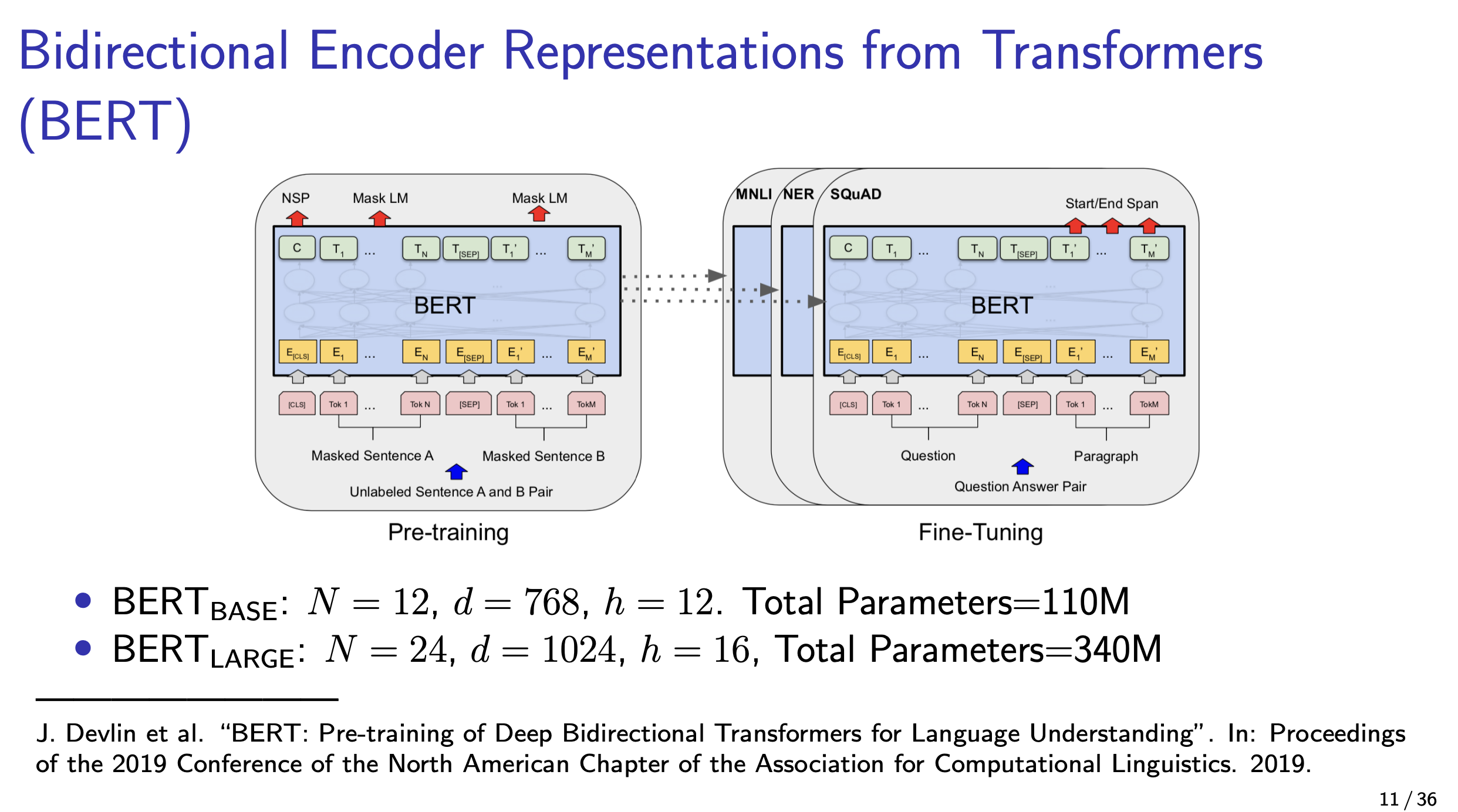
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT = Bidirectional Encoder Representations from Transformers
masked autoencoders presented here?
BERT is a bidirectional Transformer. BERT is not a generative model. It’s an encoder only.
Bert tries to predict the masked token.
They use bidirectional self-attention.
Resources