Stephen Jones
He gave some fundamental keynotes on CUDA:
The GPU is a throughput machine. The CPU is a latency machine.
Steven, you love fighting Bottleneck.
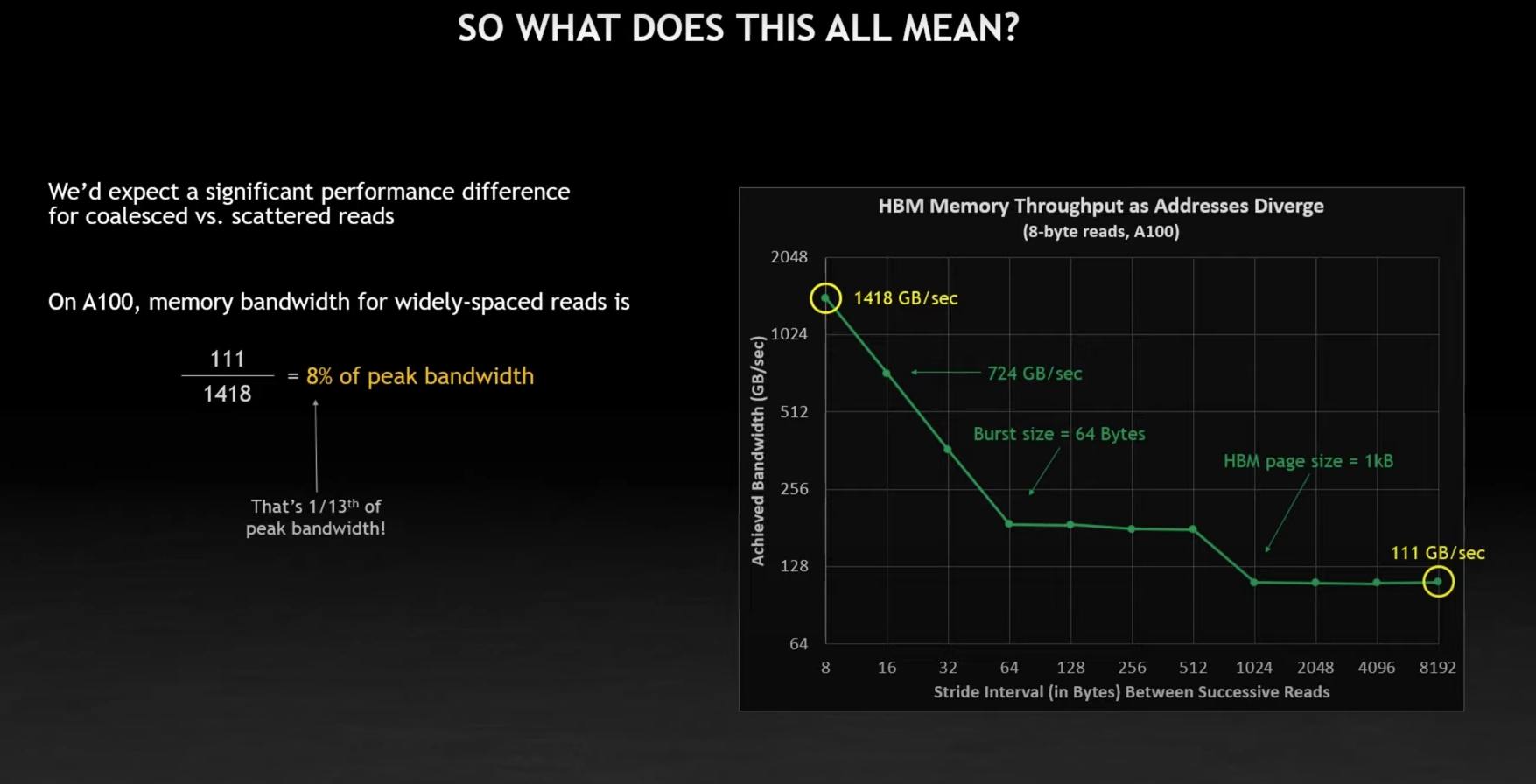
- Well, the bottleneck is not FLOPS, it’s memory bandwidth
FLOPS aren’t the issue - bandwidth is the issue.
