Pitch Linear Memory Layout (PL)
Pitch Linear Memory Layout (PL) represents a specialized approach to arranging two-dimensional (2D) data within a linear memory space.
It is an extension of the Flat Memory Model that adds padding to ensure correct row-major access in a 2D array.
It Calculates linear memory allocation based on provided 2D sizes, including necessary padding.
I saw that the acronym for this is PL in VPI. Pitch memory layout is when you call CudaMallocPitch, which ensures memory alignment by adding padding.
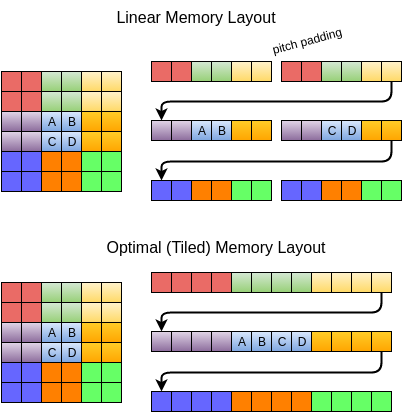
There is no block height in pitch surfaces. It is simple pitch storage format.
For block linear surfaces, depends on the architecture, it will have a different vertical arrangement.
Resources
- https://docs.nvidia.com/vpi/ImageFormat_8h_source.html
- https://forums.developer.nvidia.com/t/whats-the-difference-between-layout-pitch-and-layout-blocklinear/54272
CudaMallocPitch
Guarantees alignment with 2D arrays.
Source: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#device-memory
// Host code
int width = 64, height = 64;
float* devPtr;
size_t pitch;
cudaMallocPitch(&devPtr, &pitch,
width * sizeof(float), height);
MyKernel<<<100, 512>>>(devPtr, pitch, width, height);
// Device code
__global__ void MyKernel(float* devPtr,
size_t pitch, int width, int height)
{
for (int r = 0; r < height; ++r) {
float* row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; ++c) {
float element = row[c];
}
}
}