Redundant Array of Inexpensive Disks (RAID)
RAID is an organization of disks that uses an array of small and inexpensive disks so as to increase both performance and reliability.
The motivation of having arrays of disks is to have faster I/O (so higher throughput), since you have more read heads. The effort Parallelizing also needs to be spent both on I/O and computation.
- The idea is that using many disks in conjunction can offer much higher throughput.
However, small disks have worse reliability because they are cheap (lower MTTF ratings). So we need to add Redundancy, which is what are Redundant Array of Inexpensive Disks (RAID).
The ones that are actually used...
Of the seven RAID levels described, only four are commonly used: RAID levels 0, 1, 5, and 6.
Their main use today is Redundancy.
So the question is, how much redundancy do you need? There are several stages of redundancy.
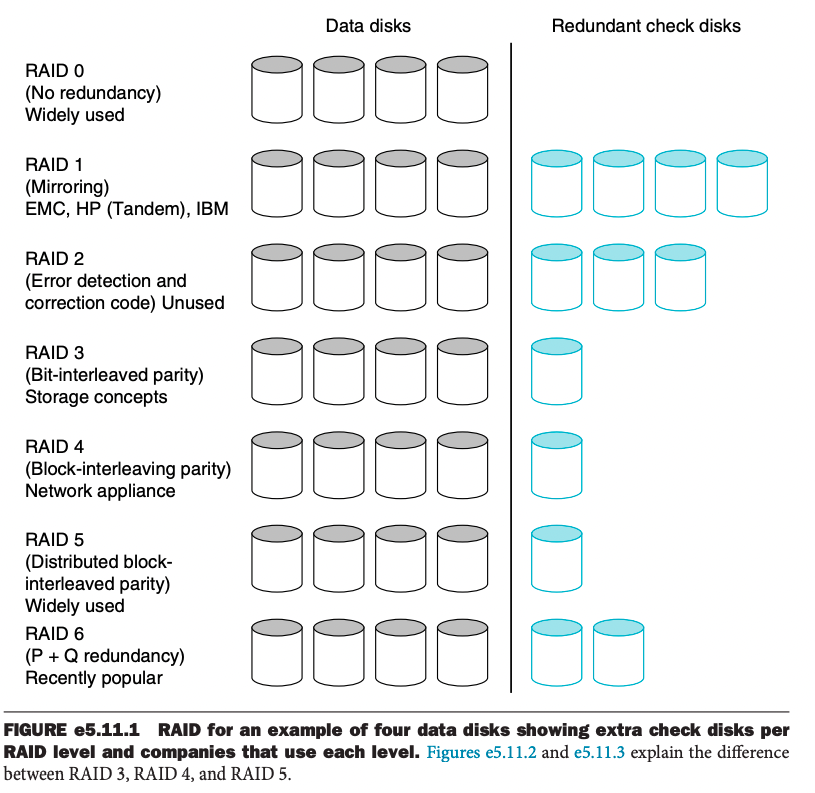
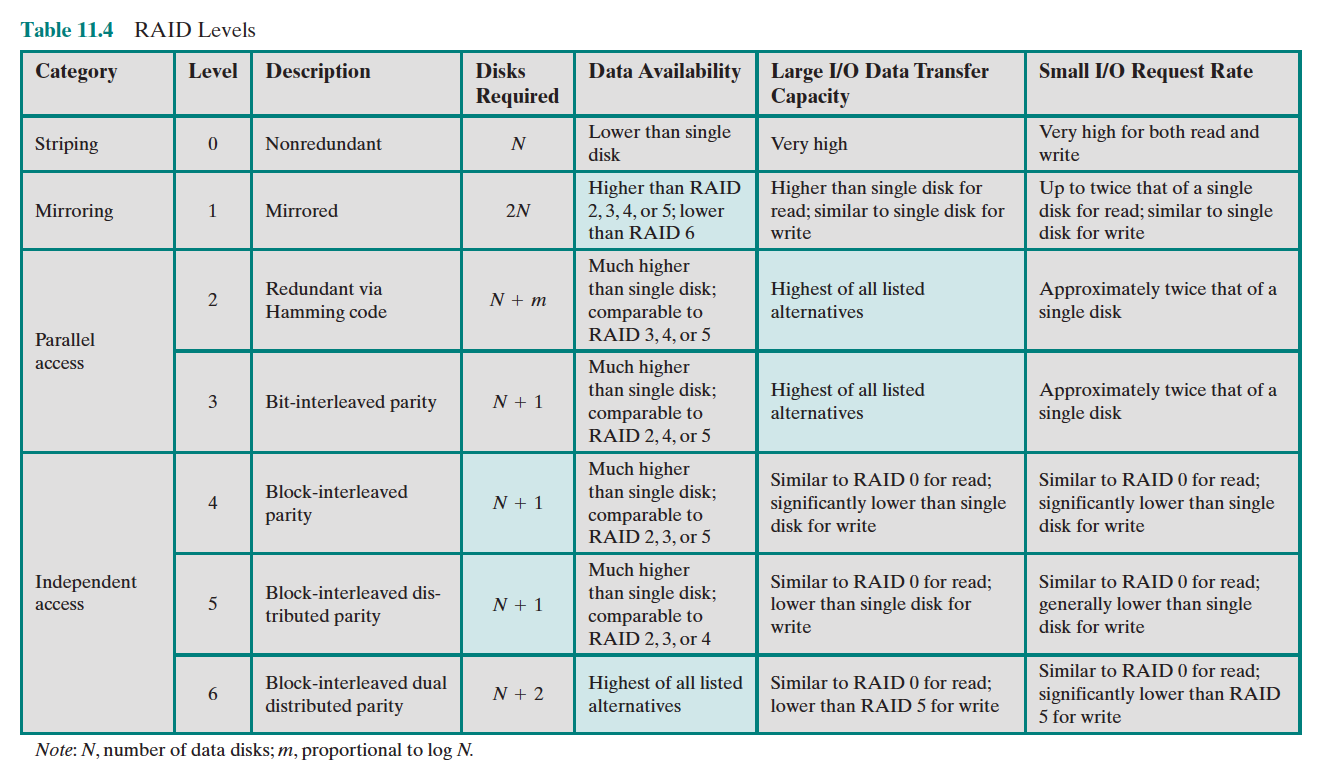
Parity disk = redundant disk
- No Redundancy (RAID 0)
- There is no redundancy
- Implements Data Striping. This automatically forces accesses to several disks.
