Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data (WSRL)
WSRL = warmstart RL
Project page:
Motivation
This is a problem that I have noticed too. There’s too strong of a mismatch between the offline dataset dataset and online dataset distribution.
This mismatch results in too much unlearning. What is their solution?
Definitions:
- “unlearning” = the performance drop at the start of fine-tuning, with possible recovery later,
- “forgetting” = destruction of pre-trained initialization at the beginning of fine-tuning such that recovery becomes nearly impossible with online RL training
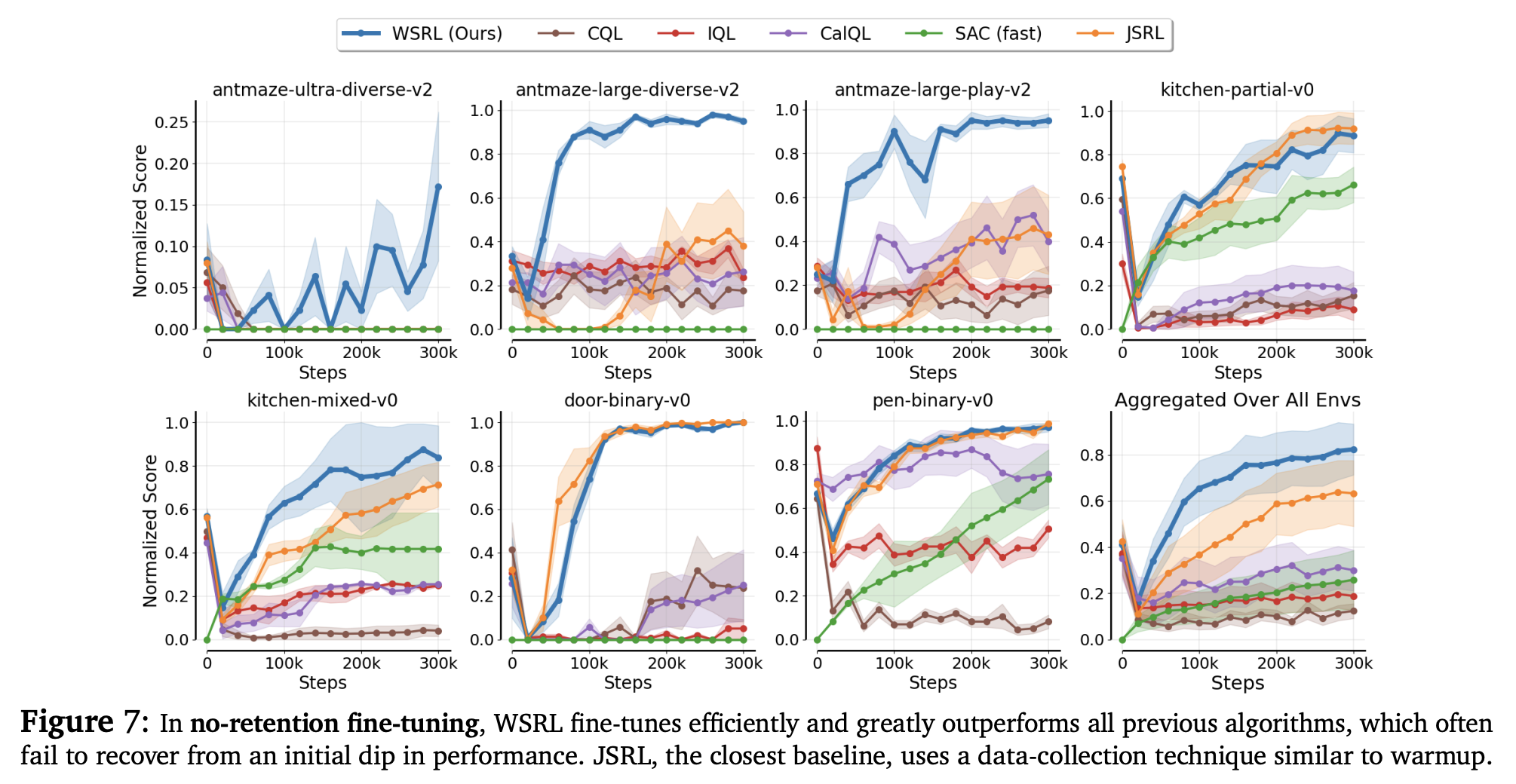
