Prefetching
Prefetching is a technique in which data blocks needed in the future are brought into the cache early by using special instructions that specify the address of the block.
This is prediction.
Wow, I was first introduced to this in ECE222, seeing it again for CUDA course.
Prefetching is a technique used to improve memory access performance by bringing data into the cache before it is actually needed. In CUDA, prefetching is achieved by using the cudaMemPrefetchAsync function, which is used to asynchronously prefetch data from host or device memory to device memor
Resources
You can do this with CUDA Stream, see CUDA Prefetcher.
Asynchronous Memory Prefetching
Prefetching ables you to asynchronously migrate Unified Modeling Language to any CPU or GPU device in the background PRIOR to its use by application code.
- reduces the overhead of page faulting and on-demand memory migrations
- By doing this, GPU kernels and CPU function performance can be increased on account of reduced page fault and on-demand data migration overhead.
Prefetching performs lots of SPEEDUP!
Prefetching tends to migrate data in larger chunks, and therefore fewer trips, than on-demand migration. This makes it an excellent fit when data access needs are known before runtime, and when data access patterns are not sparse.
CUDA Makes asynchronously prefetching managed memory to either a GPU device or the CPU easy with its cudaMemPrefetchAsync function:
int deviceId;
cudaGetDevice(&deviceId); // The ID of the currently active GPU device.
cudaMemPrefetchAsync(pointerToSomeUMData, size, deviceId); // Prefetch to GPU device.
cudaMemPrefetchAsync(pointerToSomeUMData, size, cudaCpuDeviceId); // Prefetch to host. `cudaCpuDeviceId` is a built-in CUDA variable.From my own experiment:
Before
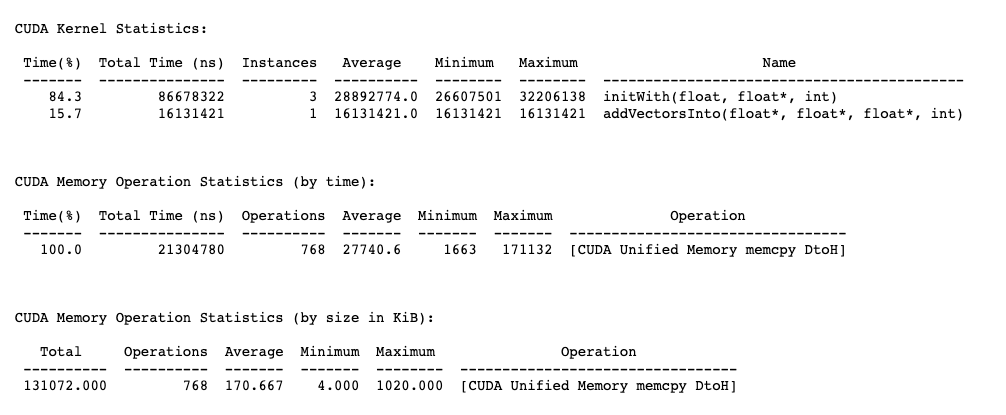
After (added prefetching)

So ~17x speedup in speed! Because you avoid the copying operation. But total runtime is still approx the same?