Memory Alignment
https://stackoverflow.com/questions/1063809/aligned-and-unaligned-memory-accesses
Resources
You will hear these different terminologies:
- Byte Aligned
- Word Aligned
- Memory Aligned
There is also DRAM Bursting.
- In actual 32-bit architecture, because words are aligned to multiples of four byte
- In 64-bit architecture, where there are 8 bytes per word, we use 3 bits for the byte offset, this is used to index into the right byte
Memory Alignment example
https://x.com/seatedro/status/1874668513719464056/photo/1
- This is bad for example, because you would need to read the struct 3 times, as opposed to twice if you had written it
That’s badly explained.
A Struct is just a combination of different primary data types.
What are the alignment requirements?
The overall alignment of the struct is determined by its largest-aligned member. Since long long b requires 8-byte alignment, the entire struct must be aligned to 8 bytes.
- Why? We expect types to be at addresses of multiples of its size (ex: long long to be at addresses of multiples of 8).
For the member fields, alignment rules are the same.
But why is it this way?
Why is this memory alignment needed? Why can’t the CPU just directly read off memory address 0x…1 for example? Like our programs are capable of Byte Addressing, so I don’t see why the hardware can’t do it.
- See this stackoverflow for an answer, basically our CPUs are optimized to read off byte aligned data, also this
- The CPU always reads at its word size (4 bytes on a 32-bit processor), so when you do an unaligned address access — on a processor that supports it — the processor is going to read multiple words.
- Cache Line
- The real killer: arrays of structs
The biggest practical reason is arrays.
“The better question would be to not tell them that anything is wrong, rather ask them what the size of this struct is in memory, whether or not it is possible to reduce its memory footprint, if possible how can you reduce the memory footprint of the struct, and the performance implications alignment has when it comes to program execution”