- Well its not completely fair algortihm, these are algos that are not meant do do well with no retention
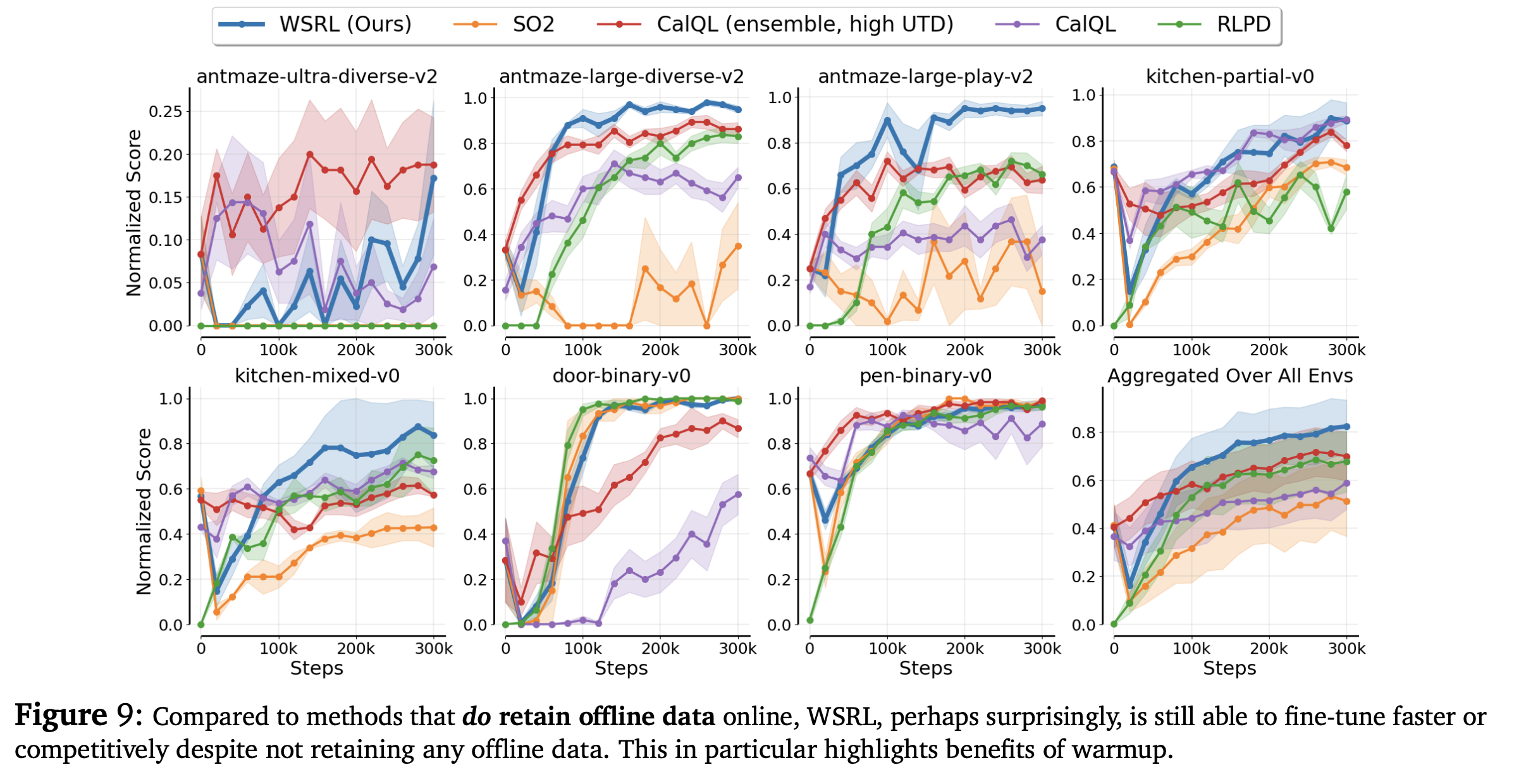
This is compared to methods that do retain data online, it does slightly better in the online setting good job
- though we need an initialized Q
 “In general, unlearning may be unavoidable due to the distribution shift over state-action pairs between offline and online”
“In general, unlearning may be unavoidable due to the distribution shift over state-action pairs between offline and online” - Is this avoidable if we have a world-model and do On-Policy training, similar to how they do it in Learning to Drive from a World Model?
