A Simple Framework for Contrastive Learning of Visual Representations
How do they prevent mode collapse?
Walkthrough (CS231n 2025 Lec 12)
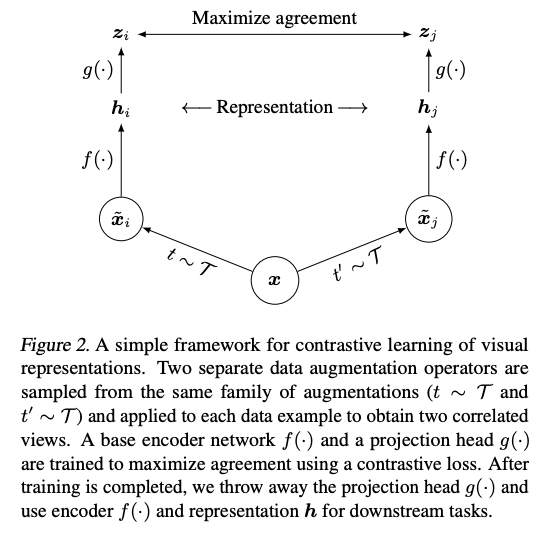
The pipeline
- is the augmentation distribution (random crop + color distortion + Gaussian blur — the lec notes these are the crucial three).
- is the feature encoder (ResNet-50 in the paper). is what you keep for downstream tasks.
- is a small MLP projection head. is where the contrastive loss is applied. Throw away at inference.
Minibatch algorithm
For a minibatch of images:
- Draw , apply both to every image → augmented views.
- Encode with shared encoder + projection → .
- Build affinity matrix — cosine similarity, shape .
- For each row , the positive is at position or (partner view of the same source image); all other entries are negatives.
- InfoNCE per row: Total loss averages over all source images.
Why the projection head helps
Representation is trained to be invariant under augmentation — that collapses useful signal (e.g. color, orientation). sits one MLP away, so it keeps information that had to throw out. Linear eval on beats linear eval on consistently; SimCLR ablation table shows non-linear projection head ~7 points better than no head.
Why large batch matters
Larger batch = more negatives = tighter MI lower bound (). Paper sweeps batches from 256 to 8192 and every doubling improves ImageNet linear eval Top-1. Batch 8192 requires TPU pods — the motivation for MoCo’s decoupling trick.
Downstream numbers (Chen 2020)
- Linear eval ImageNet Top-1: SimCLR 69.3% (ResNet-50), SimCLR 4× 76.5% — matches supervised ResNet-50.
- 1% label fine-tune, Top-5: SimCLR 4× 85.8% → beats AlexNet trained with 100× more labels.
Source
CS231n 2025 Lec 12 slides ~76–86, 105–108 (SimCLR architecture + pipeline, minibatch algorithm, affinity matrix, projection head ablation, large-batch ablation, semi-supervised table, summary).