Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture (I-JEPA)
I-JEPA = image-based joint-embedding predictive architecture
Invariance-based methods = apply a bunch of augmentations to the original image, and make sure the embeddings generated from those images are very similar (invariant to augmentations)
- This method is highly biased towards the augmentations applied, as the augmentations are hand-crafted. The model’s ability to generalize is not so clear
Generative methods = reconstructing the original image
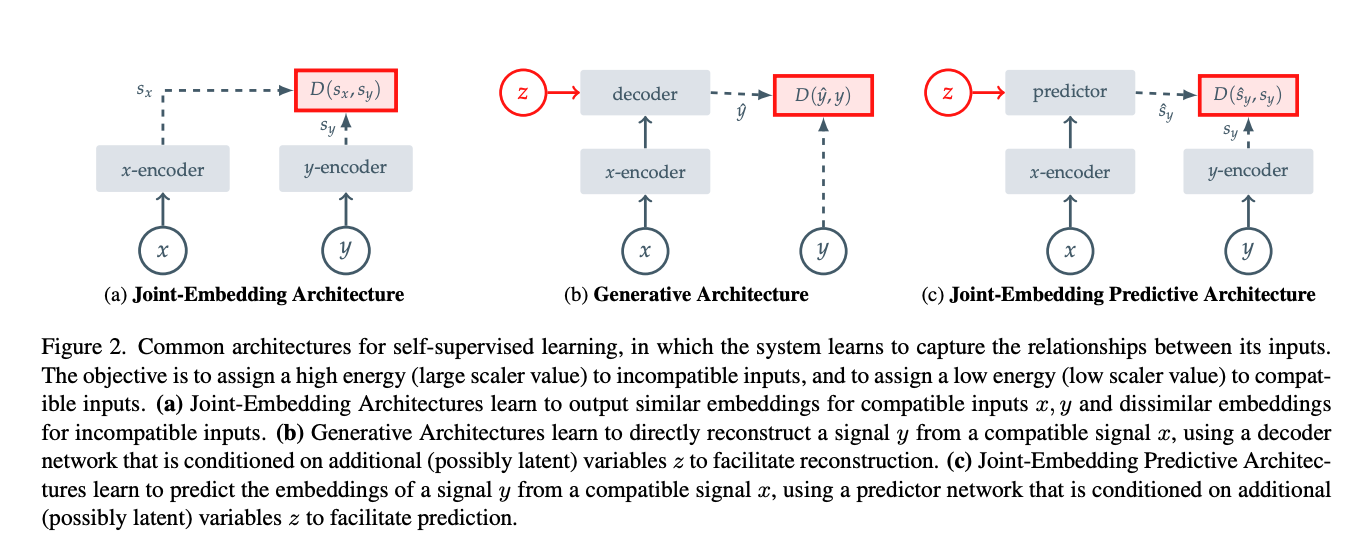
- I was confused about this, since I thought that for generative architecture, we only needed “y”, not “x”?
- They explain it in the paragraph
- The Masked Autoencoder paper is an example of this
Each architecture
- Joint-embedding architecture: A big limitation is representation collapse. Some ways to prevent:
[!PDF|255, 208, 0] SelfSupervised Learning from Images with a JointEmbedding Predictive Architecture, p.13
Collapse-prevention based on architectural constraints leverage specific network design choices to avoid collapse, for example, by stopping the gradient flow in one of the joint- embedding branches [20], using a momentum encoder in one of the joint-embedding branches [35], or using an asymmetric prediction hea
- Generative architecture: x is a copy of y, but with some of the patches masked. z corresponds to a set of mask and position tokens to specific to the decoder which image to reconstruct. Representation collapse is not an issue
- Ex: BERT for text
- Masked Autoencoders Are Scalable Vision Learners for image
- Joint-embedding predictive architecture:
[!PDF|255, 208, 0] SelfSupervised Learning from Images with a JointEmbedding Predictive Architecture, p.3
In contrast to Joint-Embedding Architectures, JEPAs do not seek representations invariant to a set of hand-crafted data augmentations, but instead seek representations that are predictive of each other when conditioned on additional information z.
- still suffer from representation collapse
What's wrong with generative models?
Generative methods learn representations by removing or corrupting parts of the input and then predicting the corrupted content, often at the pixel or token level.
However, the representations resulting from these methods are typically of a lower semantic level. This means they may focus too much on unnecessary pixel-level details, which can hinder the learning of more abstract, high-level features.
- In contrast, the Image-based Joint-Embedding Predictive Architecture (I-JEPA) improves semantic representations by predicting missing information in an abstract representation space, rather than direct pixel or token space. This design choice is crucial, as explicitly predicting in pixel space significantly degrades linear probing performanc
JEPA never tries to reconstruct pixels, nor to model the full joint distribution of natural images. It only tries to predict representations of masked parts of the same image.
Very similar to MAE, except that instead of having the loss on the input space (image pixels), it’s applied on the embedding space.
How does one apply loss on embedding space? The loss is given by
- For target blocks
- is prediction for target block
” we leverage an asymmetric architecture between the x- and y-encoders to avoid representation collapse.”
Applying to ImageNet
They just add a lienar head, i.e. a matrices, so it just mapping fixed features into class logits.