CS231n — Deep Learning for Computer Vision
Stanford’s flagship deep-learning-for-vision course, originally designed by Andrej Karpathy. Light on theory, heavy on intuition built around backprop through computational graphs.
Resources
- Course page: https://cs231n.stanford.edu/
- Schedule (2026): https://cs231n.stanford.edu/schedule.html
- Online notes: https://cs231n.github.io/
Lectures
Lec 1 — Course Intro and CV History
- Course framing, biological vision, and the ImageNet-era story of computer vision.
Detailed coverage
- Course intro, history of CV — biological vision, Hubel & Wiesel, ImageNet.
Lec 2 — Image Classification
- Image classification, kNN, validation, linear models, and softmax vs SVM.
Detailed coverage
- Image Classification — data-driven approach, kNN, hyperparameters and validation.
- Linear Classifier, Softmax vs SVM / Hinge Loss.
Lec 3 — Regularization and Optimization
- Regularization, SGD issues, optimizer variants, and learning-rate schedules.
Detailed coverage
- Regularization (L1 / L2 / elastic net).
- Optimization and SGD problems: conditioning, saddle points, noise.
- SGD+Momentum, RMSProp, Adam, AdamW, LR schedules.
Lec 4 — Neural Networks and Backpropagation
- Nonlinearity, computational graphs, gradient flow, and practical backprop patterns.
Detailed coverage
- Neural Networks and Backpropagation — feature transforms and why nonlinearity matters.
- Computational graphs, gradient-flow patterns (add / mul / copy / max gates), modular forward / backward API.
- Vector and matrix backprop with implicit Jacobians, SiLU activations.
Lec 5 — Convolutional Neural Networks
- Spatial structure, convolution shapes, receptive fields, pooling, and what CNN filters learn.
Detailed coverage
- Why preserve spatial structure.
- Conv layer shapes (), padding / stride formulas, receptive fields (), 1x1 conv.
- Pooling, translation equivariance vs invariance, what filters learn.
Lec 6 — Training CNNs and CNN Architectures
- Normalization, dropout, activation trends, ImageNet architectures, and transfer-learning workflow.
Detailed coverage
- LayerNorm / BatchNorm / Dropout, sigmoid → ReLU → GELU / SiLU.
- ImageNet history: AlexNet → VGG → GoogLeNet → ResNet.
- VGG’s all-3x3 design, ResNet residual block (), Kaiming init.
- Preprocessing and augmentation, transfer learning (similarity x data-size matrix), hyperparameter workflow + loss curve diagnostics.
Lec 7 — RNNs, LSTMs, and GRUs
- Sequence patterns, BPTT, captioning, gradient issues, and gated recurrent models.
Detailed coverage
- Sequence patterns: 1-to-many, many-to-1, many-to-many, seq2seq.
- Vanilla RNN , char-level LM + min-char-rnn, BPTT + truncated BPTT.
- Image captioning (CNN → RNN with injection), multilayer RNNs.
- Vanilla RNN gradient flow (product of terms → vanish / explode), gradient clipping.
- LSTM (i / f / o / g gates, , uninterrupted gradient path approximately like ResNet), GRU, Seq2Seq encoder-decoder.
Lec 8 — Attention and Transformers
- Seq2seq attention, self-attention, Transformer blocks, scaling, and ViTs.
Detailed coverage
- Bahdanau attention from the seq2seq bottleneck, generalized attention layer (scaled dot product, separate K / V).
- Self-attention as a permutation-equivariant set operator, masked self-attention, multi-head self-attention as 4 matmuls ( memory, Flash Attention fix).
- Transformer block (SA + MLP, residuals, LN, 6 matmuls), scale chart 213M → 175B.
- LLM recipe: embedding → masked Transformer → projection → softmax.
- Modern tweaks: Pre-Norm, RMSNorm, SwiGLU, MoE.
