CPU Pipelining
Pipelining overlaps the stages of consecutive instructions so that throughput approaches one instruction per cycle, even though each individual instruction still takes multiple cycles end-to-end.
Why?
An instruction goes through fetch, decode, operand-fetch, execute, writeback. Running them strictly sequentially wastes the hardware for four of those five stages at any moment. Pipelining keeps every stage busy on a different instruction.
- https://www.youtube.com/watch?v=3l10o0DYJXg&ab_channel=PERLI (~7:10): “Pipelining is at the core of compiler optimization”
- First learned in ECE222
They use the analogy of doing your laundry to illustrate pipelining, which I really like.
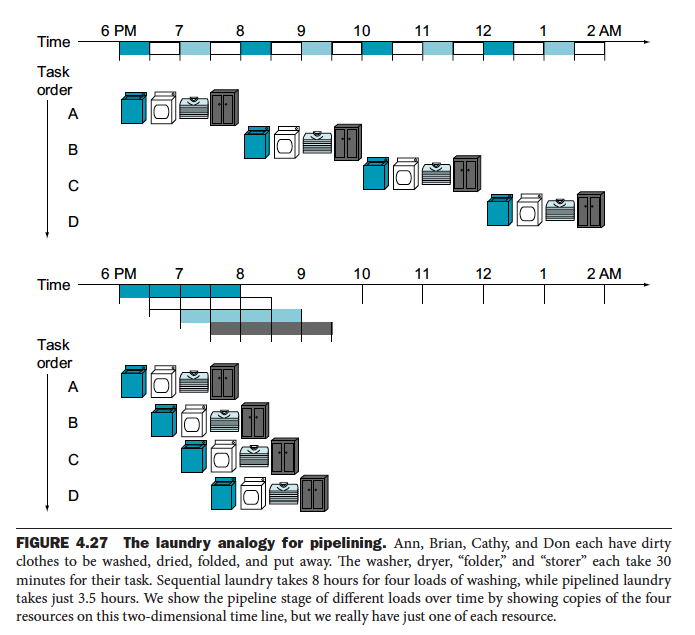
It is a form of Parallelism.
With pipelining, the computer architecture allows the next instructions to be fetched while the processor is performing arithmetic operations, holding them in a buffer close to the processor until each instruction operation can be performed. The staging of instruction fetching is continuous. The result is an increase in the number of instructions that can be performed during a given time period.
They have data forwarding which gives greater performance.
Else there is this thing called NOPs which implements stalling.
Important not to get confused on
Pipelining does NOT decrease the execution time of an individual instruction (i.e. Latency). Rather, it improves performance by increasing instruction throughput.
- Instruction throughput is the important metric because real programs execute billions of instructions. Also see CPU Performance for discussion about this?
RISC-V pipeline has 5 stages.
