WATonomous Perception
Also see WATonomous Cheatsheet.
TODO: get in touch with Aryan
Perception will do all of the following (taken from Multi-Task Learning):
- Object Detection
- Traffic Signs (usually from HD Map)
- Traffic Lights (usually from HD Map)
- Cars
- What velocity is it moving at? Is it static or moving?
- Left blinker or right blinker on? to help predict other vehicle’s trajectories
- What kind of car? most important is emergency Vehicle (Ambulance) since we need to yield to them, CARLA AD Challenge has a punishment of
0.7for not yielding - Other lower priority: Is the car’s door open or closed?
- Traffic Cones
- Pedestrians, see what Zoox can do
- Are they looking at their phone? Are they paying attention to the road? Are they walking or standing still? (action classification) What kind of human (children, adult, senior)?
- Road Markings (usually from HD Map)
- Semantic Segmentation
- Which parts of the road is drivable? (usually from HD Map)
- Where are the lane lines?
- Where are the road curbs?
- Where are the crosswalks?
- Which parts of the road is drivable? (usually from HD Map)
Implementation
This is where we want to work towards by end of Apr 2024.
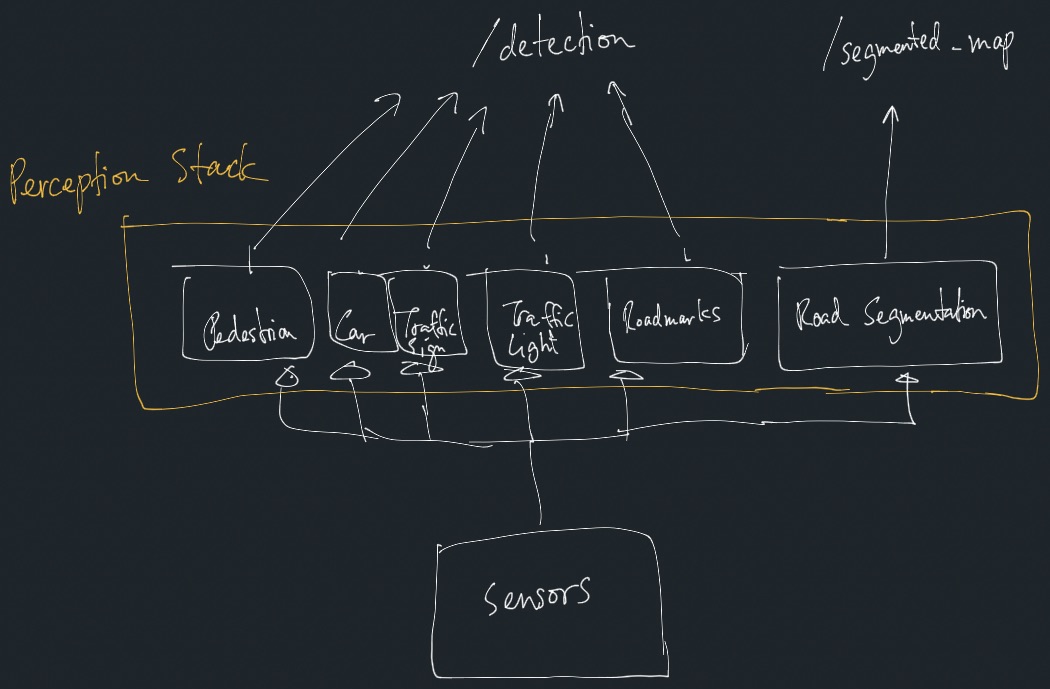
Obstacle vs. detection: I think it doesn’t make sense to categorize between obstacle vs. non-obstacle. Semantically, for the model that we train, it is just a “detection”.
Other things to think about
- Predictions in what Coordinate Frame? Is perception, or later in the stack supposed to take care of this. What reference frames?
- You are assuming that you have a single sensor coming in. What happens when you have mutliple camera? Look at Self-Driving Car Companies
- Robustness of predictions?
- How are you gonna do Multi-Task Learning with all these sensors?
- More channeled ROS2 topics? Right now, I’m thinking of putting all the relevant info into
string label
Future directions / for people who want to read papers and not code as much
This is interesting work. But arguably not as high priority.
- ONNX,
- Bird-eye view things
- 2D / 3D Occupancy Grid
- Using LSTM so the car has a concept of time
- (Research-focused): Domain Adaptation / Transfer Learning / Sim2Real “generalize to the real-world”
- Object Tracking (to be completed once Object Detection is done. or not.)