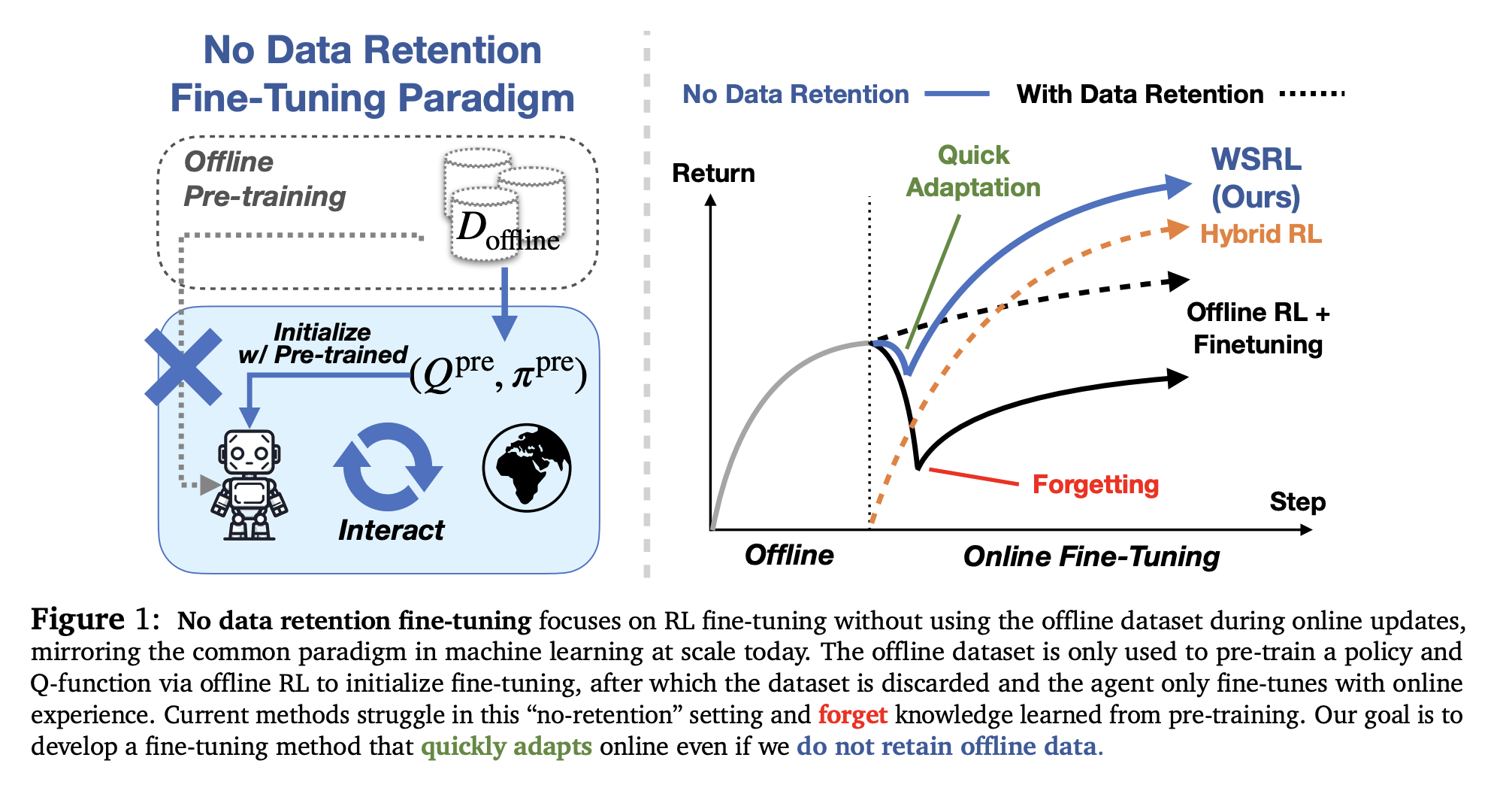
forgetting the pre-trained initialization altogether is problematic since it defeats the benefits of offline RL pre-training.