- Vision Transformer: 16x16 patches → linear projection equivalent to strided conv → 2D positional encoding → unmasked self-attention → average pool + classifier.
Lec 9 — Segmentation, Detection, and Visualization
- Segmentation, detection, instance masks, and feature visualization tools.
Detailed coverage
- Semantic Segmentation: sliding window → fully convolutional, encoder-decoder with unpooling / transposed conv, U-Net copy-and-crop.
- Object Detection: single-object multitask loss → multiple-object problem → Selective Search + R-CNN → Fast R-CNN with RoI Pool / Align → Faster R-CNN with RPN / anchors → single-stage YOLO / SSD / RetinaNet → DETR set prediction.
- Instance segmentation: Mask R-CNN = Faster R-CNN + per-class 28x28 mask head, also pose.
- Feature Visualization: first-layer filters, saliency via backprop, guided backprop, CAM, Grad-CAM, ViT attention.
Lec 10 — Video Understanding
- Video tensors, 3D CNNs, optical flow, video transformers, and efficient / multimodal video modeling.
Detailed coverage
- Video as a 4D tensor (), train short clips, test-time clip ensemble.
- 3D CNN (“Slow Fusion”) with shift-invariance comparison, C3D (“VGG of 3D CNNs”, 39.5 GFLOP), Sports-1M, recognizing actions from motion (Johansson 1973).
- Optical Flow + Two-Stream Networks (temporal stream beats spatial on UCF-101).
- CNN+LSTM combos and Recurrent Convolutional Network (Ballas — replace matmul with 2D conv).
- Nonlocal Block (Wang CVPR 2018, drop-in to 3D CNNs via 1x1x1 Q / K / V convs), I3D — Inflating 2D Networks to 3D (Carreira & Zisserman, copy-and-divide-by- init trick).
- Video Transformers: factorized attention ViViT / TimeSformer, pooling MViTv2, masked autoencoders VideoMAE / V2.
- Kinetics-400 climb: I3D 71.1 → SlowFast+NL 79.8 → MViTv2-L 86.1 → VideoMAE V2-g 90.
- Visualizing video models (Appearance vs Slow vs Fast motion), Temporal Action Localization (Faster-R-CNN-style temporal proposals), Spatio-Temporal Detection (AVA dataset).
- Audio-visual video understanding (McGurk, visually-guided audio source separation), efficient video (MoViNets, X3D, SCSampler, AdaMML, Listen to Look), egocentric (Project Aria), Video + LLMs (Video-LLaVA, Video-ChatGPT, VideoLLaMA 3).
Lec 11 — Large-Scale Distributed Training
- Hardware, sharding, checkpointing, parallelism, and scaling recipes for very large models.
Detailed coverage
- H100 hardware: HBM 80GB / 3352 GB/s, 132 SMs, Tensor Cores 4096 FLOP / cycle; K40 → B200 FLOPs timeline.
- Data Parallelism → FSDP (ZeRO sharding of params / grads / Adam states, all_gather + reduce_scatter per layer) → HSDP (intra-node FSDP + inter-node DP).
- Llama3-405B memory arithmetic (800GB → 10GB / GPU), activation checkpointing (-optimum compute / memory tradeoff).
- HFU vs MFU:
30% good, >40% excellent; GPT-3 21%, PaLM 46%.
- ND parallelism over (Batch, Seq, Dim) = DP / CP / PP / TP, Context Parallelism (Ring Attention, DeepSpeed Ulysses).
- Pipeline Parallelism (GPipe bubble + microbatches, active fraction), Tensor Parallelism (column / row sharding two-layer no-comm trick).
- Llama3-405B 4D recipe table: 8K → 16K GPUs, seq 8192 → 131072, MFU 43% → 41% → 38%.
Lec 12 — Self-Supervised Learning
- Pretext tasks, MAE, contrastive learning, SimCLR, MoCo, CPC, and DINO.
