Reinforcement Learning Metrics
Debugging RL is really hard. In supervised learning, you can just look at loss and validation curves. But what do we look at for RL?
- Actually, the Q chunking codebase has a good handful of metrics that they actually calculate for you, which you can see yourself
And important skill is to debug overfitting / non-overffiting.
For example, our task has 0 success rate in offline RL. Why is the task 0% success rate during eval?
- Prove state distribution mismatch
- Plot the distribution of states in the offline dataset
- See the data distribution in the online RL setting
Offline-to-online RL
- Prove unlearning
Metrics:
- Q variance
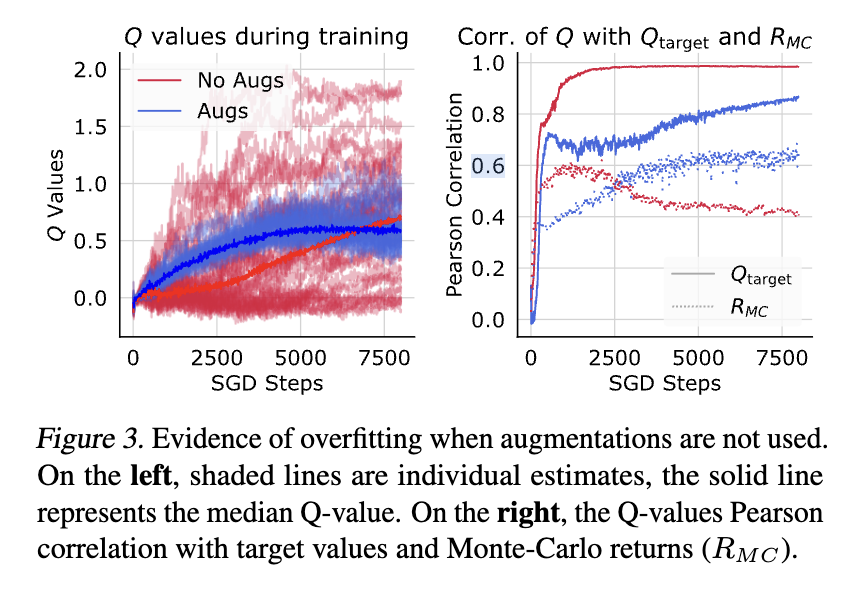 Q Variance
Q Variance
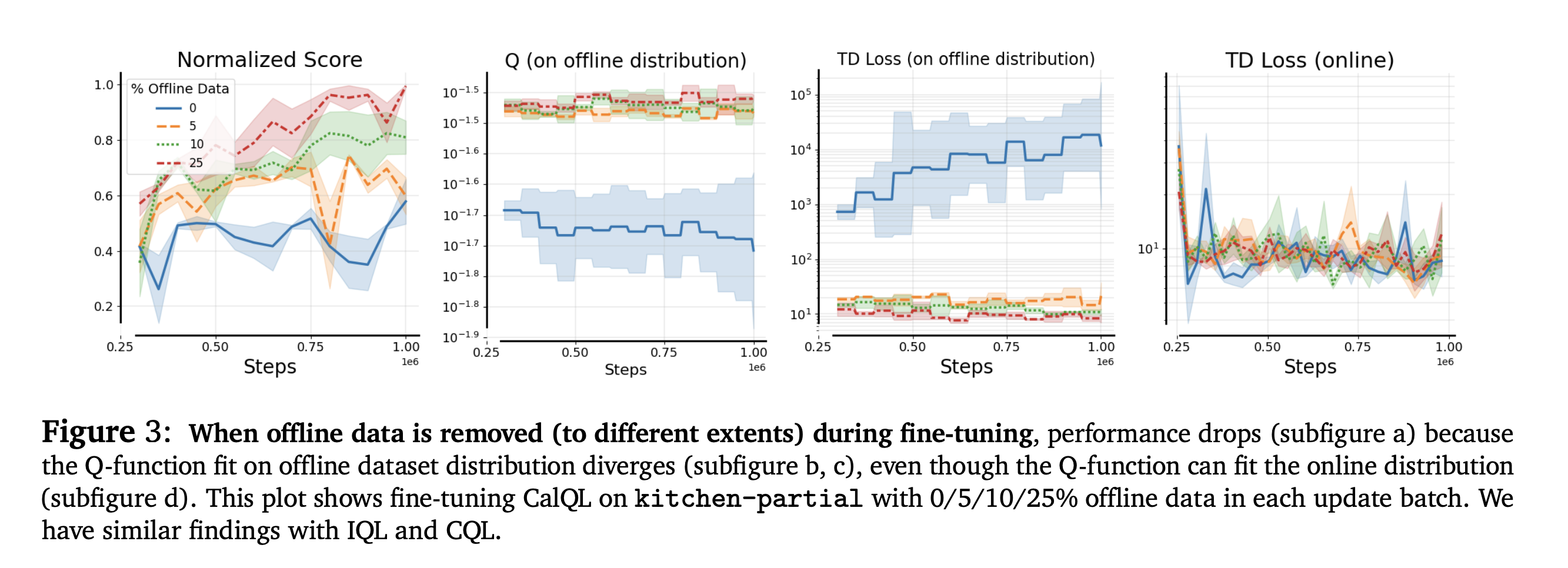
Efficient Online Reinforcement Learning FineTuning Need Not Retain Offline Data
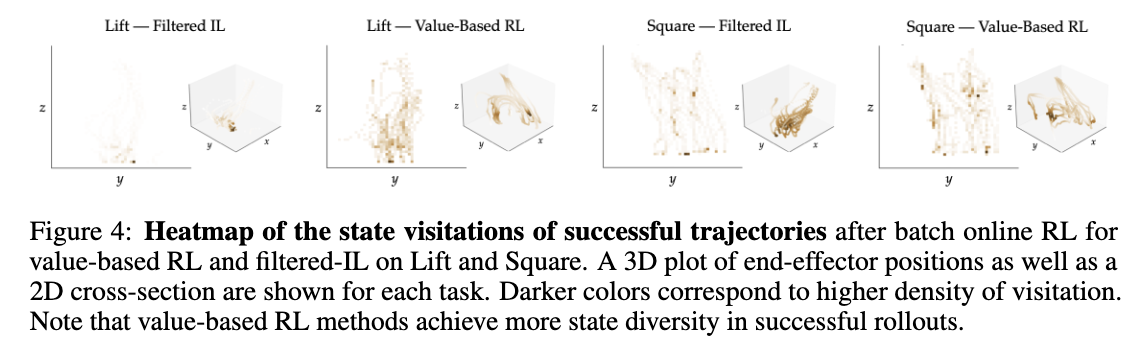
Qualitative Metrics
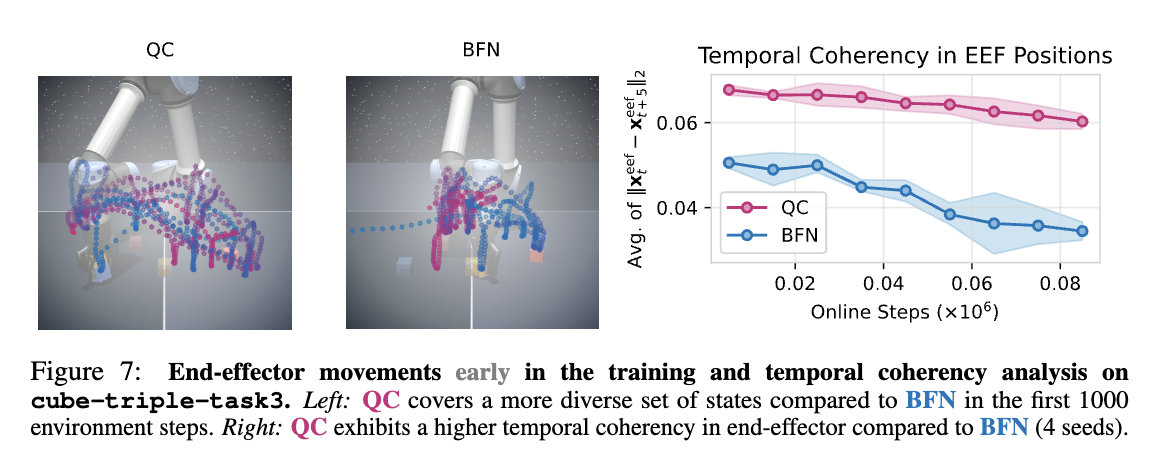
What Matters for Batch Online Reinforcement Learning in Robotics