Why Warm-up Prevents Q-Values Divergence
This is really important. Warmup solves this problem by putting more offline-like data into the replay buffer where Q-values are not as pessimistic, thereby preventing the downward spiral in the online Bellman backups and uses high UTD in online RL to quickly re-calibrate the Q-values.
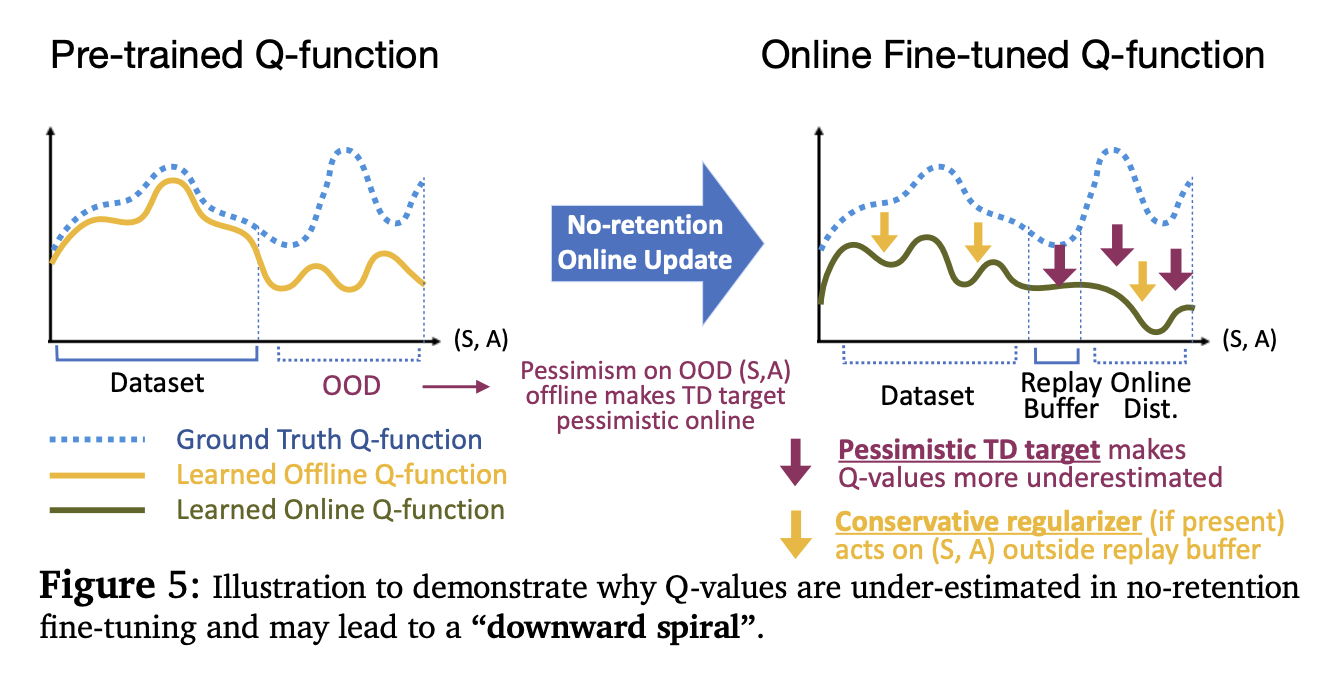
These figures are really important to think about how to debug these issues.