The rule
For a type
T, it’s start address must be a multiple ofsizeof(T).
Alignment rules:
- u32 is 4-byte aligned, so it starts at addresses divisible by 4 (e.g., 0, 4, 8,…)
- u64 is 8-byte aligned, so it starts at addresses divisible by 8 (e.g., 0, 8, 16,…)
- More generally, for a type
T, it’s start address must be divisible bysizeof(T)
Question
Each primitive data type has an alignment requirement that ensures efficient memory access.
- u8 (char) 1-byte alignment (any address)
- u16 (short) 2-byte alignment (divisible by 2)
- u32 (int, float) 4-byte alignment (divisible by 4)
- u64 (long long, double) 8-byte alignment (divisible by 8)
// BAD
struct foo {
int a; // offset 0
long long b; // offset 8
int c; // offset 16
}
sizeof(foo) == 24 // 24 because it must be a multiple of 8
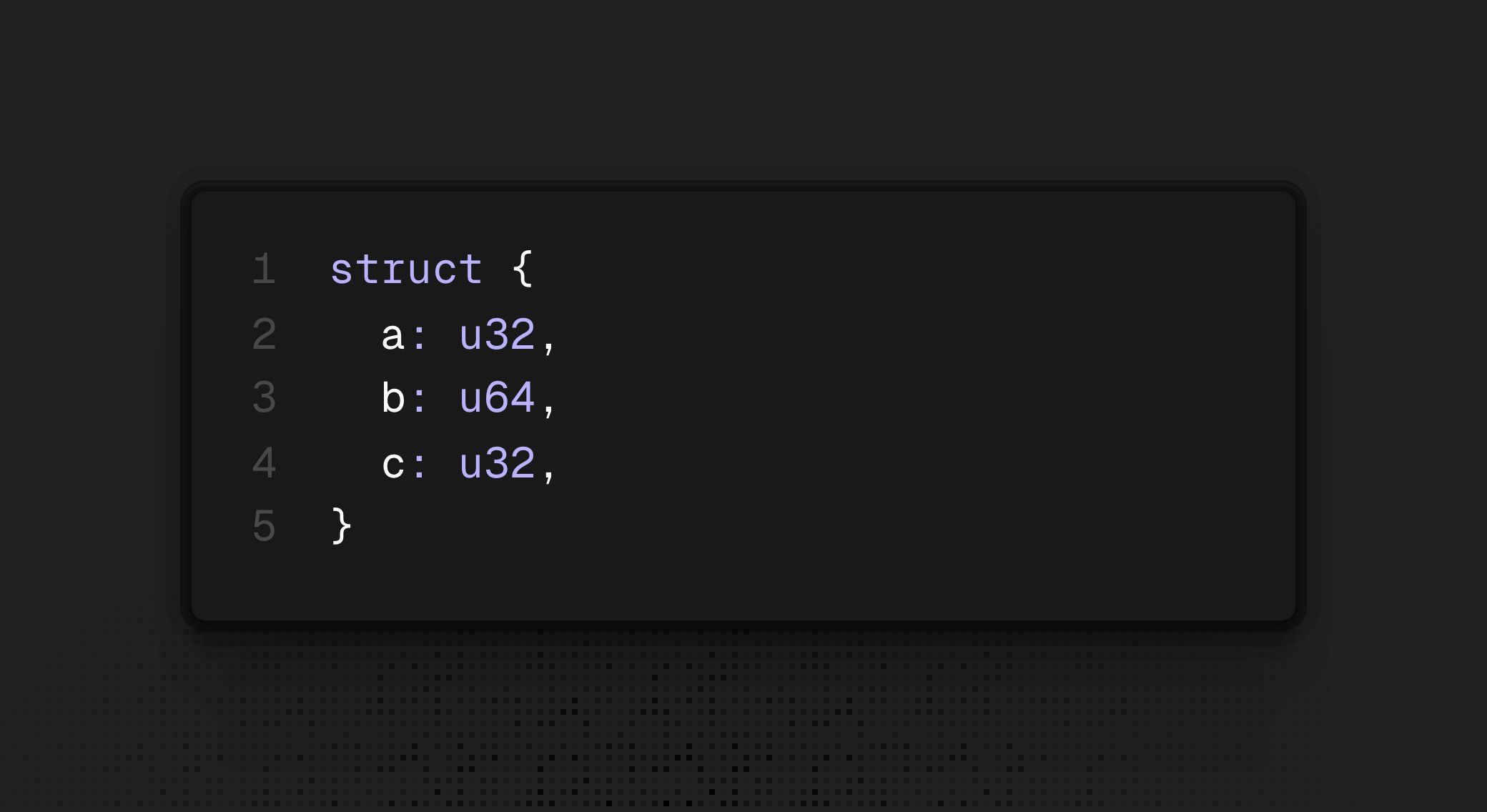
// GOOD
struct {
int a;
int c;
long long b;
}
sizeof(foo) == 16Another example
- From this document https://federico-busato.github.io/Modern-CPP-Programming/htmls/23.Optimization_II.html
// BAD
struct A {
char x1; // [0, 1)
double y1; // [8, 16), since double is 4-byte aligned
char x2; // [16, 17)
double y2; // [24, 32)
char x3; // [32, 33)
double y3; // [40, 48)
char x4; // [48, 49)
double y4; // [56, 64)
char x5; // [64, 65)
}; // sizeof(A) == 72 (because must be a multiple of largest type to be aligned)
// GOOD
struct B {
char x1; // [0,1)
char x2; // [1,2)
char x3; // [2,3)
char x4; // [3,4)
char x5; // [4,5)
double y1; // [8,16)
double y2; // [16,24)
double y3; // [24,32)
double y4; // [32,40)
}; // sizeof(B) == 40What about nested structs?
struct Inner {
char a; // [0,1)
int b; // [4, 8)
}; // sizeof(Inner) == 8
struct Outer {
char a; // [0, 1)
Inner inner; // [4, 12), NOT [8,16)
}; // sizeof(Outer) == 12
int main() {
static_assert(sizeof(Inner) == 8);
static_assert(sizeof(Outer) == 12);
}When you have nested structs
The behavior works as if though the members of the struct are expanded. Even though
sizeof(Inner) == 8, any struct that hasInneras a member doesn’t automatically now have to require 8-byte alignment.