Trust Region Policy Optimization (TRPO)
TRPO updates policies by taking the largest step possible to improve performance, while satisfying a special constraint on how close the new and old policies are allowed to be.
Resources
- https://spinningup.openai.com/en/latest/algorithms/trpo.html
- Implementation here
- OG paper https://proceedings.mlr.press/v37/schulman15.html
In Vanilla Policy Gradient, we just do a gradient update of the weights. can change drastically between each step if you think about the parameter landscape.
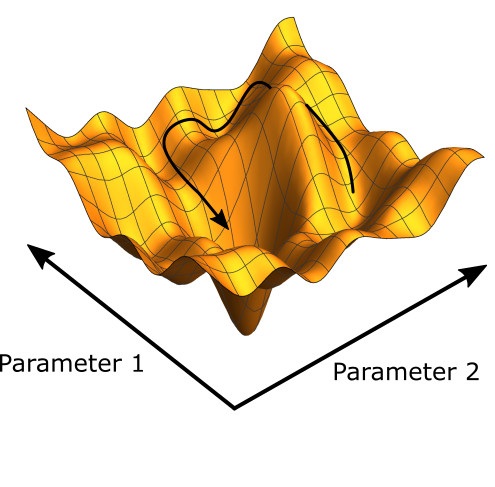
TRPO nicely avoids this kind of collapse, and tends to quickly and monotonically improve performance by adding a KL Divergence constraint, which forces to be similar to .
I was thinking looking at the VPG spinning up implementation that they would just use log_p - old_log_p, and then can use this alpha as a regularization term. However, it doesn’t seem like they do that.
The goal is the find the best parameters that maximizes the surrogate advantage that satisfies the KL divergence constraint.
The surrogate advantage:
And KL Divergence constraint:
