Masked Autoencoders Are Scalable Vision Learners (MAE)
Actually a very basic idea: in addition to your autoencoder architecture, you’re going to mask a large part of the image, and force the autoencoder to reconstruct the original image.

- In these results, you still see that it’s actually quite blurry, because it sort of learns the mean
Masked autoencoding idea did not come from this paper, it came from BERT in 2018.
How can masked autoencoding work so well without diffusion?
MAEs don’t need to generate an image pixel-by-pixel from pure noise (like diffusion).
They start with a partially observed image: a small set of visible patches already gives a huge amount of structure (object shapes, colors, layout).
The model’s job is to fill in the missing patches so the whole image is coherent — this is a much lower-entropy task than unconditional generation.
They show good scaling properties.
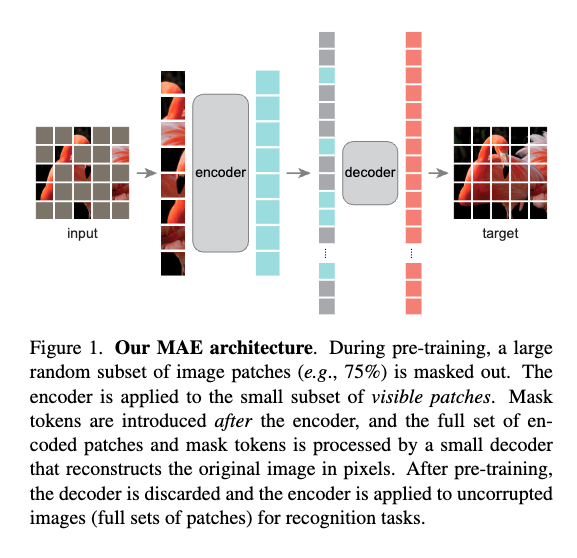
“we mask random patches of the input image and reconstruct the missing pixels”
They found that MAEs encoder without mask tokens does better. Only the decoder will have access to mask tokens:
[!PDF|255, 208, 0] Masked Autoencoders Are Scalable Vision Learners, p.5
(c) Mask token. An encoder without mask to- kens is more accurate and faste
is there a single mask token or multiple mask token, one for each area that can be masked?
Each of those mask tokens is identical (same vector in parameters), but their positional embedding makes them unique.
Walkthrough (CS231n 2025 Lec 12)
Architecture in one pass
- Patchify + mask. Split image into ViT patches (16×16 or 14×14). Randomly drop 75% — the kept 25% is a tiny fraction.
- Encoder on visible only. Feed the 25% kept patches into a ViT without any mask tokens. Encoder has no knowledge of which positions are missing. Runtime scales with kept-count, so 4× cheaper than encoding all patches.
- Decoder with mask tokens. Concatenate encoder output with a set of learnable mask tokens at the masked positions (plus positional embeddings). Lightweight ViT decoder reconstructs pixel values for all patches.
- Loss on masked patches only. MSE in pixel space, restricted to the 75% that were masked. Reconstructing the visible 25% is trivial (identity) and would leak.
Why the design choices matter
- High 75% mask ratio. At BERT’s 15% ratio the task is trivial (neighbors are very informative). At 75% the model has to learn semantic structure. Ablation in the paper shows 75% is the sweet spot for images.
- Encoder without mask tokens. If mask tokens leak into encoder, it wastes capacity learning the bimodal mask-vs-content distribution. Also kills the 4× speedup.
- Asymmetric depth. Decoder is much lighter than encoder. After pretraining throw the decoder away.
- Pixel MSE is fine. Simpler than predicting VQ-VAE tokens (BEiT) and slightly better in their ablation.
Results
- ViT-H at 448 resolution → 87.8% ImageNet top-1 (ImageNet-1K only, no extra data).
- Training 3× faster than supervised ViT-L at the same final accuracy.
- Transfer to COCO detection, ADE20K segmentation — all beat supervised ViT pretraining.
- Linear probing is comparatively weak — features are not aligned to a linear class boundary. Fine-tuning is the right eval for MAE.
Relationship to contrastive methods
MAE and contrastive (SimCLR/MoCo/DINO) are the two dominant non-pretext SSL families. Rough rule from Lec 12:
- Contrastive — strong linear eval (features are globally semantic), needs lots of negatives / careful collapse prevention.
- MAE — weak linear eval, strong fine-tune / dense prediction (features are locally rich, good for detection + segmentation).
Source
CS231n 2025 Lec 12 slides ~50–65 (MAE architecture, 75% masking ablation, asymmetric encoder-decoder, pixel reconstruction results, ViT-H 448 → 87.8%).