Warp Scheduling (GPU Thread Scheduling)
How do instructions get scheduled on the GPU? This article is a really good overview.
You should actually read NVIDIA docs, the official source of truth:
When a block is divided up into warps, each warp is assigned to a warp scheduler.
- Reminder that a warp is composed of 32 threads of code (see CUDA Kernel)
Warps will stay on the assigned scheduler for the lifetime of the warp.
VERY IMPORTANT: The scheduler is able to switch between concurrent warps, originating from any block of any kernel, without overhead. - Source
Why is it possible without overhead?
Because the data is maintained inside the register file. Unlike a CPU, where when you context switch, you need to store the state of the registers into memory, in your SM, you can just be like “I’ll switch to another warp and come back after”, without modifying the state of the registers.
“When switching away from a particular warp, all the data of that warp remains in the register file so that it can be quickly resumed when its Operands become ready”. wikipedia
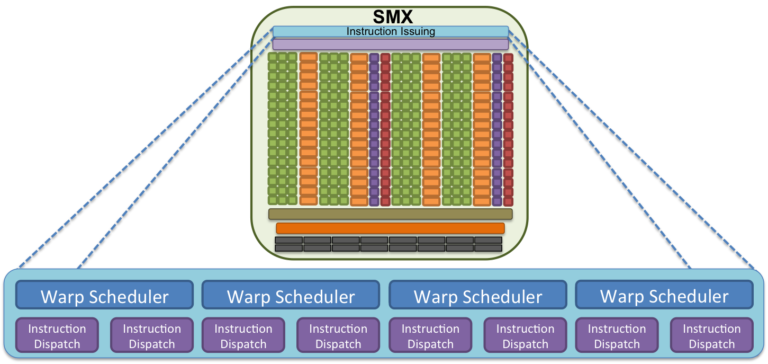
The SM processes 4 warps at the same time in a given cycle.
Why 4?
Because there are 4 warp schedulers per SM.
but isn't there synchronization needed, seeds the schedulers read the same instruction?
Each scheduler manages its own queue of warps. and selects a warp to issue an instruction to the execution units. Warps are independent execution units (SIMD-style execution).
Essentially, in a given cycle, there are up to 4 warps that can be assigned “work”, if there are 4 warp schedulers.
What happens at a thread level?
This was the thing that I was always confused about, but reading about the NVIDIA docs helps a bit more.
A warp executes one common instruction at a time, so full efficiency is realized when all 32 threads of a warp agree on their execution path.
Branch divergence occurs only within a warp; different warps execute independently regardless of whether they are executing common or disjoint code paths.
Since NVIDIA Volta, the GPU maintains execution state per thread, including a program counter and call stack.
Each thread has its own program counter!
This is very important, it allows full concurrency between threads.
“Prior to NVIDIA Volta, warps used a single program counter shared amongst all 32 threads in the warp together with an active mask specifying the active threads of the warp”.
In the next cycle, the warp scheduler can dispatch more instructions to free warps. As computation is being done, some of these warps will become blocked.
- In a CPU, a core could also be blocked. In which case the OS can context switch to another process. But this is slow because we need to save the state of the registers. But for GPU programming, because we have so many warps and thus registers, we can just switch to another free warp to do work.
If more than one warps are eligible for execution, the parent SM uses a warp scheduling policy for deciding which warp gets the next fetched instruction.
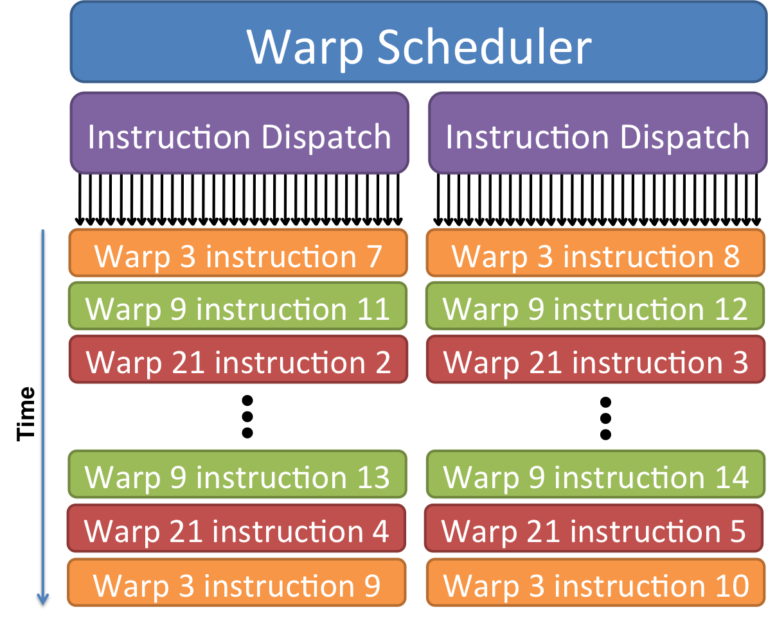
Why does a warp scheduler have 2 instruction dispatch?
Is this inspo from how we do CPUs with Hyperthreading? Seems like it.
At each cycle the scheduler selects a warp, and if possible, two independent instructions will be issued to that warp.
- They must be mapped to different functional units (e.g., one ALU operation and one memory operation)
This convo with ChatGPT also helped clarify
Warp vs. block scheduling? https://stackoverflow.com/questions/64624793/warp-and-block-scheduling-in-cuda-what-exactly-happens-and-questions-about-el