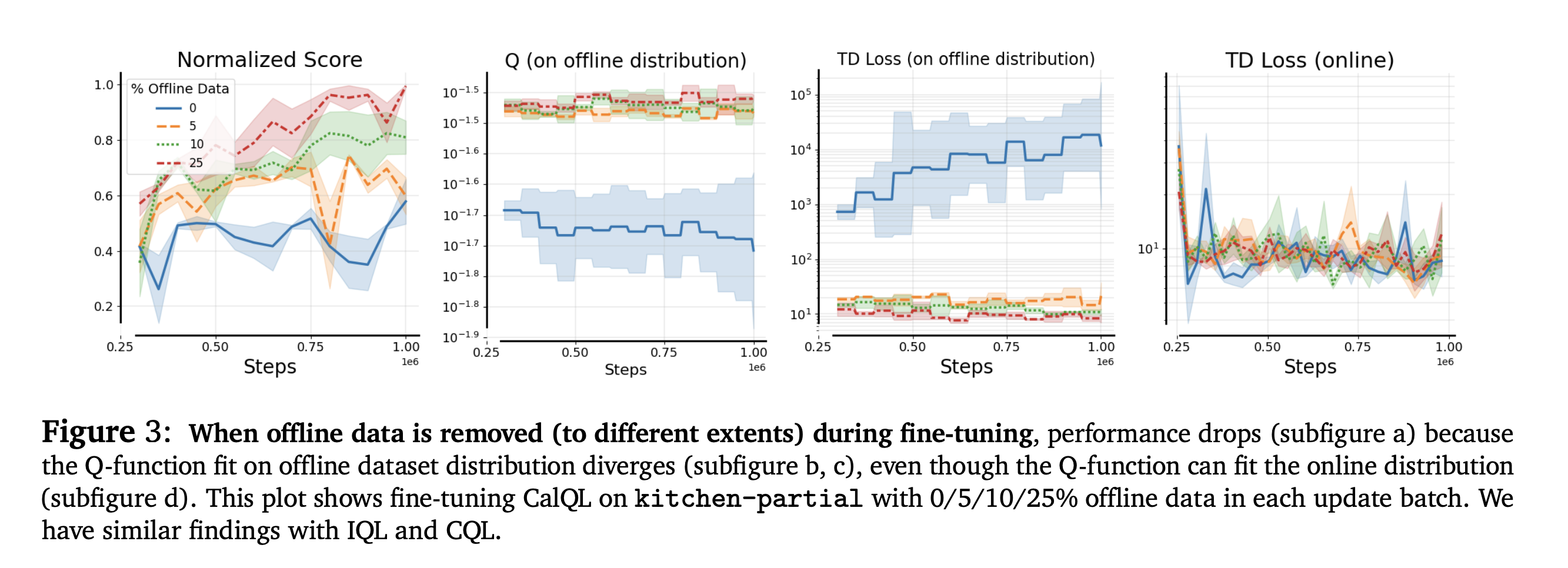
- 2nd figure shows how the Q scores on the offline distribution stay about the same, whereas if we just leave out the dataset, it just completely forgets it
“Fine-tuning on more on-policy data destroys how well we fit offline data”.

This is really interesting: for places where pretraining doesn’t work, their implementation also doesn’t work. Yet, for Q-Chunking, those curves look reallly good?
