Revisiting Feature Prediction for Learning Visual Representations from Video (V-JEPA)
No use of pre-training. Why don’t you believe in the power of pre-training? This is more to show that we need better architecture for better representation learning than auto-regressive models.
Pre-trained on 2 million videos (referred as VideoMix2M), which combines:
- HowTo100M (HT) (Miech et al.,2019),
- Kinetics-400/600/700 (K710) (Kay et al., 2017),
- Something-Something-v2 (SSv2) (Goyal et al., 2017), removes overlap with validation set of Kinetics-400/600/700 and Something-Something-v2.
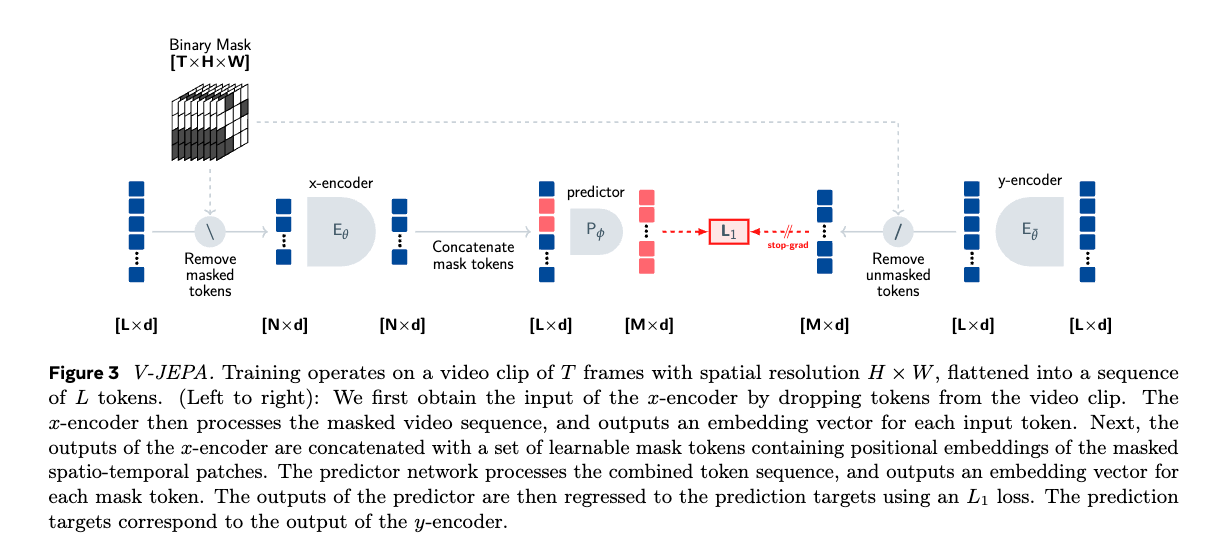
Loss Objective
They talk about mode collapse if we just use the naive regression objective
- is the encoder network
- is the predictor network
So they use a stop-gradient operation:
- is an EMA of the x-encoder’s weights
- is a learnable mask token that indicates the locations of the dropped patches
Video benchmarks
Image benchmarks