Bellman Equation
The bellman equation relates the value of a current state with the value of successive states.
This is the fundamental idea: All of value-learning based RL bases off the above equation.
Bellman Expectation and Bellman Optimality
We have bellman expectation (used in Policy Evaluation) which defines the expected value of a state relating to successor states.
We have bellman optimality (used in Policy Improvement), which defines how the optimal value of a state is related to the optimal value of successor states.
IMPORTANT
Make sure to understand the difference between the bellman expectation backup and bellman optimality backup. This is fundamental in RL:
- The bellman expectation to get the expected values of a particular policy
- The bellman optimality to get the optimal value function (these values are obtained if we can somehow find an optimal policy )
Visualizing the Bellman Update
These are taken from the RL textbook, and use lowercase and as opposed to and , but they refer to the same thing.
With the value function, the probability (weight of each edge) is given by the policy, we decide that. Below are called Backup Diagram:
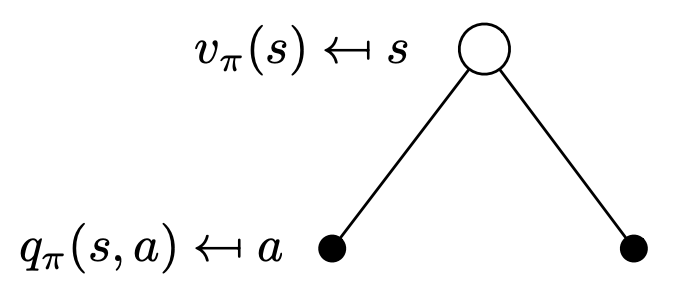 On the other hand, for the q-value (i.e. after we have done an action), this is what we do with the environment. After choosing an action, we get a reward, and the probability of landing into new states are given by our environment. We also apply the Discount Factor here.
On the other hand, for the q-value (i.e. after we have done an action), this is what we do with the environment. After choosing an action, we get a reward, and the probability of landing into new states are given by our environment. We also apply the Discount Factor here.
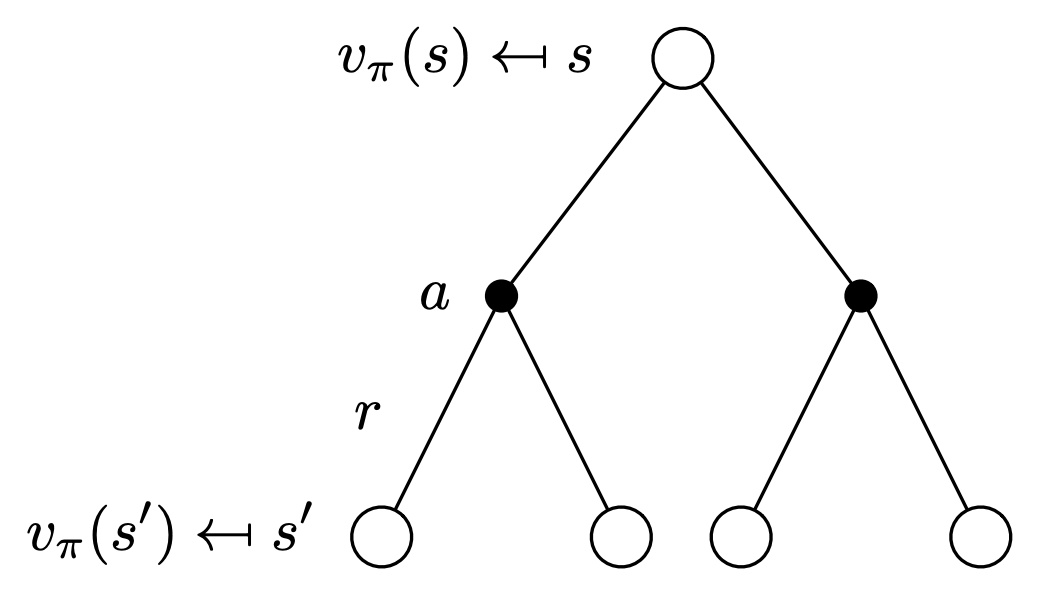
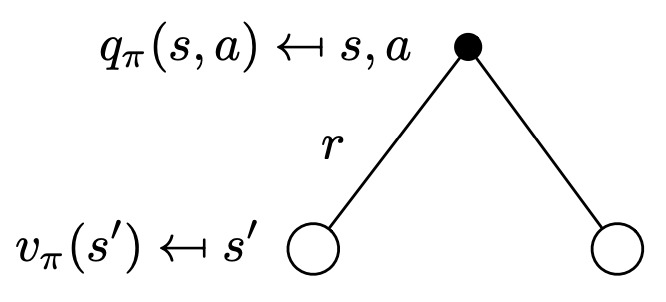 So now, we can have a recursive relationship.
