Sigmoid Loss for Language Image Pre-Training (SigLIP)
SigLIP is an improved version of CLIP which introduces sigmoid-based Contrastive Loss instead of the traditional softmax-based contrastive loss used in CLIP.
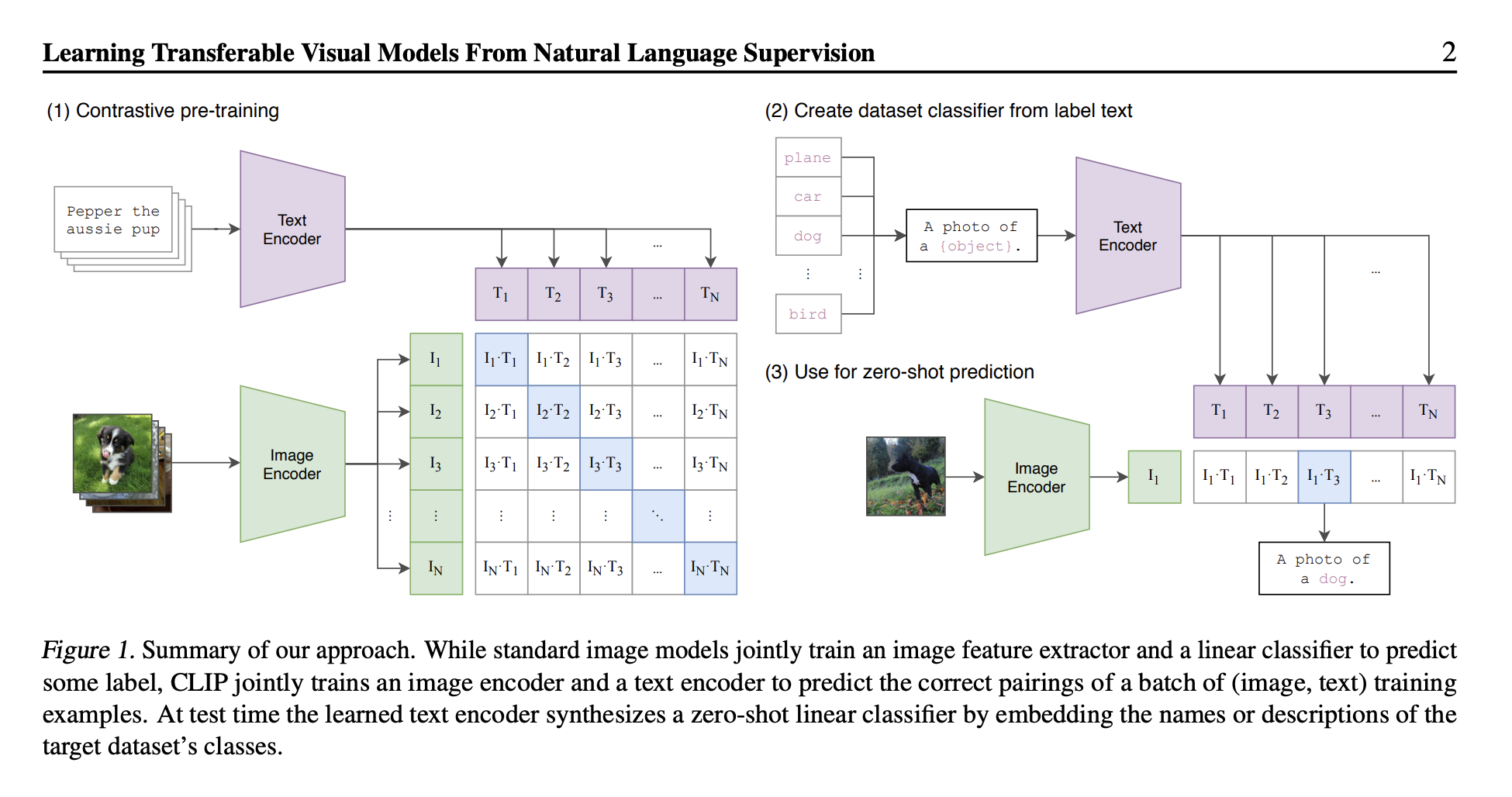
- From CLIP
Implementation details:
- Image Encoder is implemented with a Vision Transformer
- Text Encoder is implemented with a Transformer
- Sigmoid-based Contrastive Loss.
It uses separate image and text encoders to generate representations for both modalities.
![]()
Resources