Unified Memory (UM)
I think there are things here that are super important, as well for managed NITROS.
Resources
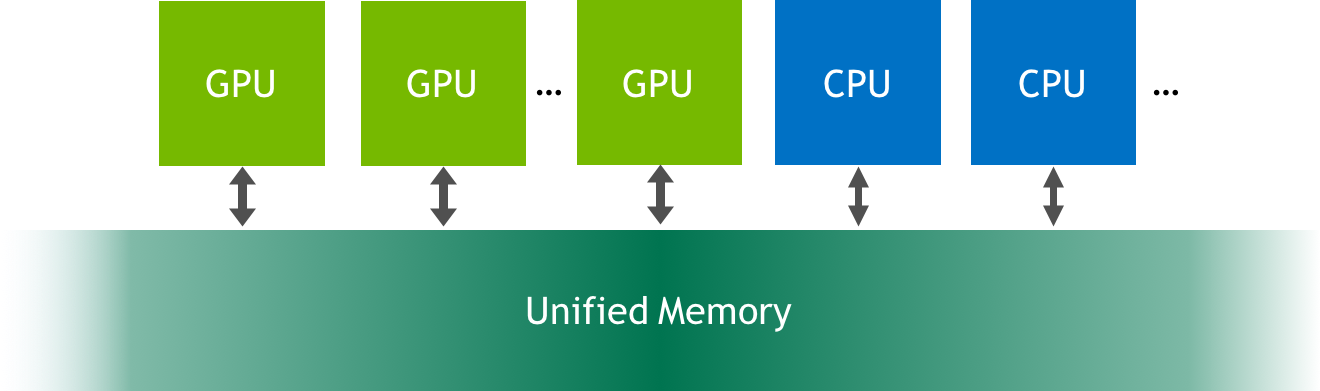
Unified Memory is a single memory address space accessible from any processor in a system.
Unified Memory Migration
From the CUDA course on Accelerated Computing. This is fundamental understanding.
When UM is allocated, the memory is not resident yet on either the host or the device. When either the host or device attempts to access the memory, a page fault will occur, at which point the host or device will migrate the needed data in batches. Similarly, at any point when the CPU, or any GPU in the accelerated system, attempts to access memory not yet resident on it, page faults will occur and trigger its migration.
The ability to page fault and migrate memory on demand is tremendously helpful for ease of development in your accelerated applications. Additionally, when working with data that exhibits sparse access patterns, for example when it is impossible to know which data will be required to be worked on until the application actually runs, and for scenarios when data might be accessed by multiple GPU devices in an accelerated system with multiple GPUs, on-demand memory migration is remarkably beneficial.
Why you need to go down the abstraction
There are times - for example when data needs are known prior to runtime, and large contiguous blocks of memory are required - when the overhead of page faulting and migrating data on demand incurs an overhead cost that would be better avoided.
Much of the remainder of this lab will be dedicated to understanding on-demand migration, and how to identify it in the profiler’s output. With this knowledge you will be able to reduce the overhead of it in scenarios when it would be beneficial.