PaliGemma
pi0 uses this model.
Paligemma takes a pretrained SigLIP image encoder (a ViT) and a pretrained Gemma.
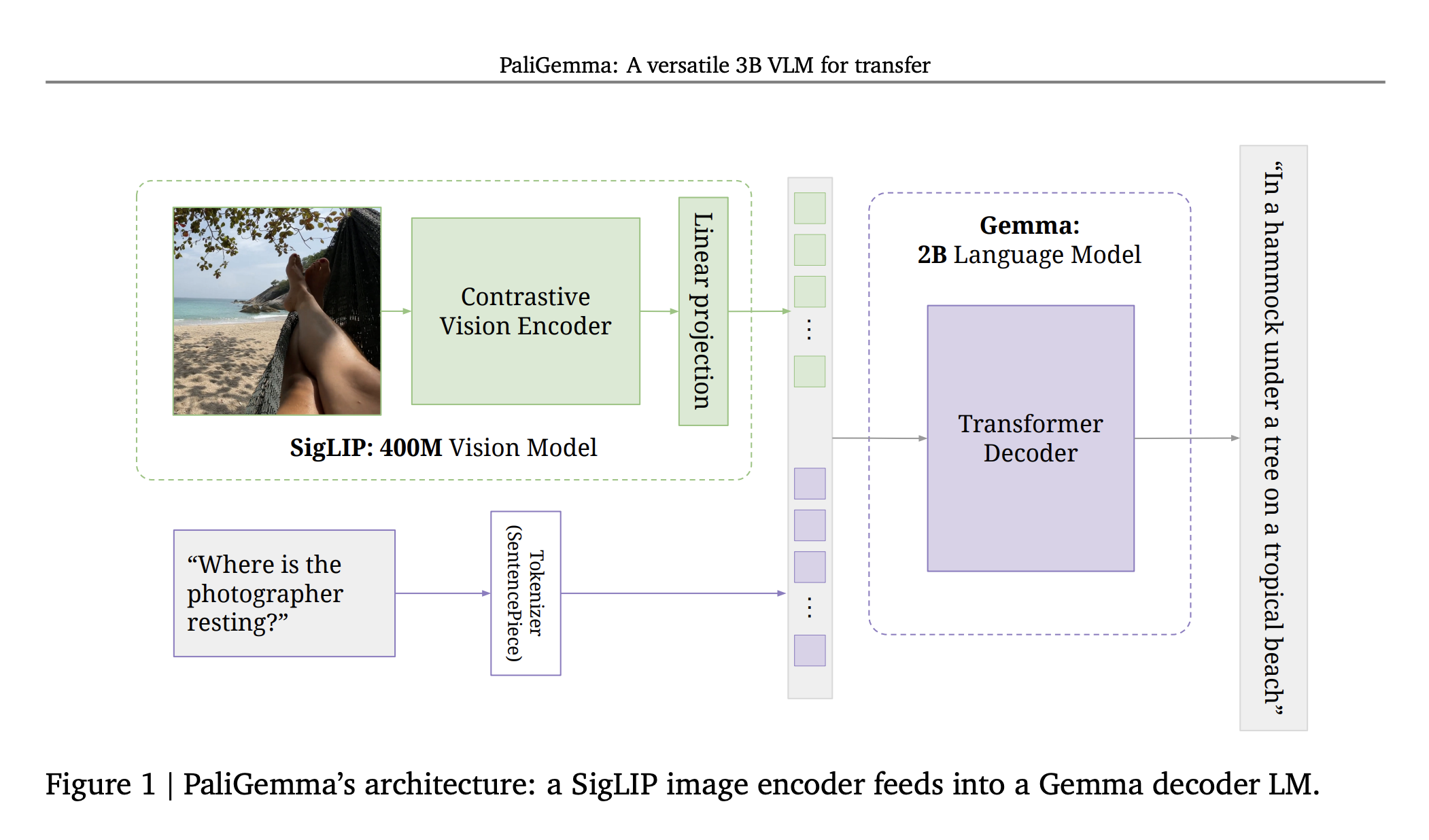
I don’t understand what this contrastive vision encoder refers to?
- It’s just SigLIP
- SigLIP trains both image encoder and text encoder, and uses a contrastive loss to make sure that the image and text are close in terms of embedding. But then with paligemma, it just doesn’t use the text encoder part of SigLIP
Why doesn't PaliGemma use the text encoder too from SigLIP?
Because Gemma was not trained to understand the encoded embeddings from SigLIPs. It already has an embedding table that it understands. The only gap to close is the images, and figure out how to project the image’s embedding into the embedding space of the LLM.