- IF: Instruction fetch
- ID: Instruction decode and register file read
- EX: Execution or address calculation
- MEM: Data memory access
- WB: Write back
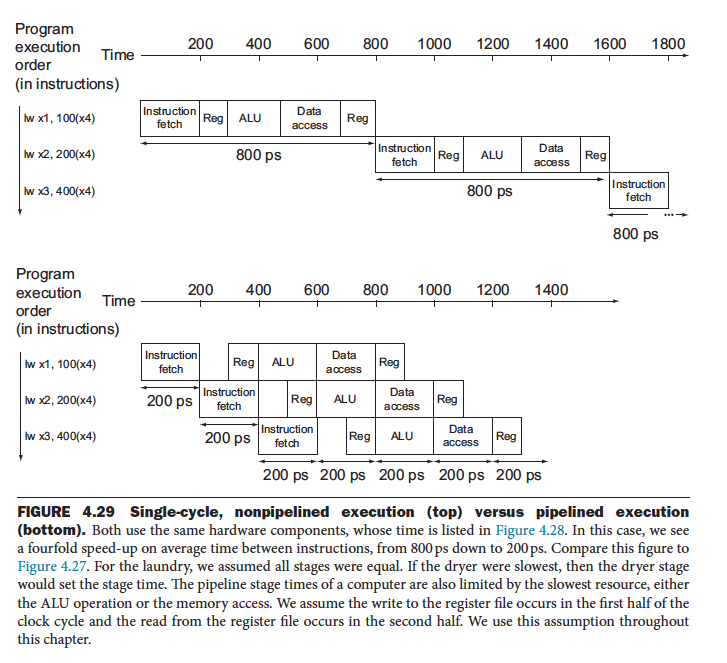
Implementation in RISC-V
We first explore the implementation ignoring any potential hazard. Let’s look at our Datapath and split it into the 5 stages:
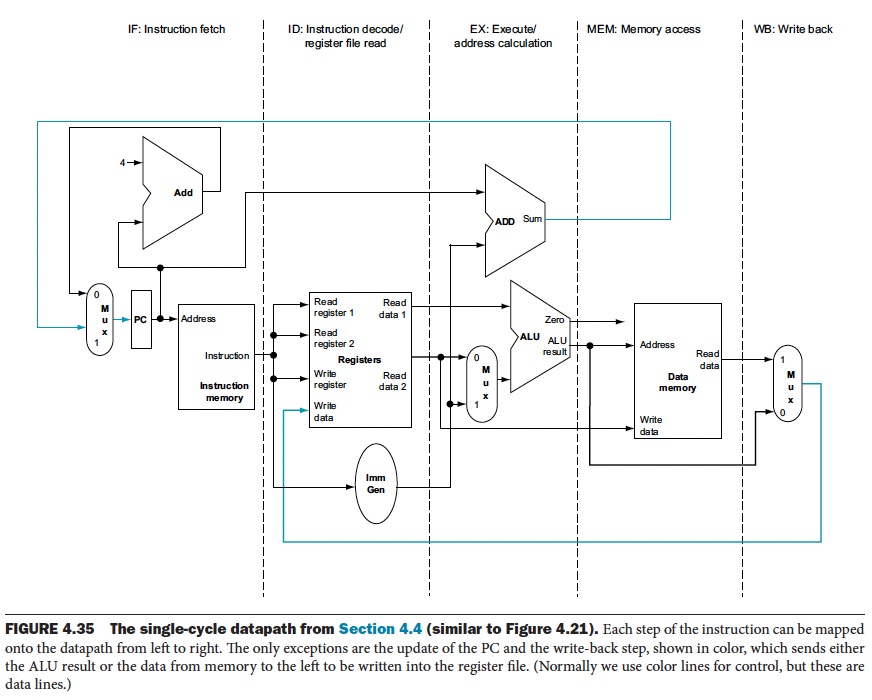
Instructions are data generally move from left to right in the above diagram, with two exceptions:
- The write-back stage, which places the result back into the register file in the middle of the Datapath
- The selection of the next value of the PC, choosing between the incremented PC and the branch address from the MEM stage
Data flowing from right to left do not affect the current instruction; these reverse data movements influence only later instructions in the pipeline. Note that the first right-to-left flow of data can lead to data hazards and the second leads to control hazards.
We add registers to hold data so that portions of a single datapath can be shared during instruction execution.
- Personal Insight: It’s kind of the same idea for Big-O Notation, there is this tradeoff between Space and Time. We make use of more space to make time much faster.