Detailed coverage
- Pretext tasks: rotation prediction / Gidaris 2018, relative patch location / Doersch 2015, jigsaw / Noroozi 2016, inpainting via Context Encoders / Pathak 2016, colorization / split-brain autoencoder Zhang 2017, video coloring Vondrick 2018.
- Masked Autoencoders (MAE): 75% masking, asymmetric encoder on visible-only patches + lightweight decoder, MSE on masked patches, ViT-H 448 → 87.8% ImageNet.
- Contrastive learning framework: attract , repel , InfoNCE as -way softmax, MI lower bound .
- SimCLR: 2 batch, cosine similarity affinity matrix, non-linear projection thrown away post-train, large batch crucial — 8192 on TPU.
- MoCo: FIFO queue of negatives + momentum encoder , decouples batch size from number of negatives, MoCo-v2 = MoCo queue + SimCLR MLP head + strong aug, 67.5% vs SimCLR 66.6% at 256-batch.
- Instance-level (SimCLR / MoCo) vs sequence-level contrastive, CPC (van den Oord 2018 — encode , summarize context via GRU-RNN, InfoNCE with time-dependent score , applies to audio / image patches).
- DINO: self-distillation, student + teacher from EMA, cross-entropy with teacher centering + sharpening to prevent collapse, ViT 8x8 patches → emergent unsupervised object segmentation.
Lec 13 — Generative Models (Part 1)
- Discriminative vs generative modeling, autoregressive models, autoencoders, and VAEs.
Detailed coverage
- Discriminative vs generative vs conditional generative , density-normalization (values of compete for mass).
- Goodfellow 2017 taxonomy: Explicit: Tractable = Autoregressive / Approximate = VAE; Implicit: Direct = GAN / Indirect = Diffusion.
- Autoregressive MLE via chain rule — LLMs are autoregressive.
- PixelCNN: scanline-order 8-bit subpixels as 256-way softmax classification, exact , but 1024x1024 RGB = 3M sequential steps.
- (Non-variational) autoencoder: L2 reconstruction for feature learning and its generative failure (generating new is no easier than generating ).
- VAE fix: force from known prior , encoder + decoder where Gaussian-decoder log-likelihood reduces to L2.
- ELBO derivation: Bayes rule → multiply top / bottom by → three log terms → wrap in expectation → two KLs → drop the intractable posterior-KL .
- Training objective with [[notes/Reparametrization Trick|reparam ]].
- The two losses fight: reconstruction wants + unique per ; prior wants .
- Sampling → decoder, disentangling via diagonal prior (Kingma & Welling MNIST grid — walking / smoothly traces digit identity and style).
Lec 14 — Generative Models (Part 2)
- GANs, diffusion, latent diffusion, DiT conditioning, and modern text-to-image / text-to-video trends.
Detailed coverage
- GAN minimax , alternating SGD with no single loss curve.
- Saturation problem at start ( → flat gradient) and the non-saturating fix: train to maximize .
- Optimal → outer min achieves .
- DC-GAN (Radford ICLR 2016, who later did GPT-1/2), StyleGAN AdaIN with mapping + synthesis networks, latent-interpolation morphs, GAN era 2016-2021.
- Diffusion introduced via modern Rectified Flow: , , train ; training loop is 5 lines, sampling is Euler-step backward with steps.
- Classifier-Free Guidance (Ho & Salimans 2022): randomly drop during training so the same net is conditional + unconditional; at sampling combine to extrapolate toward , doubling sampling cost.
- Noise schedule trick: middle is hardest because of ambiguity, so use logit-normal .
- LDMs: compress to latents via VAE + GAN encoder / decoder — small KL weight + discriminator fixes blurry VAE decoder, then DiT denoises latents.
- DiT conditioning via predicted scale / shift (adaLN-Zero) or cross-attention, T2I (FLUX.1 — T5+CLIP, 12B DiT, 1024 tokens), T2V (Meta MovieGen — 30B DiT, 76K tokens, ).