Fundmental Difference
- CPU cuts out latency
- GPU designers don’t care about latency as much, they increase bandwith (15:00 of video)
He explains how DRAM works.
 Sense Amplifier on the RAM
Sense Amplifier on the RAM
Efficient use of resources drives performance.
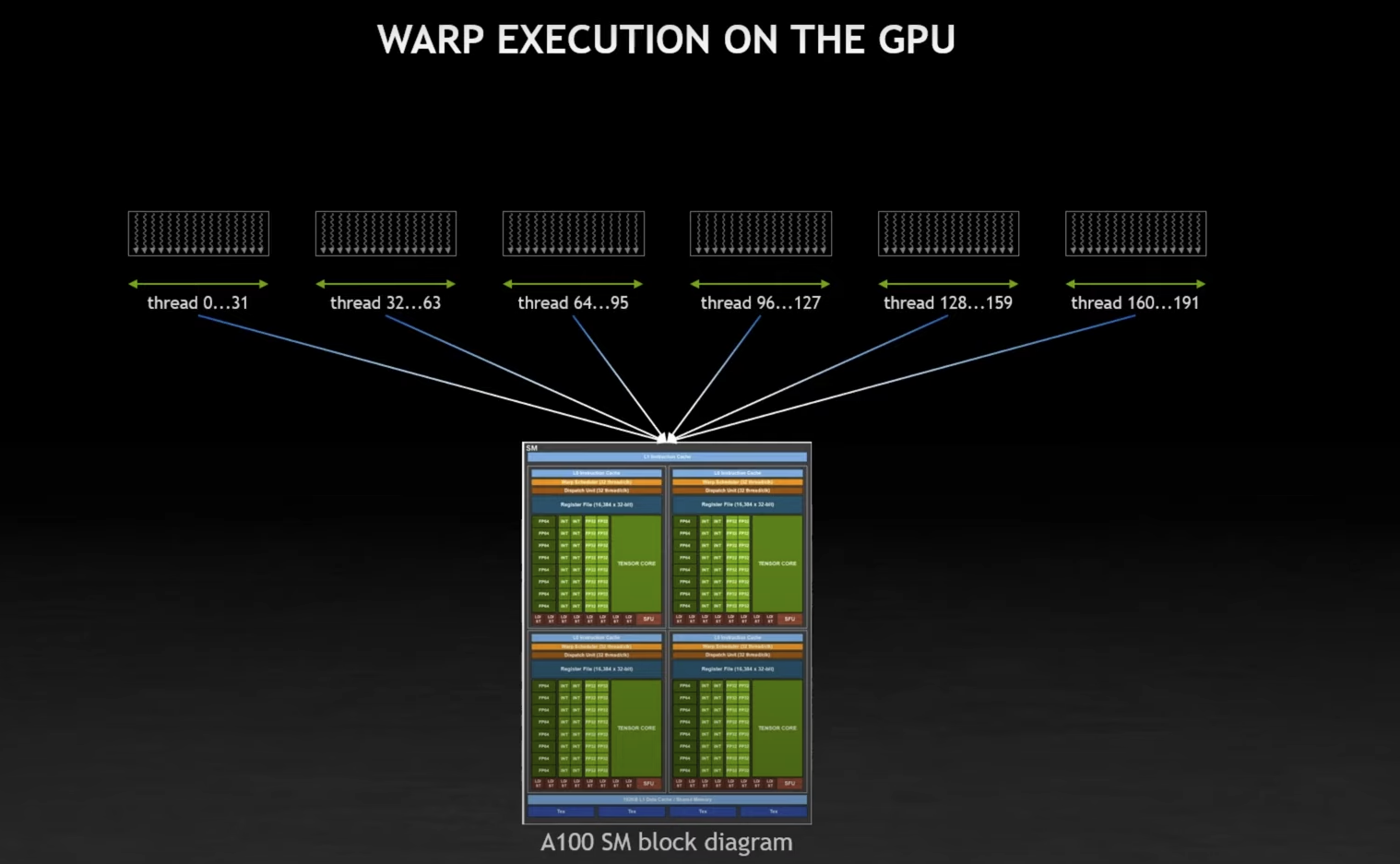
He talks about how each SM can managed 64 warps, so a total of 2048 threads. However, it really processes 4 warps at a time, which
The memory page size is exactly 1024 bytes.