- Multi-Task Learning (more refined classifications, type of car. Door is open or not? Pedestrian action?)
- Better benchmarking of our models. Not just using an existing model
Current Perception Stack (on monorepo_v1)
https://drive.google.com/file/d/1XAOEZ1mQ4vm3iRDFr7V6nC529kjzT3nR/view?usp=sharing
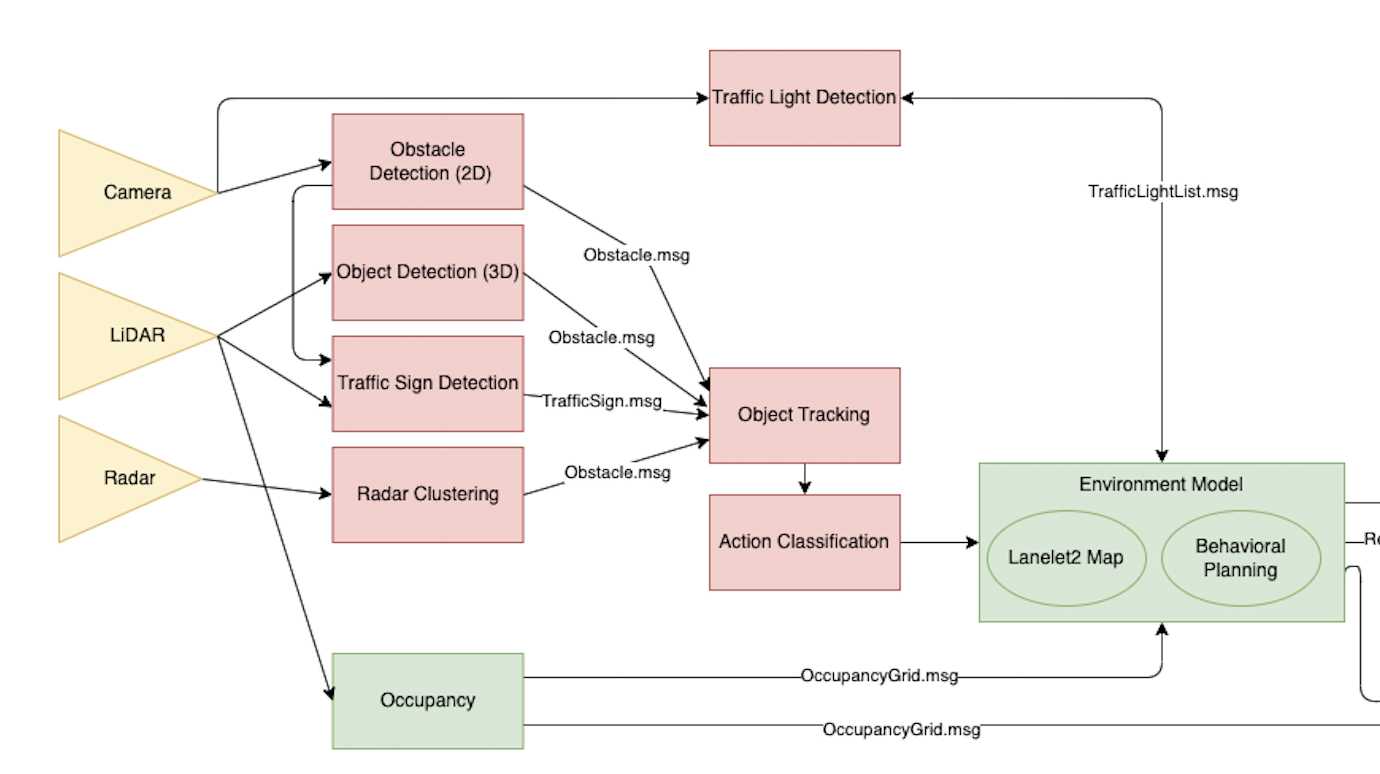
- Object Detection
- 2D: YOLOv5 (pretrained) → Use for Traffic Sign Detection as backup
- 3D: PointPillars, PointPillars, SECOND (too slow), Frustum PointNet (didn’t work)
- Before: We did 2D object detection, then with the bbox generated we use project them (frustum) and apply Euclidean Clustering to select the best cluster
- Traffic Light Detection
- YOLO to find the traffic light
- OpenCV color filtering (Finding Contour + Finding Direction)
- Traffic Sign Detection
- Lane Detection
- Fisheye camera
- Old method: 4-step process with Semantic Segmentation
- New Method: End to end with Ultra Fast Lane Detection: https://arxiv.org/pdf/2004.11757.pdf
Where we’re going: https://drive.google.com/file/d/1VMyHuNRETZ5gWRdH9H7obLK6-alnZBPx/view?usp=sharing
- Update 2023-01-27: I think complexifying all of this by introducing all these modalities is stupid. You should be problem oriented, what predictions are you trying to make? Refer to hand-drawn chart above.