Register being read = right half in blue Register being written = left half in blue
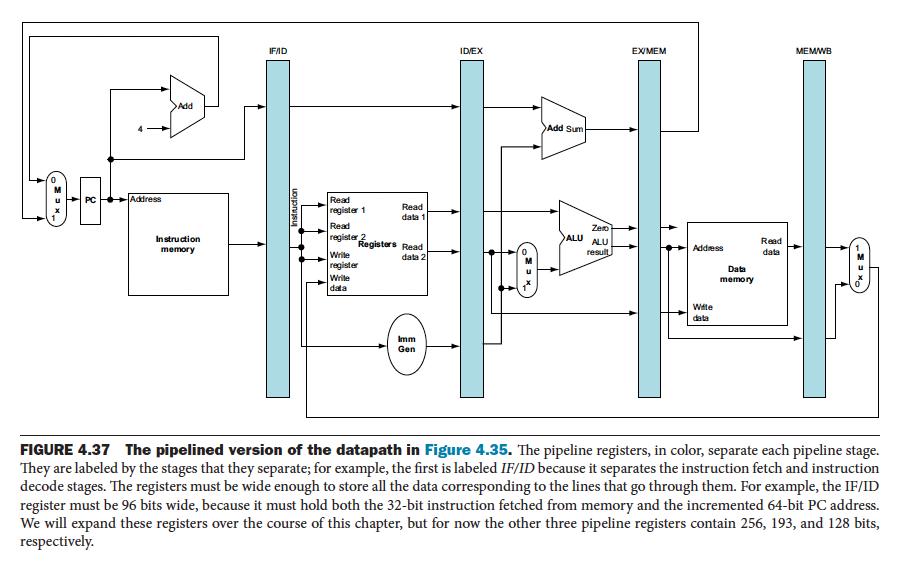 This is exactly the same diagram as the above.
This is exactly the same diagram as the above.
However, there is a bug with the above pipelined implementation. During the WB stage, we need the register to write into, which is provided by the IF/ID pipeline register. Hence, we need to preserve the destination register number in the load instruction.
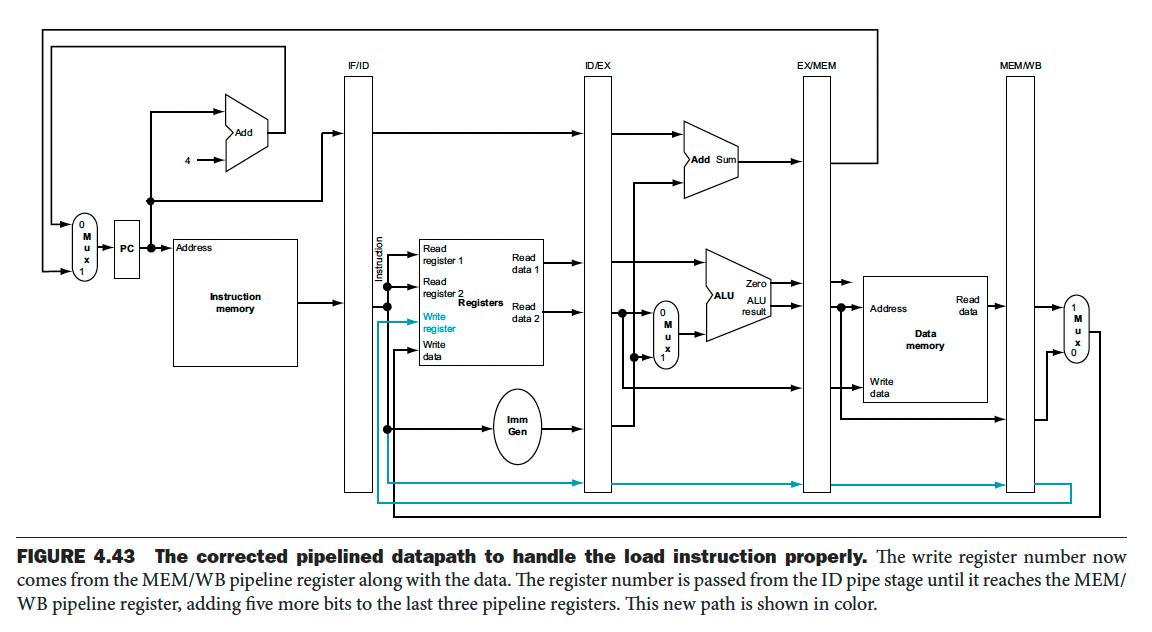
At this point, we are ready to talk about pipelining the Control Unit as well. Let’s see which control lines are used for each stage of the pipeline:
- IF: Assert read instruction memory and write the PC control signals
- ID: Nothing special to control
- EX: ALUOp and ALUSrc need to be set
- MEM: Branch, MemRead and MemWrite
- WB: MemToReg, and RegWrite
So we can have the following:
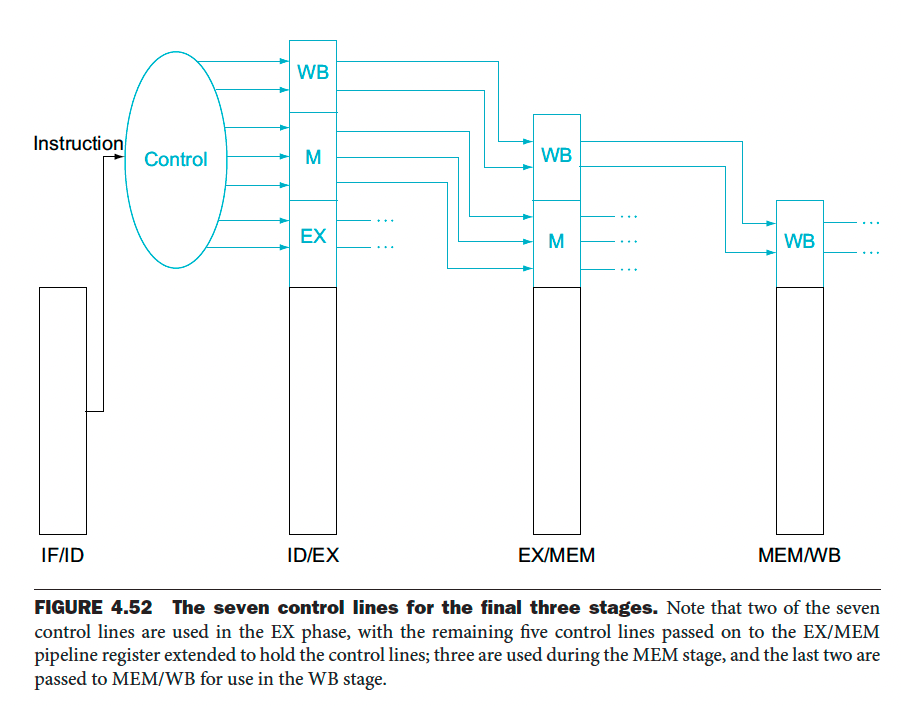
- Now, remember that there are 7 control lines (8 control signals since ALUOp takes 2 signals) for the Control Unit that we saw in the non-pipelined version
This forwarding is the same idea as when we talked about the bug that was introduced, during the WB stage, where we need the value of the RegisterRd.
See below for the actual control signals.
