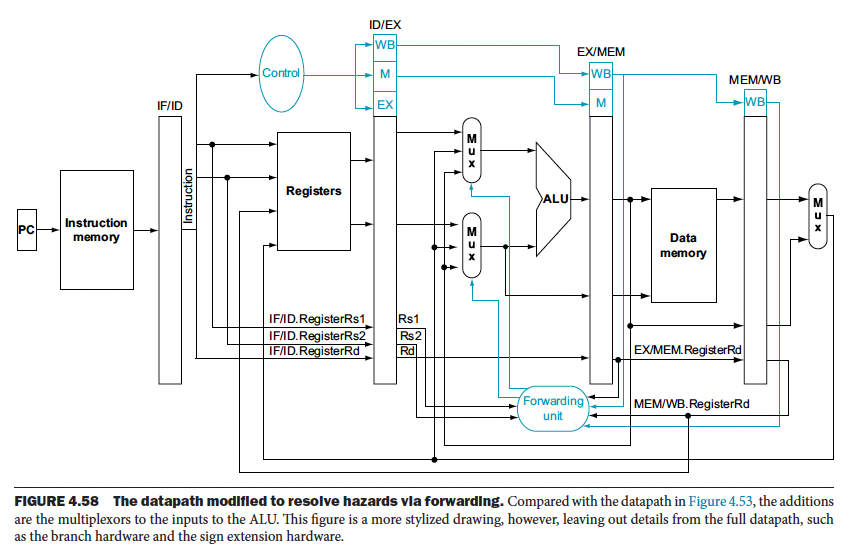
However, sometimes forwarding doesn’t work. For example, consider the scenario below:

- The dependence goes backwards in time so we need to “stall”, i.e. actually wait for the instruction to complete
In addition to a forwarding unit, we need a Hazard Detection Unit.
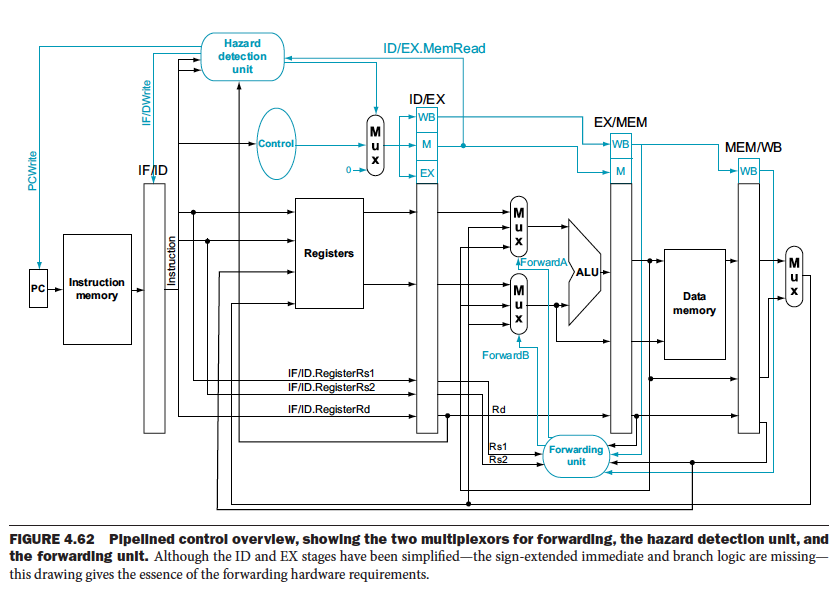
When you cannot do Data Forwarding, you gotta do stalling with Data Forwarding, you gotta do stalling with NOPs.

Control Hazard / Branch Hazard
These are simpler to handle, and occur less often than Data Hazards.
We do branch Prediction.
dynamic branch prediction = prediction of branches at runtime using runtime information.
- One implementation of this is a branch prediction buffer / branch history.
pipeline stall (also called bubble): A stall initiated in order to resolve a hazard.