So now, we can have a recursive relationship.
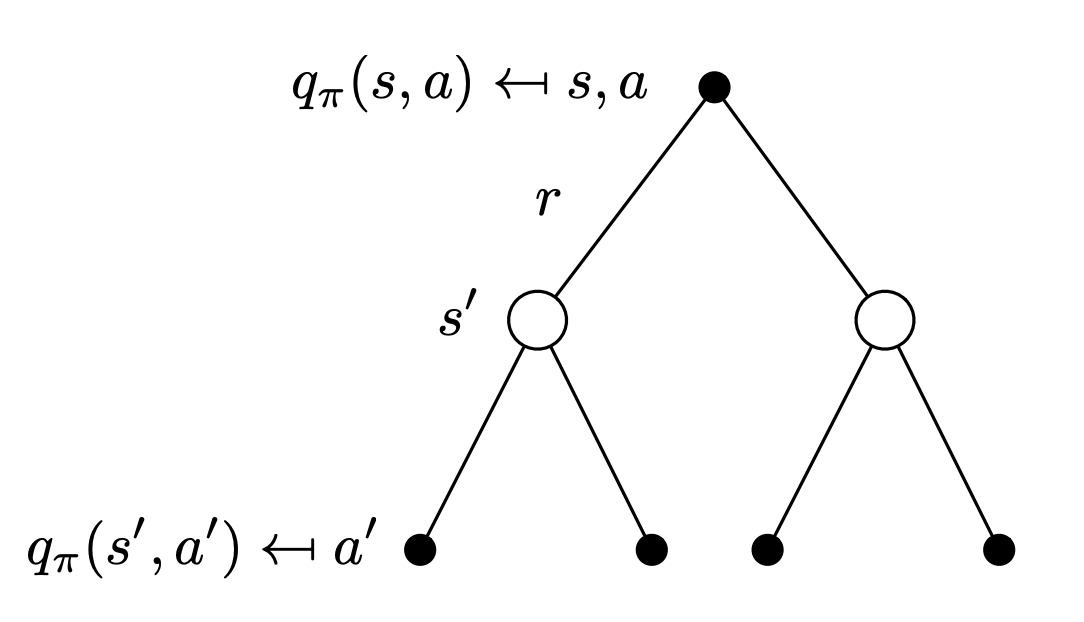
#gap-in-knowledge review david silver lectures, I don’t understand the big picture, why does a 1-step lookahead give you the optimal policy? Page 86 of RL book
- Because of GLIE, the backup structure and GLIE together ensure convergence to optimality
A greedy policy is actually optimal in the long-term sense in which we are interested because already takes into account the reward consequences of all possible future behavior.
By means of , the optimal expected long-term return is turned into a quantity that is locally and immediately available for each state. Hence, a one-step-ahead search yields the long-term optimal actions.
Solving the Bellman Optimality Equation
Bellman Optimality Equation is non-linear. There are No closed form solution.
Instead, there are many iterative solution methods: