Denoising Diffusion Probabilistic Model (DDPM)
DDPMs are a class of generative model where the output generation is modeled as a denoising process, often called Stochastic Langevin Dynamics.
- Learning about these via Diffusion Policy
Oh this is just a standard diffusion model.
Resources
- https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- https://huggingface.co/blog/annotated-diffusion
- https://arxiv.org/pdf/2006.11239
See Stable Diffusion for an implementation example?
At a high-level, it’s really only a 2-step process:
- A fixed (or predefined) forward diffusion process that adds Gaussian noise
- A learned reverse denoising diffusion process
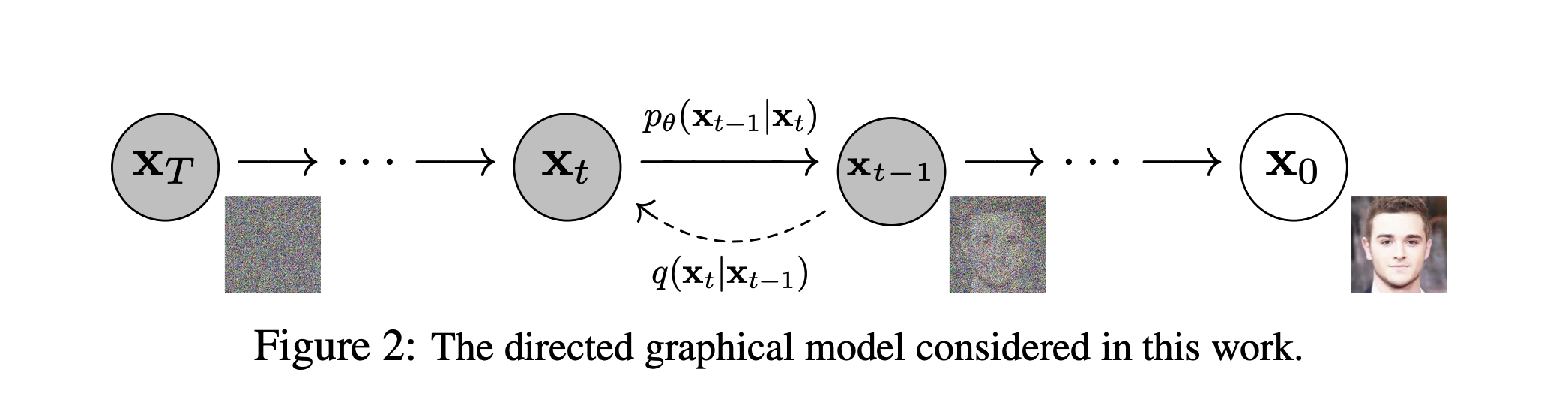
1. Forward Diffusion Process in DDPM
In the forward diffusion process, for each timestep , we add unit Gaussian noise to the previous sample to produce :
- is the Identity Matrix
This is you are sampling from a normal distribution with the following mean and variance:
I'm confused as to why they use
\sqrt{1 - \beta_t}This is to ensure that the total variance remains 1 (review Sum of Gaussians):
\text{Var}(x_t) &= \text{Var}(\sqrt{1 - \beta_t} \cdot x_{t-1}) + \text{Var}(\sqrt{\beta_t} \cdot \epsilon) \\ &= (1 - \beta_t) \cdot \text{Var}(x_{t-1}) + \beta_t \cdot \text{Var}(\epsilon) \\ &= (1 - \beta_t) I + \beta_t I = I \\ \end{align}This shows that using ensures that remains unit gaussian.
As a condition probability , this is written as:
Variance schedule
does not have to beconstant at each time step, we actally define variance schedule, .
- is a variance schedule really needed? Yes, it’s similar to ideas behind Learning Rate.
- Can be linear, quadratic, cosine, etc. as we will see further (a bit like a learning rate schedule).
2. Denoising process
Now, let’s say we want to reverse the process. We know how is calculated. Is the reverse doable? Review your Bayes Rule:
- The problem is that we don’t know , or do we? That is the thing we want to predict
Okay, no problem, just slap a universal function approximator, i.e. a neural network!!
- The neural net learns two parameters, and
In the original paper
They only made the neural net learn , and fixed the variance.
3. Objective function
Okay, so how do we formulate objective function for the neural net to learn?
We’ll use U-Net.