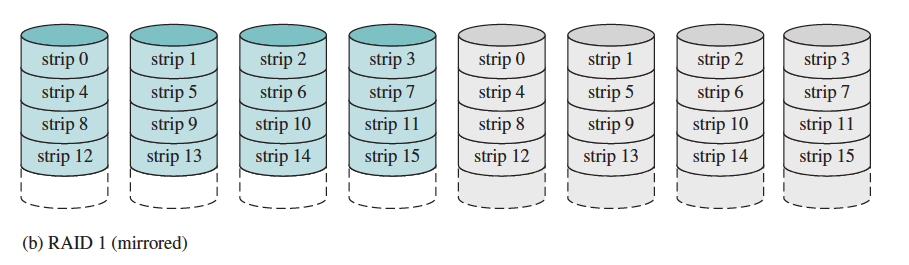
- Mirroring (RAID 1)
- Mirroring is writing identical data to multiple disks to increase data availability.
- Uses twice as many disks as does RAID 0.
- Whenever data are written to one disk, that data are also written to a redundant disk, so that there are always two copies of the information
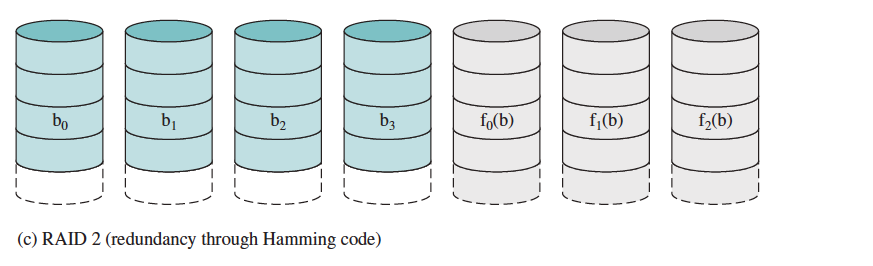
- Error Detecting and Correcting Code (RAID 2)
- Not in use anymore, redundancy through Hamming Code
- Bit-Interleaved Parity (RAID 3)
- We can reduce the cost to 1/n, where n is the number of disks in a protection group. Rather than have a complete copy of the original data for each disk, we need only add enough redundant information to restore the lost information on a failure
- Block-Interleaved Parity (RAID 4)
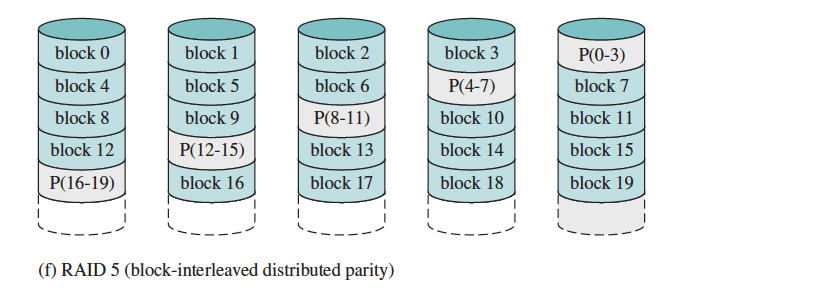
- Distributed Block-Interleaved Parity (RAID 5)
- Improvement over RAID 4 by getting rid of the bottleneck.
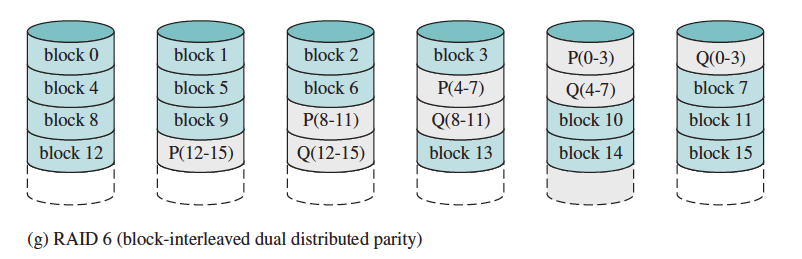
- P + Q Redundancy (RAID 6)
RAID 1 and RAID 5 are widely used in servers; one estimate is that 80% of disks in servers are found in a RAID organization.