- 2024 video-diffusion explosion: Sora / Gen3 / MovieGen / Veo 2 / Wan / Cosmos / Kling, distillation collapses 30-50 steps to 1.
- Generalized diffusion template unifies Rectified Flow / Variance-Preserving / Variance-Exploding and x / epsilon / v-prediction targets.
- Score-function view + reverse-SDE view + AR-strikes-back via discrete latents (VQ-VAE + AR Transformer).
Lec 15 — 3D Vision
- 3D representations, NeRFs, Gaussian splatting, and structure-aware 3D reasoning.
Detailed coverage
- 3D Vision (Jiajun Wu) — four-quadrant taxonomy (explicit / implicit x parametric / non-parametric), explicit vs implicit surfaces (torus vs sphere ), level sets, CSG, SDF blending.
- Datasets survey: ShapeNet 3M → ShapeNetCore 51K → Objaverse-XL 10M, CO3D, PartNet, ScanNet; task zoo ( generative vs discriminative).
- Pipelines by representation: Multi-View CNN (Su ICCV 2015 — max-pool over rendered views, about 90% ModelNet40), voxel nets (3D ShapeNets / 3D-GAN / Visual Object Networks — differentiable projection for shape+texture edits) with octree sparsification (OctNet, O-CNN, OGN).
- PointNet: permutation + sampling invariance → with shared MLP + max pool; Chamfer + EMD for point-cloud losses; EdgeConv graph extension.
- AtlasNet (Groueix CVPR 2018 — MLPs parameterize patches).
- Deep implicit functions: Occupancy Networks Mescheder CVPR 2019, DeepSDF Park CVPR 2019, LDIF Genova CVPR 2020 with local ellipsoid elements.
- NeRF Mildenhall ECCV 2020: , volume rendering with .
- 3D Gaussian Splatting Kerbl SIGGRAPH 2023: sparse explicit Gaussian blobs, 137 FPS vs NeRF 0.07, about 2000x faster at comparable quality.
- Structure-aware reps: part sets → relationship graphs → hierarchies → StructureNet hierarchical graphs Mo 2019 → programs.
Lec 16 — Vision-Language Models
- CLIP, CoCa, LLaVA, Flamingo, SAM, and the broader multimodal foundation model landscape.
Detailed coverage
- Vision-Language Models / Multi-Modal Foundation Models (Ranjay Krishna) — foundation-model taxonomy: Language: ELMo / BERT / GPT / T5; Classification: CLIP / CoCa; LM+Vision: LLaVA / Flamingo / GPT-4V / Gemini / Molmo; And More!: SAM / Whisper / DALL-E / Stable Diffusion / Imagen; Chaining: CuPL / VisProg.
- CLIP: symmetric InfoNCE on 400M pairs + zero-shot via text-encoder-as-classifier
- prompt eng (+1.3% “A photo of a X”, +5% multi-prompt mean) + OOD wins (Adversarial 2.7 → 77.1, Rendition 37.7 → 88.9 vs ResNet101 same 76.2 on ImageNet) at 307M vs 44.5M params.
- CLIP disadvantages: batch-size dependence for fine-grained “Welsh Corgi” at 32K, compositionality fails on Winoground / CREPE / ARO / SugarCREPE, NegCLIP hard-positive collapse, image-level captions too coarse, CSAM in 5B datasets.
- CoCa adds Multimodal Text Decoder + captioning loss → 86.3% zero-shot / 91.0% finetuned.
- LLaVA: CLIP penultimate ViT layer not CLS → linear bridge → LLaMA, 3-stage recipe: init frozen + train linear + finetune both,
100K GPT-4-generated instruction tuples.
- Flamingo: frozen NFNet + frozen Chinchilla + Perceiver Resampler downsamples to fixed visual tokens + GATED XATTN-DENSE between LM blocks with
tanh(alpha)gates init at 0 so frozen LM preserved at step 0, interleaved<image><eos>with mask-to-most-recent → in-context few-shot.- Molmo: fully open Sep 2024: weights + data + code + evals; PixMo 700K via spoken 60-90s annotations vs LLaMA 3.1V’s 6B; outputs grounded
<point x= y= alt=>; Elo 1076 = 2nd behind GPT-4o 1079; chains with SAM 2.- SAM: heavy image encoder + light prompt encoder for points / box / mask / text
- lightweight mask decoder, ambiguity → 3 valid masks + confidence with loss only on best match, SA-1B = 1B masks / 11M images = 6x / 400x OpenImages built via data-engine flywheel, zero-shot on bacteria / Van Gogh / produce.
- CuPL: GPT-3 “What does a {class} look like?” → CLIP, +0.65 ImageNet, +3.7 DTD, collapses 80 → 3 prompts.
- VisProg: Gupta 2023 — GPT writes Python that calls Loc / FaceDet / Seg / Select / Classify / Vqa / Replace / ColorPop / BgBlur / Tag / Emoji / Crop / List / Eval modules from in-context examples.
Lec 17 — Robot Learning
- RL, model-based control, imitation learning, diffusion policies, and robot foundation models.
Detailed coverage
- Robot Learning (Yunzhu Li, May 29 2025) — 7-section survey: problem formulation as agent <→ physical world with (state, action, reward) + casts of cart-pole / locomotion / Atari / Go / text-gen / chatbot / cloth-folding into the same loop.
- Embodied / active / situated robot perception vs CV; RL structurally differs from SL via stochasticity / credit assignment / nondifferentiable / nonstationary.
- DQN Atari pipeline: Conv 4→16 8x8/s4 → Conv 16→32 4x4/s2 → FC-256 → FC-A on 4x84x84.
- DeepMind game milestones: AlphaGo Jan 2016 → AlphaGo Zero Oct 2017 → AlphaZero Dec 2018 → MuZero Nov 2019
- AlphaStar Vinyals Science 2018 + OpenAI Five Apr 2019.
- Real-robot RL: ETH RSL Sci Robotics 2020, Unitree B2-W Dec 2024, OpenAI Rubik’s Cube 2019, Visual Dexterity Sci Robotics 2023.
- Model-free is sample-inefficient (“3000 years in 40 days”), motivating model-based learning + receding-horizon planning.
- Key choice of form: pixel dynamics (Deep Visual Foresight Finn & Levine ICRA 2017, CDNA conv+LSTM), keypoint dynamics (Manuelli / Li / Florence / Tedrake CoRL 2020 KUKA pushing Cheez-It), particle dynamics (Wang RSS 2023, RoboCook CoRL 2023 Best Systems — granola / rice / dough piles via GNN ).
- Imitation learning flavors: BC (distribution shift / “no data on how to recover” car illustration), DAgger (iterative expert correction), IRL (RL: env+reward→behavior; IRL: env+behavior→reward), Implicit BC ( for multi-modal actions), Diffusion Policy ( over iterations + action chunking for receding-horizon, beats LSTM-GMM / IBC / BET on multi-modality + commitment).
- Robotic foundation models / LBMs: policy mapping (obs / state, goal) → action without explicit state / transition.
- Timeline: RT-1 Dec 2022 → RT-2 Jul 2023 → RT-X Oct 2023 (1M episodes / 22 embodiments / 527 skills / 311 scenes / 34 labs) → OpenVLA Jun 2024 = Llama2-7B + DINOv2 + SigLIP + 7-DoF de-tokenizer → pi-Zero Oct 2024 by Physical Intelligence with cross-embodiment dataset + zero-shot / specialized / efficient post-training tracks, open-sourced as
openpiFeb 4 2025 → Helix Figure / Hi-Robot PI / Gemini Robotics / GR00T Nvidia / DYNA-1.- Remaining challenges: eval is costly + noisy with weak training-loss correlation (ALOHA 2 fleet) and sim-to-real gap (no “ImageNet of embodied AI”; BEHAVIOR / Habitat 3.0 candidates), foundation policy <→ foundation world model (action-conditioned future prediction, DayDreamer / Nvidia Cosmos / 1X).
- VLM / LLM not tailored for embodiment (“RL from human feedback” → “RL from embodied feedback”; SAM / DINOv2 closer than GPT), adaptation / lifelong (BEHAVIOR-1K preference rank), system-level: Helix two-system 7B-VLM-at-7-9Hz GPU2 + 80M-Transformer-at-200Hz GPU1 vs Hi-Robot high-VLM emits low-level language commands to low-VLA.
Lec 18 — 3D Vision Follow-Up
- Depth, voxels, point clouds, meshes, NeRF variants, Gaussian splatting, and 3D foundation models.
Detailed coverage
- 3D Vision (slides credit Justin Johnson, presented by Fei-Fei Li / Ehsan Adeli / Chen Wang, Jun 4, 2024 — 2024 deck used as substitute since 2025 Human-Centered AI deck was not posted).
- Recall 2D detection / segmentation hierarchy + video as 4D tensor; Multi-View CNN (Su ICCV 2015 — render N views → shared CNN1 → element-wise max-pool over views → CNN2 → softmax, about 90% ModelNet40).
- 5-representation taxonomy: Implicit Surface.
- 2.5D: Depth maps (Eigen+Fergus ICCV 2015, scale-invariant loss to handle scale ambiguity) + surface normals (cosine loss ).
- Voxels: 3D ShapeNets pipeline ( 6^3 / 5^3 / 4^3 conv → FC → class), 3D-R2N2 (Choy ECCV 2016, 2D CNN + 3D CNN decoder + per-voxel CE), float32 = 4 GB memory wall, OGN octree (Tatarchenko ICCV 2017) at .
- Point clouds: Point Set Generation (Fan CVPR 2017, FC + conv heads with Chamfer loss ), PointNet applications (classification / semantic seg / part seg), DenseFusion (Wang CVPR 2019, RGB CNN per-pixel feat + PointNet per-point feat → project & concat → 6D pose).
- Triangle meshes: Pixel2Mesh (Wang ECCV 2018: ellipsoid template → iterative refinement 156 → 628 → 2466 verts, graph conv , vertex-aligned features via bilinear-sampled CNN feats
conv3_3/4_3/5_3, Chamfer loss on mesh → pointcloud sampling), Mesh R-CNN (Gkioxari ICCV 2019, mesh head on Mask R-CNN).- Implicit surfaces (Ren Ng CS184/284A slides): algebraic surfaces (zero set of poly), CSG ( trees on primitives), level sets (grid + trilinear interp where ), DeepSDF (Park CVPR 2019).
- NeRF variants: Nerfies (Park ICCV 2021 deformable), RawNeRF (Mildenhall CVPR 2022 HDR), BlockNeRF (Tancik CVPR 2022 SF tiling), cost: 1-2 days V100 train + 14.6M MLP forwards per render at 224 samples / pixel.
- 3D Gaussian Splatting vs NeRF: continuous MLP-along-ray vs blend-discrete-Gaussians-along-ray, hours → minutes fitting + 10s / frame → real-time render, Dynamic 3D Gaussians (Luiten 3DV 2024) + Gaussian Splatting SLAM (Matsuki CVPR 2024).
- Foundation models for 3D: DreamFusion (Poole arXiv 2022, Score Distillation Sampling: optimize NeRF so renders match 2D text-to-image diffusion model), CAT3D (Gao arXiv 2024, multi-view diffusion → fit 3D).
