Reinforcement Learning with Action Chunking (Q-Chunking)
Paper that just came out in jul 2025.
Has an open-source implementation: https://github.com/ColinQiyangLi/qc
“In the adjacent field of imitation learning (IL), a widely used approach in recent years has been to employ action chunking, where instead of training policies to predict a single action based on the state observation from prior data, the policy is instead trained to predict a short sequence of future actions (an “action chunk”) [82, 11]. While a complete explanation for the effectiveness of action chunking in IL remains an open question, its effectiveness can be at least partially ascribed to better handling of non-Markovian behavior in the offline data”.
- The current state does not have enough information
RL is built on the markov assumption, that seems like quite a limitation.
That equation they use is Sarsa, the on-policy implementation of q-learning.
I spent quite a bit of time trying to understand where this RL. The bias comes not from overfitting to a single episode, but from off-policy mismatch and bootstrapping from stale or wrong values. Specifically:
If your policy changes, the tail value may no longer align with the data used.
If you do n-step return naïvely, you’re assuming that the trajectory you’re using is “on-policy” — which often it’s not.
So the bias isn’t from overfitting to the episode’s rewards — those are real. It’s that you’re backing up from a part of the trajectory that might not reflect your current policy.
overestimate values for actions not in the dataset?
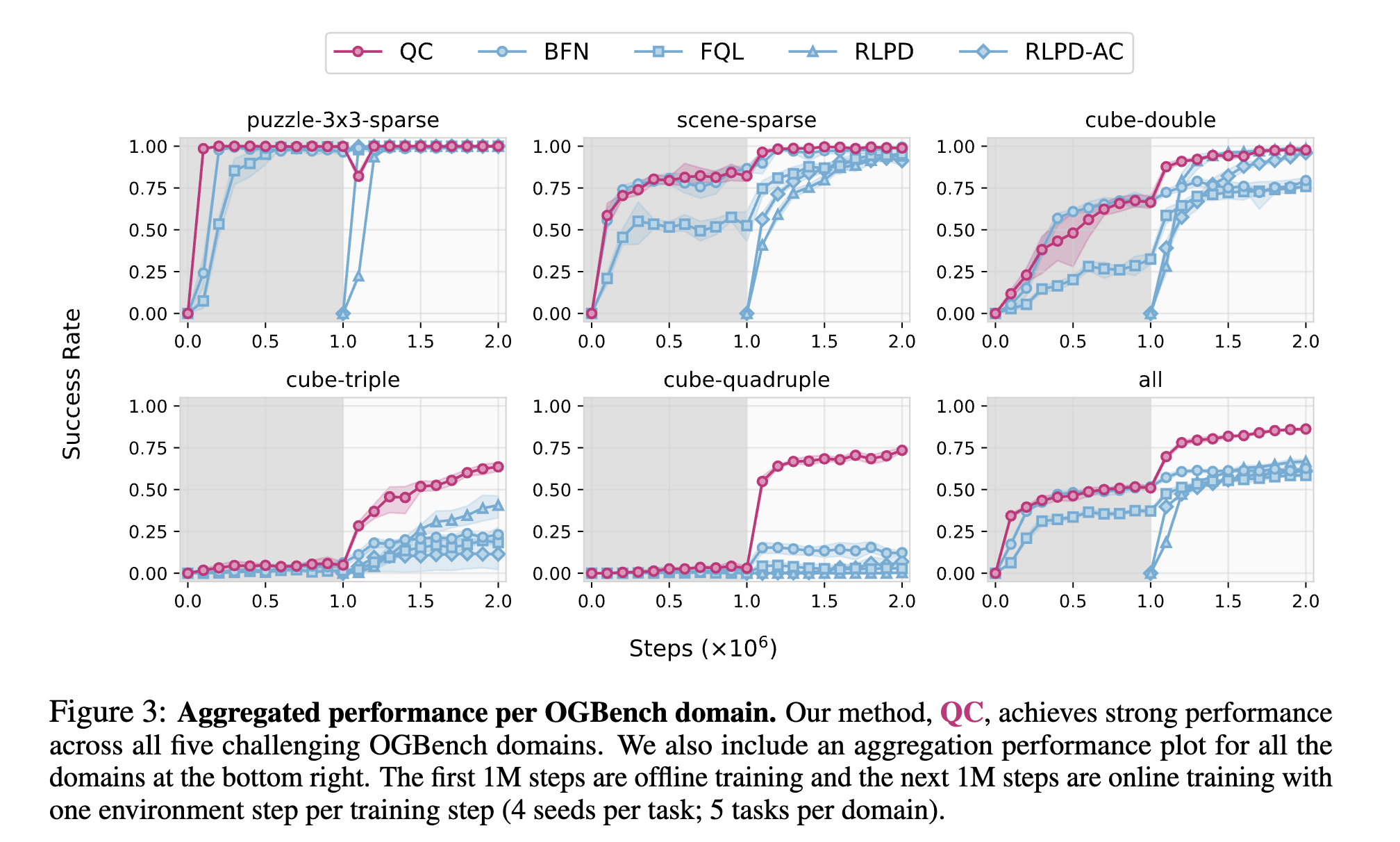
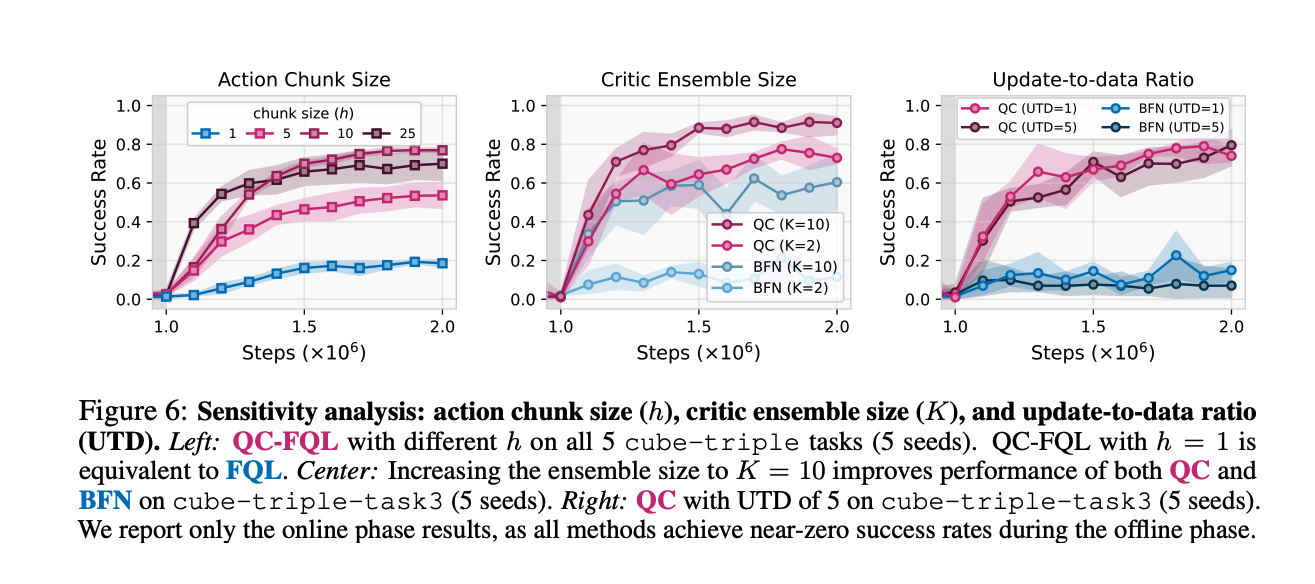
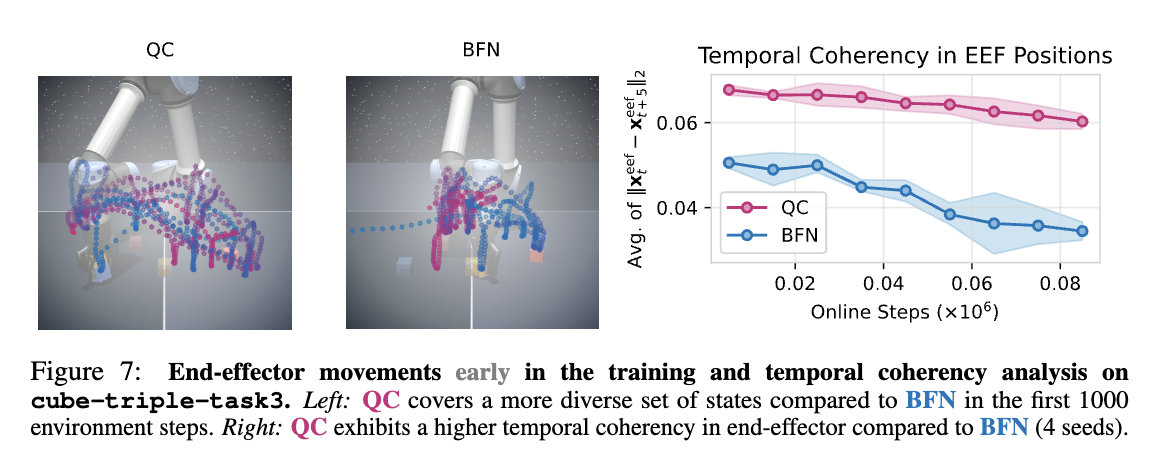
OG bench performance