Optimal Value Function
- The optimal value function specifies the best possible performance in the MDP.
- An MDP is “solved” when we know the optimal value function
Definition
The optimal state-value function is the maximum value function over all policies for all
The optimal action-value function is the maximum action-value function over all policies
It is very similar to the original Value Function, but rather than taking the expected values given some policy, we simply take the maximum of the values over our choices.
Backup Diagrams for and
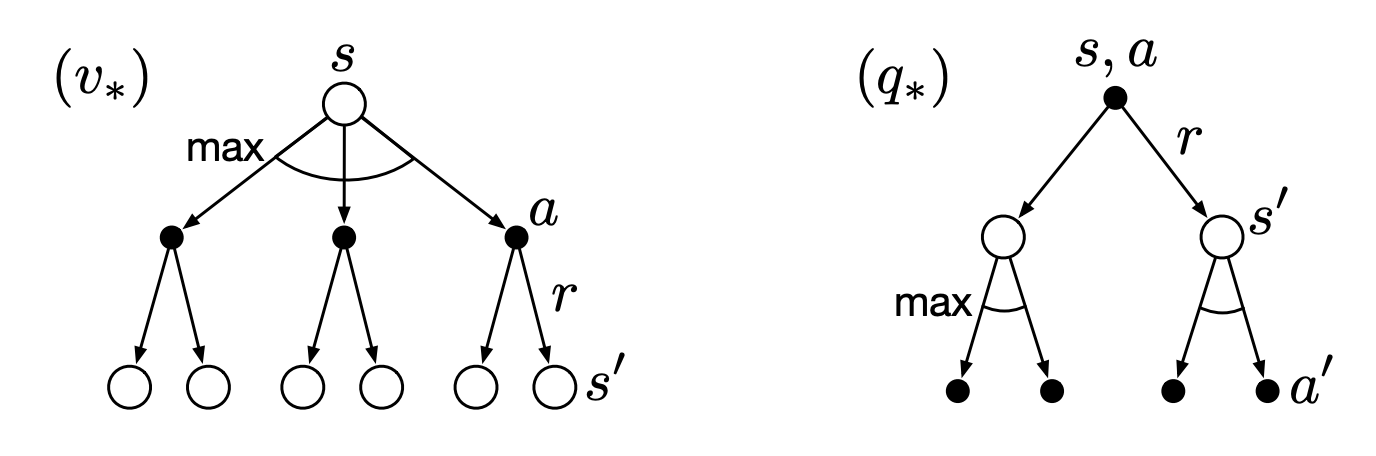 Optimal State-Value Function
Optimal State-Value Function
Optimal Action-Value function IMPORTANT: We are taking the average for and not the max, because we cannot control what the environment does to us
Closely related to Optimal Policy. They are solved using Optimal Policy. They are solved using Bellman Equation.