Sensor Fusion
I found this paper. https://github.com/TUMFTM/CameraRadarFusionNet
Sensor Fusion is combining two or more data sources in a way that generates a better understanding of the system.
| Factors | Camera | LiDAR | Radar |
|---|---|---|---|
| Range | ~ | ~ | |
| Resolution | ~ | ||
| Distance Accuracy | ~ | ||
| Velocity | ~ | ||
| Color Perception (e.g. traffic lights) | |||
| Object Detection | ~ | ||
| Object Classification | ~ | ||
| Lane Detection | |||
| Obstacle Edge Detection | |||
| Illumination Conditions | |||
| Weather Conditions | ~ | ||
| Source: Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review |
Videos
Personal Thoughts about challenges:
- Creating the ground truth labels for multi-modalities is super expensive. I guess we can get these in simulation. Whatever modality works the best is good.
For low-level fusion,
Geometric Fusion
- Input Fusion
- Map input to 2D or 3D
- Feed into a NN
- Late Fusion
- Extra features from both modalities
- Map features in 2D or 3D
- Feed into a NN
- Feature dimension is lower than input dimension
Neural Fusion
- Option 1: Concat extracted features directly
- Option 2: Use attention to align features rather than geometry
The problems:
- Many lidar points correspond to the same pixel
- many pixels correspond to the same lidar point
- Some measurements in one input is not visible in the other one
- Geometry doesn’t work perfectly
- There is random and different augmentation of input modalities
To continue watching: https://www.youtube.com/watch?v=hkt-JGJx860&ab_channel=IFMLab at 41:38
Types of Fusion
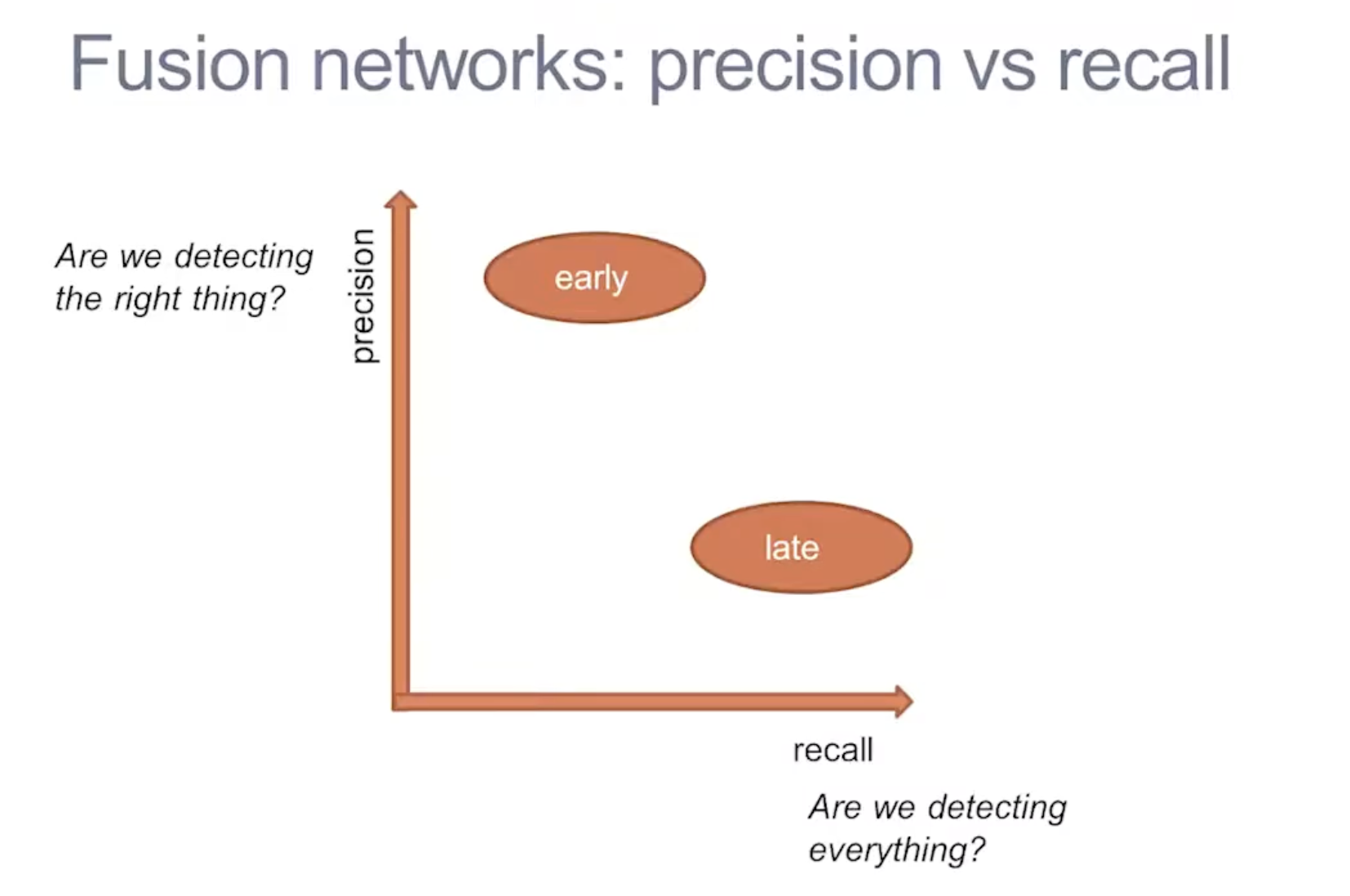
- Early Fusion/Low-Level Fusion (LLF) (fusing raw data)
- Combine the signals then learn a single predictor. However, this method is more difficult to exploit the specific properties of each sensor
- Late Fusion/High-Level Fusion (HLF) (fusing objects)
- Each sensor is processed independently, and the resulting feature maps are combined into one
- A classifier produces a prediction from this hybrid map
- Feature-Level Fusion/Mid-Level Fusion (MLF)
- Build some intermediate representations and learn a predictor
- Intermediate feature maps are generated from each sensor and then a new CNN branch generates prediction
- Difficult to train, since there are lots of parameters, and back-propagation is done in two directions. Uses the idea of Bird-Eyes View
- MLF appears to be insufficient to achieve a SAE Level 4 or Level 5 AD system due to its limited sense of the environment and loss of contextual information
- Sequential (Progressive) Fusion
- Use signals one after the other to obtain a prediction
- Ex: FrustumNet, using frustrums
DeepFusion
Imagine 2d vision: 100x100 = 10,000 dims
- Dense information
Working in 3d vision is extremely sparse. you have 100x100x100 = 1,000,000 dims
- Sparse information
https://www.youtube.com/watch?v=hkt-JGJx860&ab_channel=IFMLab