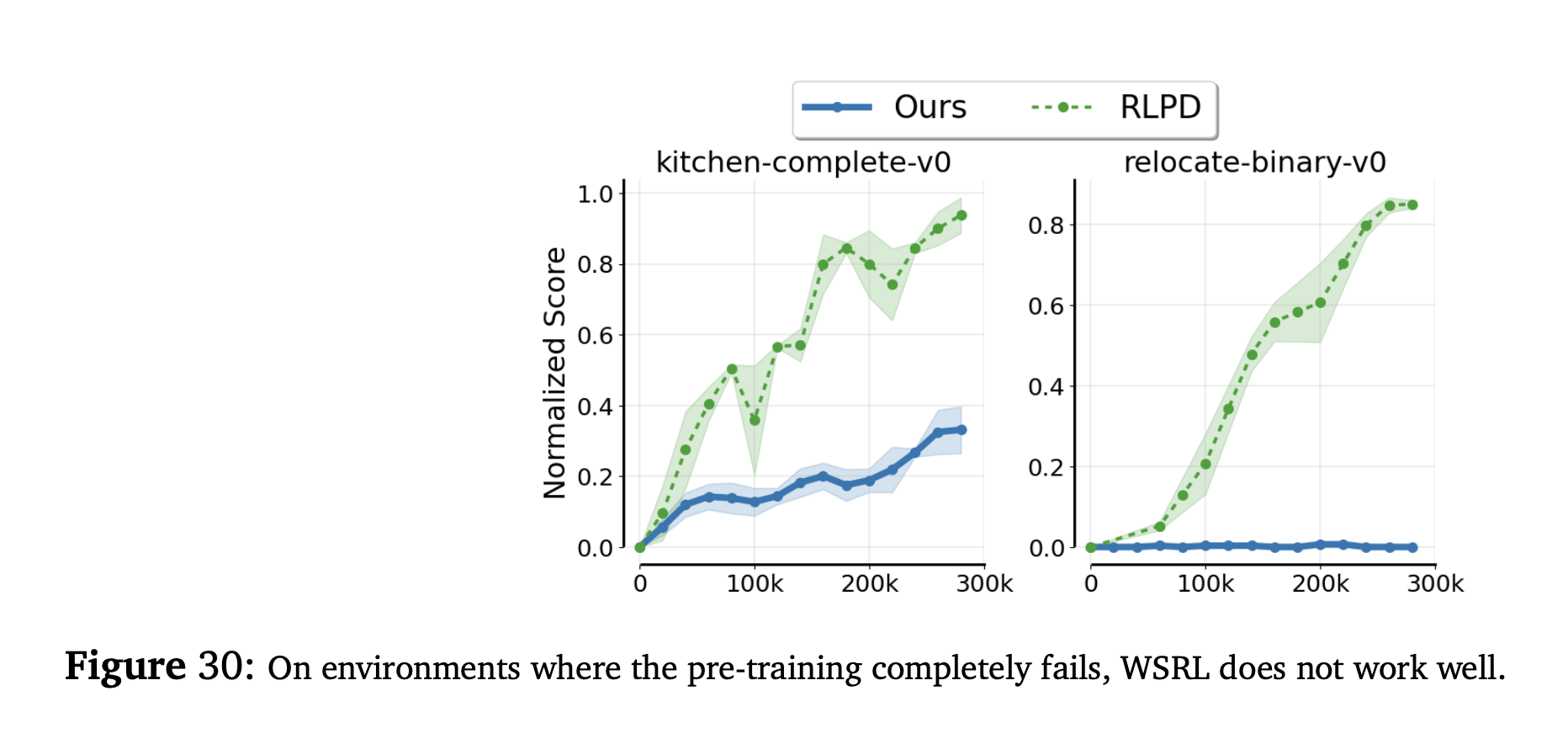
“this is expected because when pre-training fails, initializing with the pre-trained network may not bring any useful information gain, and may actually hurt fine-tuning by reducing the network’s plasticity”
They quote “The primacy bias in deep reinforcement learning”