Hashing
Hash functions accept a key and return an output unique only to that specific key.
- This is known as hashing, which is the concept that an input and an output have a one-to-one correspondence to map information.
- Hash functions return a unique address in memory for that data.
A hash function takes a key value and calculates a valid bucket index. We want to use hashing to get constant operation time . However, there might be a Hash Collision.
I finally learned this a little more seriously in CS240.
Formalization in CS240
Define all keys to come from some universe . (Typically U = non-negative integers, sometimes |U| finite.)
- We design a hash function . (Commonly used: . We will see other choices later.)
- Store dictionary in hash table, i.e., an array of size .
- An item with key should ideally be stored in slot , i.e., at .
Implementing Hashing
There are two main ways to implement hashing:
- Use Chaining (it’s basically a linked list)
- Use Open Addressing
1. Open Hashing with Chaining
With open hashing, each bucket holds a pointer to a list rather an element. So it’s basically like a Linked List.
2. Closed Hashing with Open Addressing
Closed hashing uses a hash table with buckets. Contrary to open hashing, we avoid the links needed for chaining by permitting only one item per slot, but allowing a key to be in multiple slots.
Typically, with closed hashing, you allocate space for all of the table entries in the table itself at the beginning. As we add more and more data entries, it becomes harder and harder to find an empty slot.
Linear probing means keep adding one to the index () and check again.
Load factor should be less than 80% to be efficient.
The average bucket-size is ( is called the load factor.)

Important characteristics of Hash Function
- Deterministic, based on key value
- Good spread of results over buckets (“uniformity”)
- Cheap to compute
- Supports a variable range
Think of an analogy to this image:
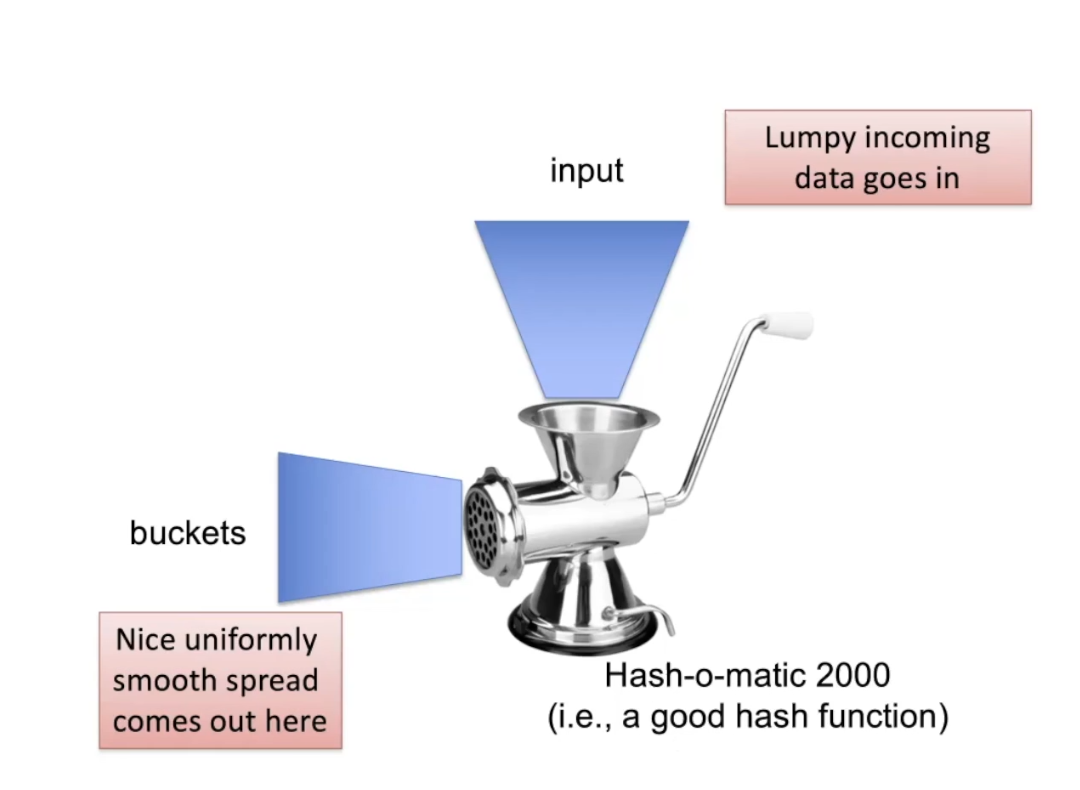
Why isn't a hash function where you simply take the modulus good enough?
Consider the input and your hash function is (hash table of size 10). You run into lots of hash collisions even though your input is uniformly distributed.