U-Net
U-Net is a type of convolutional neural network (CNN) architecture designed primarily for image segmentation tasks.
I’ve heard about this architecture before, but I think I was reintroduced after reading on Diffusion Policy
https://en.wikipedia.org/wiki/U-Net
Is U-Net an autoencoder?
Yes, it’s basically an Autoencoder with skip connections, to allow the network to retain spatial information that would otherwise be lost during downsampling
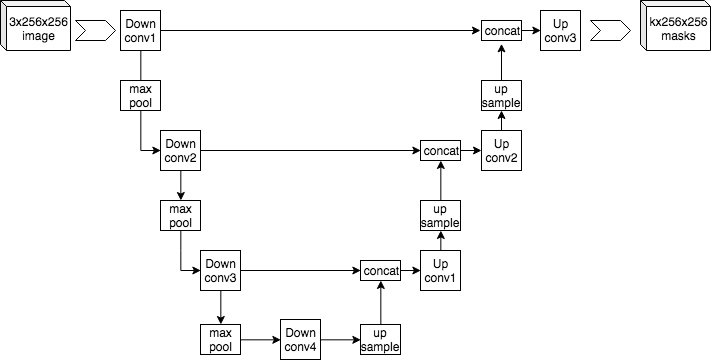
Architecture (CS231n 2025 Lec 9)
Symmetric encoder-decoder for semantic segmentation:
- Downsampling phase: repeated conv → conv → max-pool stages, halving spatial size and doubling channels each step. Builds high-level features at low resolution.
- Upsampling phase: repeated up-conv → conv → conv stages, doubling spatial size and halving channels.
- Copy-and-crop skip connections: each decoder stage concatenates the matching encoder feature map (cropped to size) before its conv block. This gives the decoder direct access to high-resolution features that downsampling would have erased.
Without skips, the decoder would have to reconstruct fine-grained boundaries from a tiny low-res feature map — impossible. The U-shape comes from drawing the encoder going down on the left and the decoder going up on the right, with horizontal arrows for the skips.
Originally Ronneberger et al. (2015) for biomedical image segmentation, where labeled training data is scarce — the skip-heavy design helps the network learn from few examples.
Source
CS231n 2025 Lec 9 slide 65 (U-Net schematic, copy-and-crop skip connections). 2026 PDF not published — using 2025 fallback.