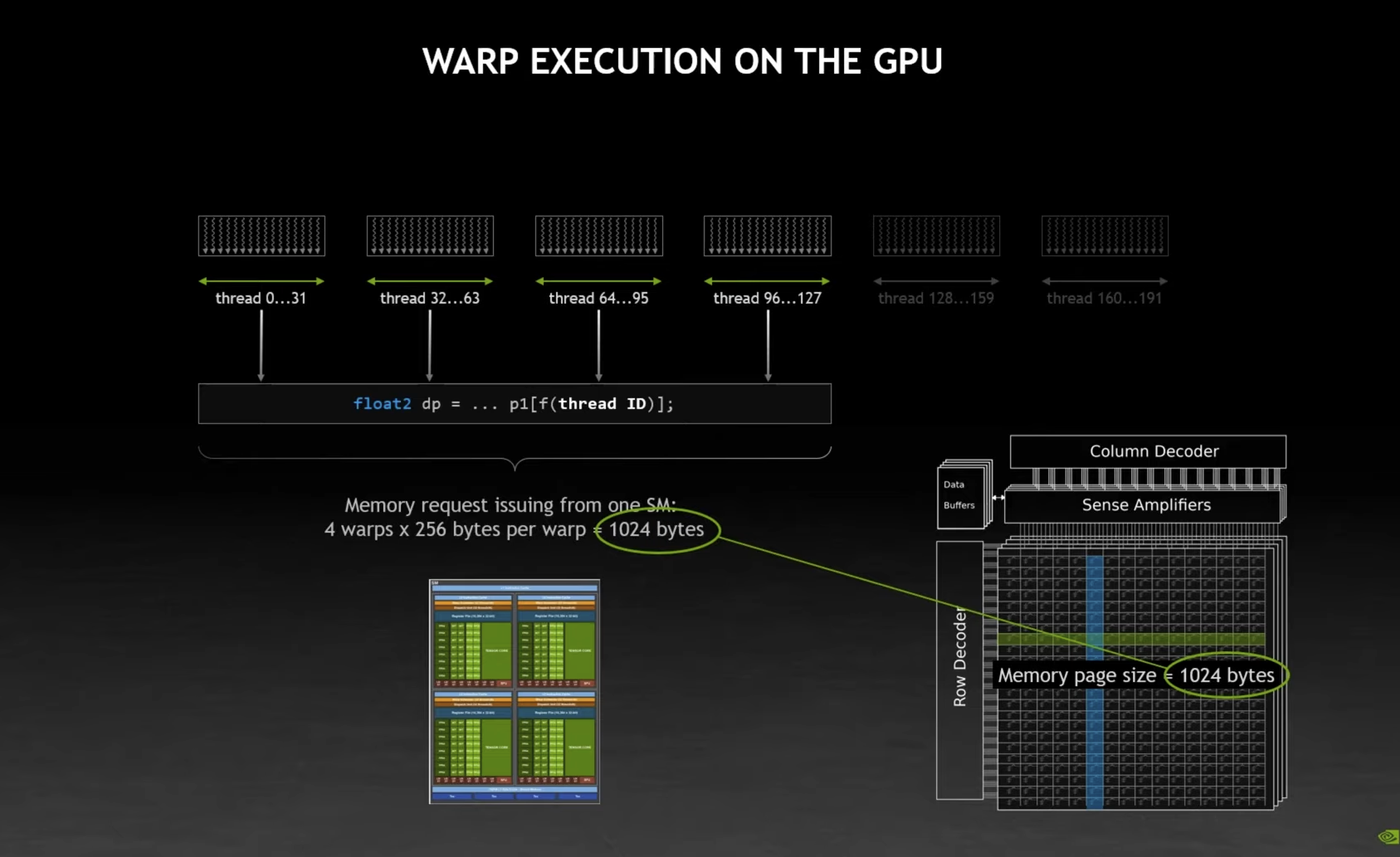
- A SM is actually running 4 warps at the same time, the rest are kept in a queue
For a single thread, this looks like random-address memory reads. It’s actually adjacent reads of whole pages of memory.