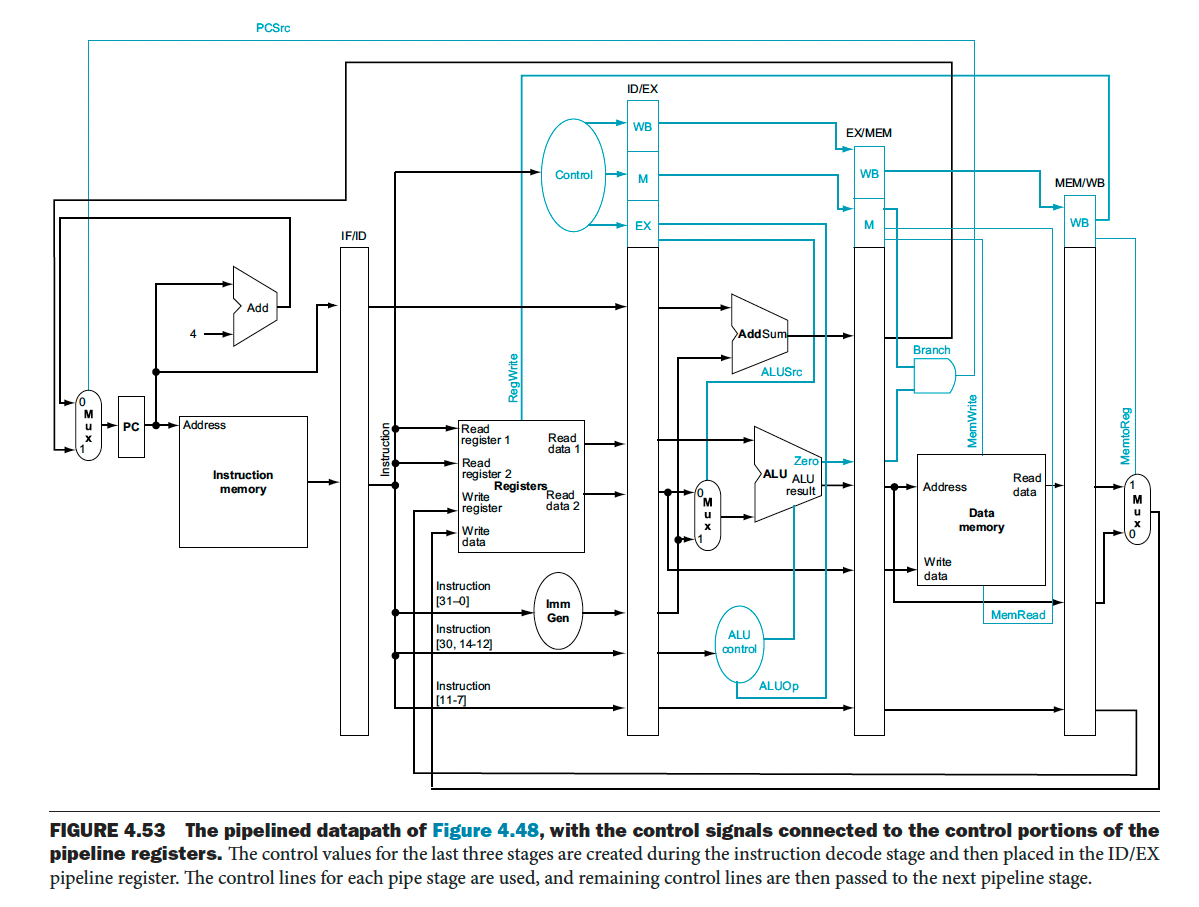
There are going to be hazards, such as when you write to a register, and access it right after. If you implement pipelining, you will get the wrong value. Take a look at Pipeline Hazard to understand how we resolve these issues.
From ECE459 L06
Three ECE459-specific angles on pipelining:
Pipeline flush on mispredict. A mispredicted branch forces the CPU to throw away everything already fetched/decoded/in-flight behind the branch. All that work was wasted, which is why branch prediction accuracy matters so much at deep pipelines.
RISC vs CISC and pipelining. RISC (simpler instructions, fewer cycles each) is much easier to pipeline deeply. CISC like x86 has variable CPI (~4–10 cycles per instruction), which makes pipelining harder; internally x86 CPUs actually break CISC ops into RISC-like micro-ops to pipeline them.
Delay slots. A RISC pipeline quirk: the instruction immediately after a branch is always executed (it’s already been fetched), or the result of a computation may not be available to the next instruction in time. Two ways to handle it:
- Compiler inserts a NOP: safe but wastes the slot
- Compiler rearranges code to do useful independent work in the slot
bne r1, r2, target ; branch
add r3, r4, r5 ; ← delay slot: ALWAYS runs, even if branch taken
target:
...
Modern architectures mostly hide delay slots with branch prediction + speculation instead of exposing them to software.