Soft Actor-Critic (SAC)
Resources
- https://spinningup.openai.com/en/latest/algorithms/sac.html
- Implementation here
- Original paper https://arxiv.org/pdf/1801.01290
We optimize the policy according to
- is to represent that the action is sampled fresh from the policy, as opposed to taking the action from the replay buffer.
where is a sample from the policy with Reparametrization Trick
How is SAC different from DDPG?
It seems that we are also trying to argmax the Q, but we are not working with a deterministic policy.
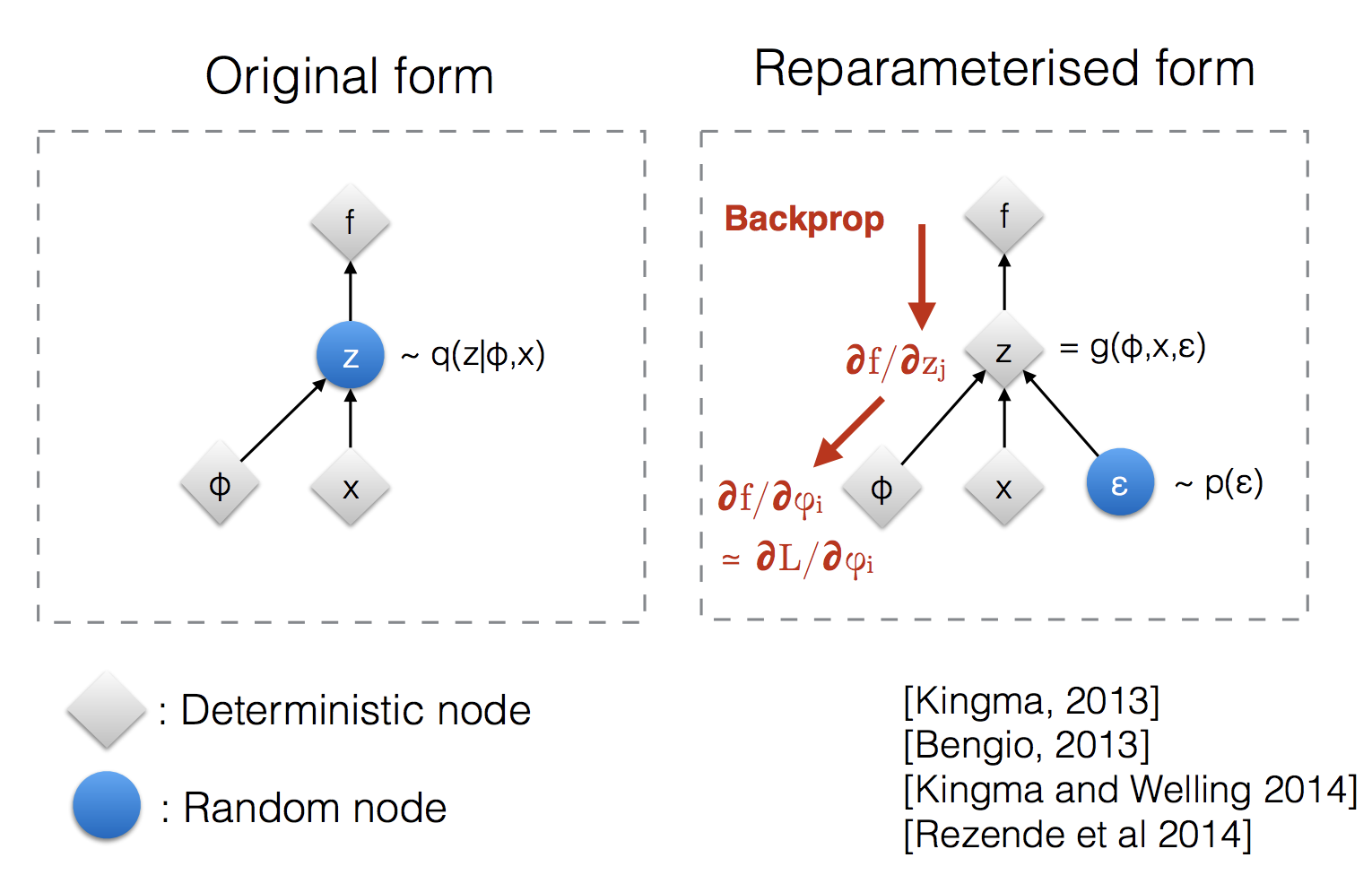
What / why Reparametrization Trick?
This was initially confusing to me, since in VPG, we also sample the action, yet we don’t seem to need the reparametrization trick.
The issue here is that we want to figure out how change our parameters to maximize . However, the gradients just stop propagating once we pass if we don’t use the Reparametrization Trick:
- Replace with our function here, and with our action
In VPG, we don’t need this since we don’t actually sample new actions during the update, just the log probability of the action (see VPG implementation).
Implementation Detail
In VPG, TRPO, and PPO, we represent the log std devs with state-independent parameter vector (see VPG note where I also point this out). However, in SAC, we represent the log std devs as outputs from neural networks.
Why is that? State-dependent variance lets SAC adapt exploration locally rather than globally. This flexibility is critical for entropy regularization to balance exploration vs exploitation effectively.