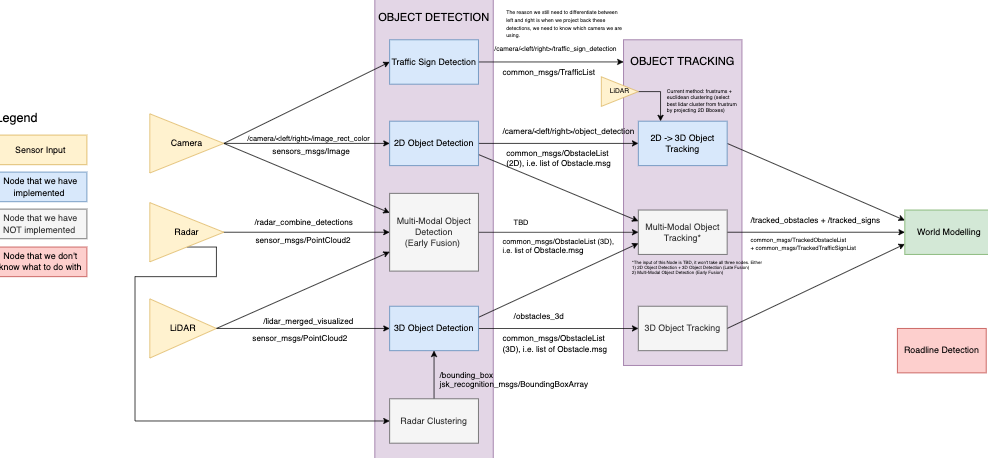
Old Notes (DEPRECATED)
Immediate Focus:
- Implement the Bird-Eye View stuff with BEVFusion
- Idea is to then generate this with CARLA, get the ground truth of the bird-eye view
- Publish paper on this? End to end with bird eye view labels simulation from CARLA
- Learn how EfficientDet works (BiFPN), which is what Tesla does
- https://github.com/google/automl/blob/master/efficientdet/tutorial.ipynb
- There’s also this Swin Transformer used in BEVFusion
- CARLA Synthetic Data Generation
- Genrate Curb Dataset
- Generate BEV dataset
- Curb Detection (after CARLA is done), see https://arxiv.org/pdf/2110.03968v1.pdf
- So I found this repo HybridNet, which does Multi-Task Learning, and I managed to implement it combined with ONNX thanks to this guy’s repository. And he has a bunch, so I think I will follow this template
Personal Notes
To be an expert in perception, I need to:
- Be able to write YOLO from scratch
- Write PointPillars and all these detection algorithms from scratch
- Write Transformers from scratch, GANs as well
- Understand Sensor Fusion and how those are combined
- Convert to Bird-Eye View
Future Research directions:
- Generating data for our models to train on (Sim2Real)
- Lane Detection, look into this paper WATonomous wrote: https://arxiv.org/pdf/2202.07133.pdf
- Camera Calibration
- Better classifications, like Action Classification for pedestrians and cars (toggling lights, etc.)
- Monocular Depth (implement from scratch)
NO, I think main thing is to get really good at engineering.
From F1TENTH:
- Depth from Monocular Camera (Monodepth2)
- Dehaze (Cameron Hodges et al.) → Allows better object detection outputs
- Night to Day (ForkGAN): https://github.com/zhengziqiang/ForkGAN, or cycleGAN?
Papers with Code, interesting topics:
- Lane Detection (53 papers)
- 3D Object Detection
- Multimodal Association
- Open Vocabulary Object Detection
- Self-Supervised Image Classification
- Object Tracking
Literature Reviews:
Concepts
Papers
- LiDAR
- Camera
- Other
- Ground Segmentation
- We use Cut, Paste, Learn to generate data: “A major impediment in rapidly deploying object detection models for instance detection is the lack of large annotated datasets”
- Projection Matrix for Camera Calibration
- Essential Papers
Blog for object detection:
Resources:
Camera is useful for:
- Knowing the type of traffic sign (to see it)
- Action Classification