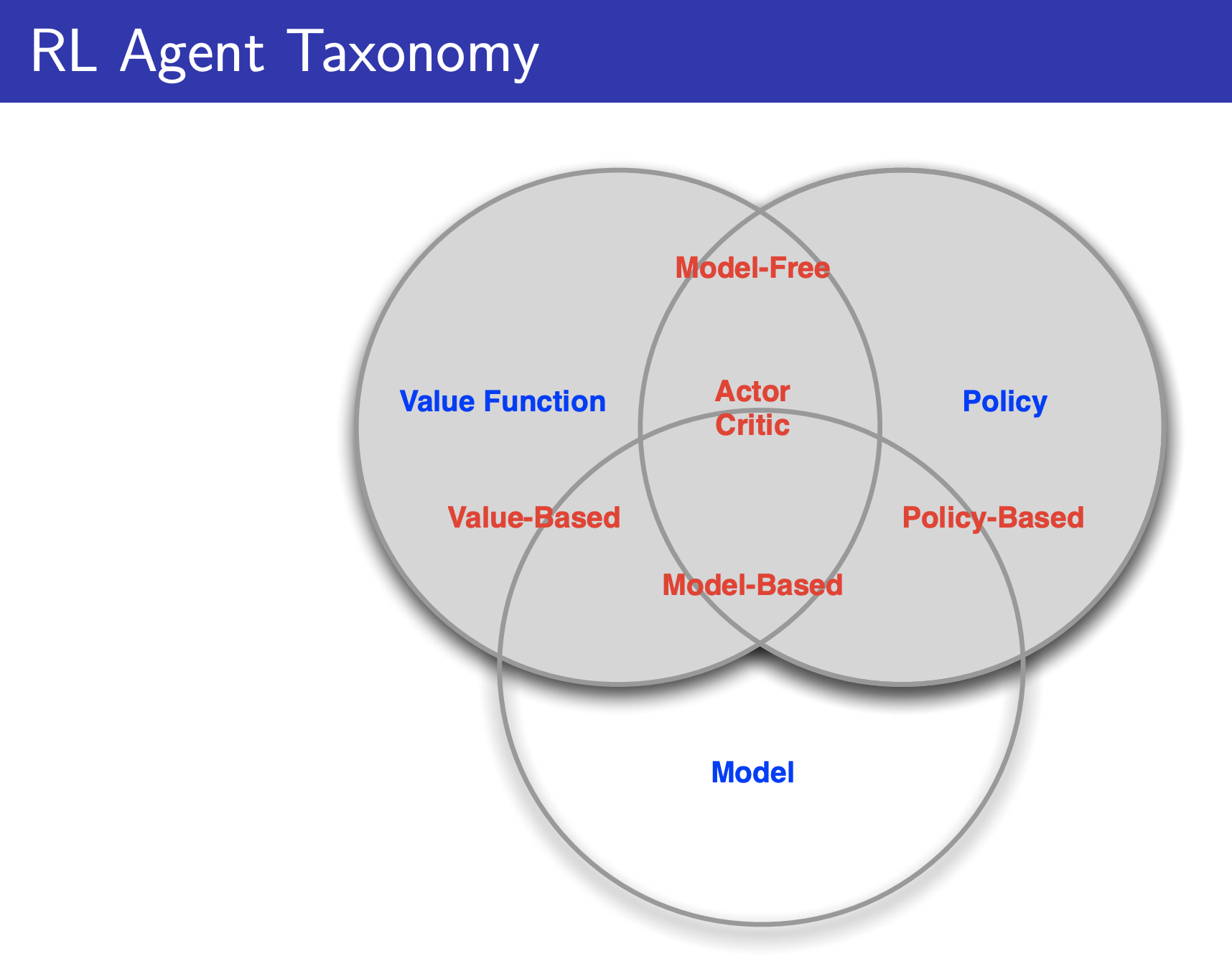
RL Agent
An RL agent may include one or more of these components:
- Policy: agent’s behaviour function
- Value Function: how good is each state and/or action
- Model: agent’s representation of the environment
Model
It is not required, this is where there is the difference between model-free and model-based RL algorithms.

Categories of RL Agents
- Value-Based Value-Based Methods
- No policy (Implicit, ex: -greedy), there is Value Function
- Policy-Based Policy Gradient Methods
- Policy, and no Value Function (maybe a little bit)
- Actor Critic
-
Stores both policy and value function
-
Critic: Updates action-value function parameters
-
Actor: Updates policy parameters , in direction suggested by critic
-
Actor-critic algorithms follow an approximate policy gradient
-
Model-Free → Policy and/or value function, no model Model-Based → Policy and/or value function, with model
Policy Gradient Methods vs. Value-Based Methods
Why would you choose a value-based method over a policy-based method?
Policy optimization:
- More stable
- Less sample-efficient
Value-based methods:
- more sample-efficient (because off-policy, old samples can still be reused, there’s a Replay buffer)
The value function might be quite complicated. But the policy might be very simple to represent. There are cases where a policy might be more compact.
See Policy Gradient Methods for advantages and disadvantages.
The problem value-based methods
In high dimensions, there can be many maximums for the Q-function that be “hacked”, resulting in exploits