One SM per block!
A block runs on a single SM. It can never span 2 different SMs.

Blocks get placed

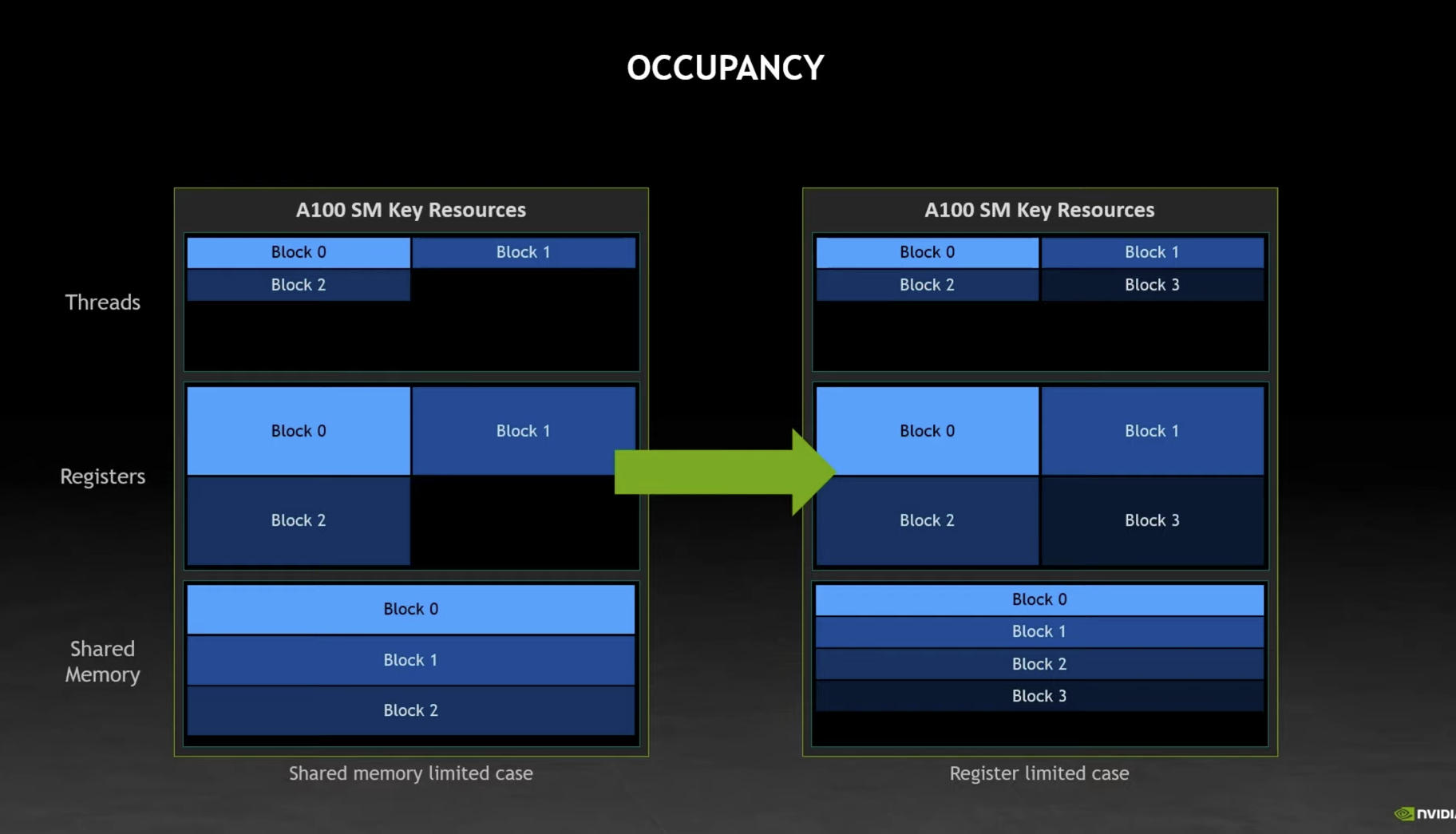
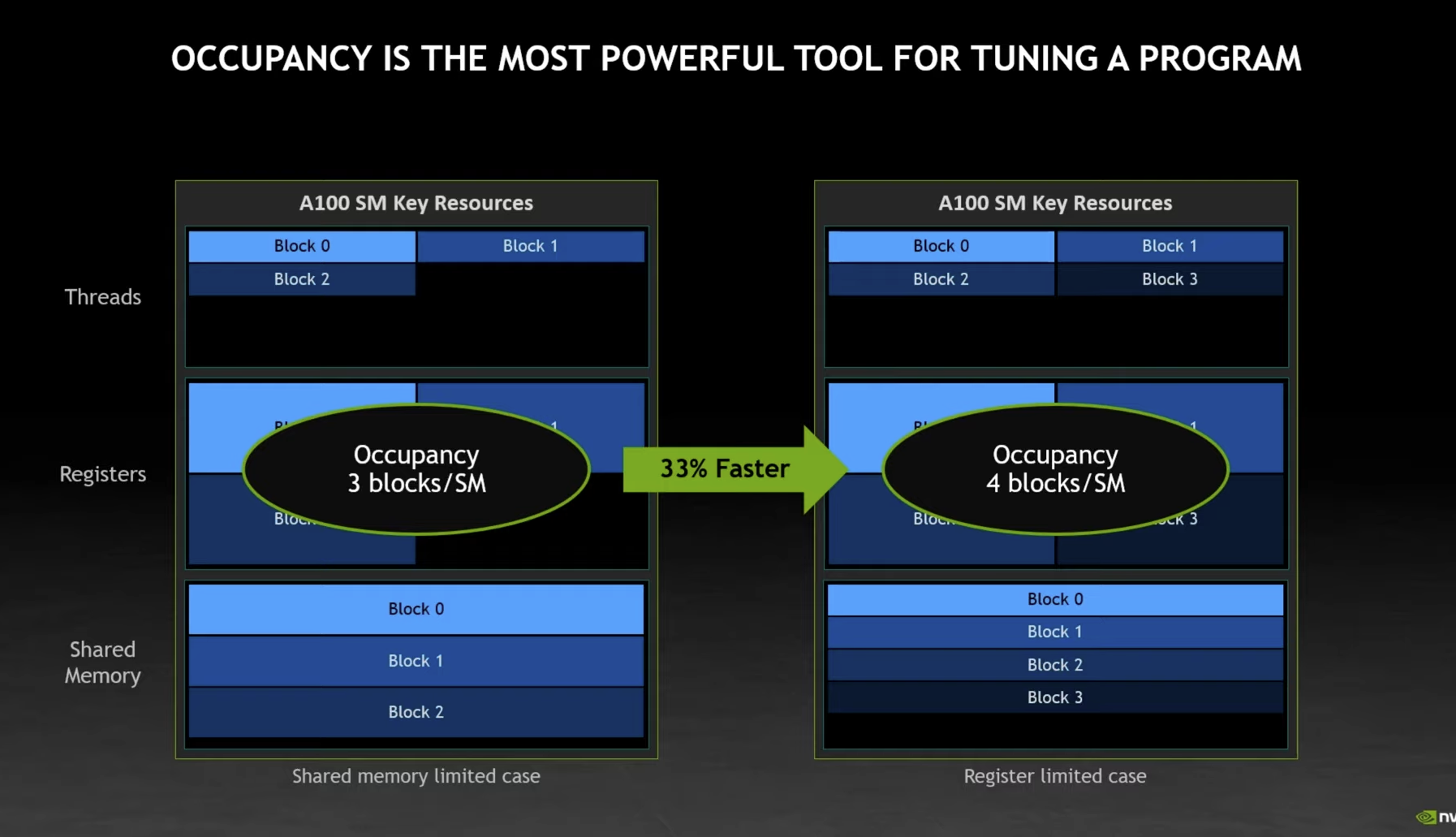
Is there a way to sanity-check occupancy?
idk
He talks a little more about CUDA streams.
- This is how you pack together different streams of block
