Autoencoders
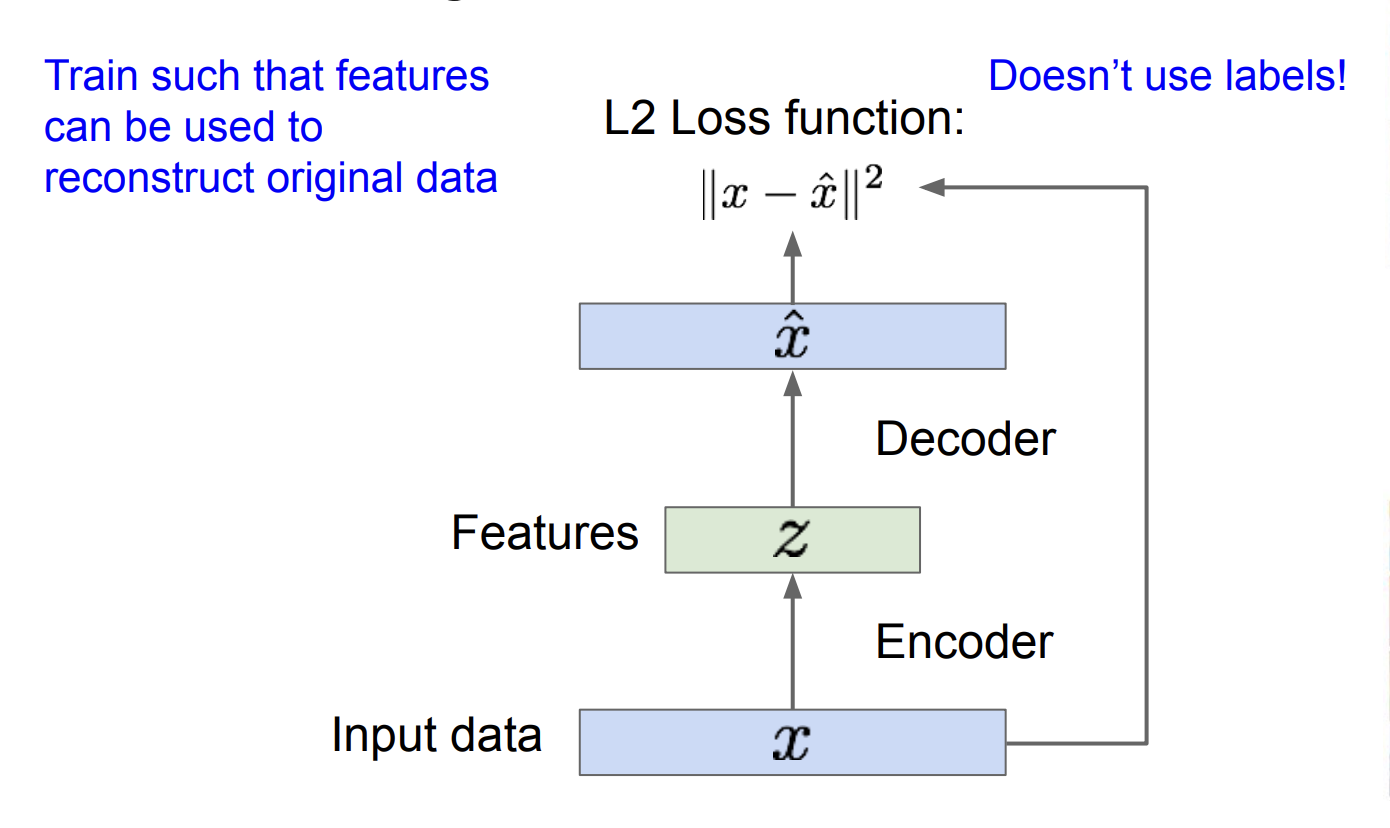
An autoencoder is a type of Neural Network used to learn data encodings in an unsupervised manner.
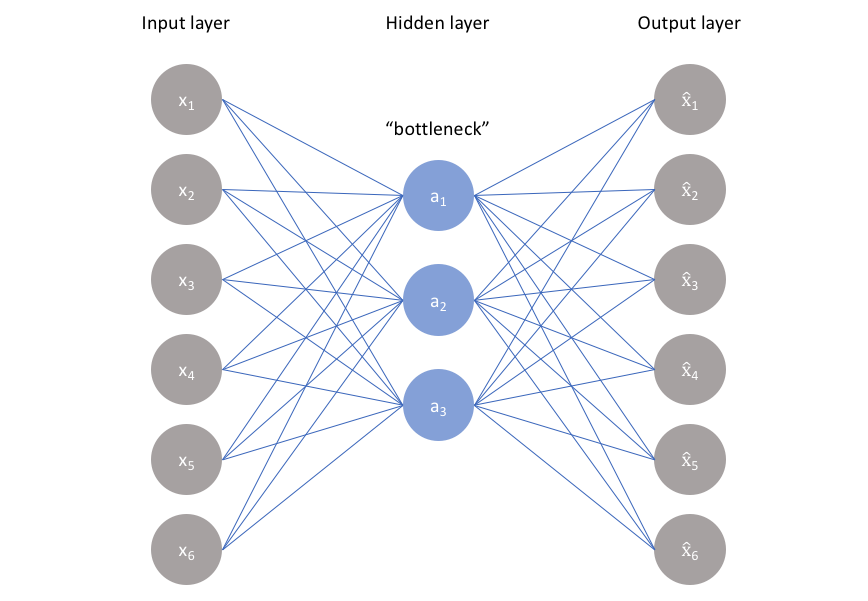
At its core, it’s just an MLP that learns to compress and then reconstruct its input by passing data through a lower-dimensional bottleneck.
Intuition
A self-supervised bottleneck. The network has no labels, so the only way to reconstruct from a smaller vector is to learn which features of the data actually matter. If the bottleneck is 10-dim and the input is a 784-pixel digit, the encoder is forced to throw away pixel-level noise and keep digit-shape structure. Think of it as a learned, nonlinear PCA.
Resources
- https://lilianweng.github.io/posts/2018-08-12-vae/
- https://www.v7labs.com/blog/autoencoders-guide
- Video: https://www.youtube.com/watch?v=bIaT2X5Hd5k&ab_channel=DigitalSreeni
Autoencoders consist of 3 parts:
- Encoder: tries to compress the input data
- Bottleneck (contains the “features”): holds the compressed feature representation, the most important part of the network
- Decoder: tries to reconstruct the input data, compared against a ground truth
One practical application of autoencoders is that we remove the decoder, and simply use our encoder as input to a standard CNN. The bottleneck has done unsupervised feature learning for free, which used to matter a lot when labels were scarce.
Why a plain autoencoder is not a generative model
The latent space has no prescribed shape. If you sample a random and run it through the decoder, you’ll hit “holes” where the encoder never mapped any real data, and the output will be garbage. VAEs fix this by forcing the latents toward a known prior