Bootstrap your own latent: A new approach to self-supervised Learning (BYOL)
Seems like quite an important paper that V-JEPA mentions for preventing mode collapse.
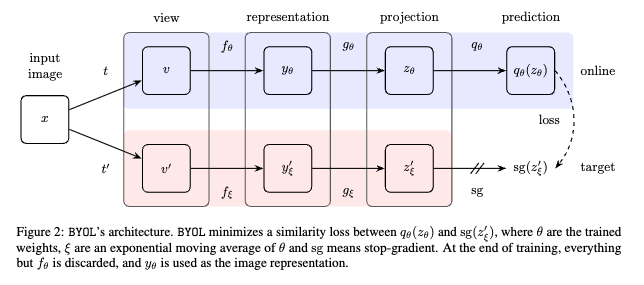
where:
- , are representations from the online encoder given two augmentations of the same image,
- , are representations from the target encoder (parameters updated via EMA),
- is the predictor head on the online branch,
- means stop-gradient (no gradients flow into the target encoder),
- is the squared distance (MSE).
Intuition
Each online view predicts the target’s representation of the other view. No negatives are involved, collapse is prevented by stop-grad + predictor + momentum target.