Lessons
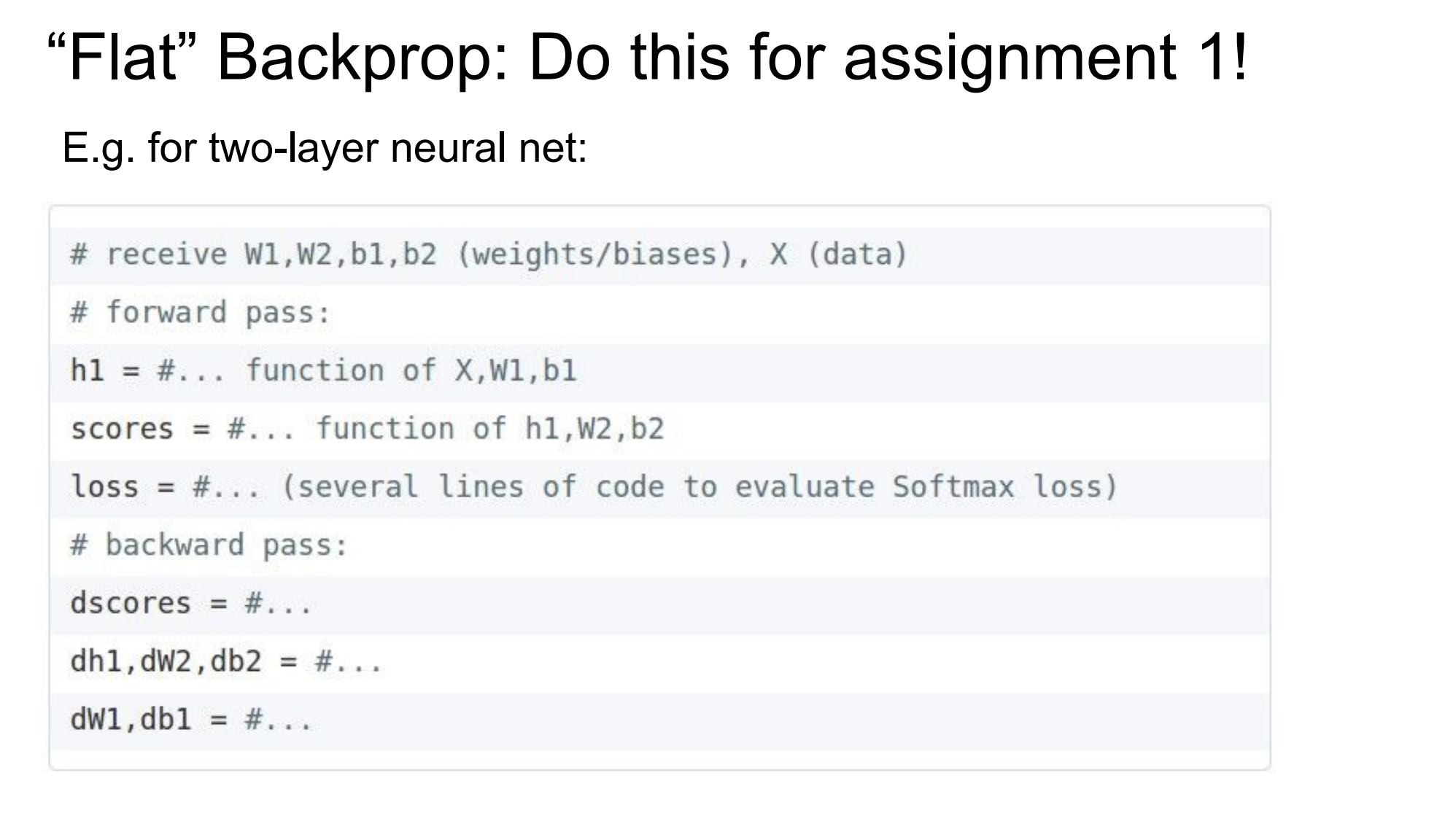
- Stage your forward and backward pass. I did not do this super well, but it would make the code much more readable in the future.
Screenshots
Forward / backward pass reference:
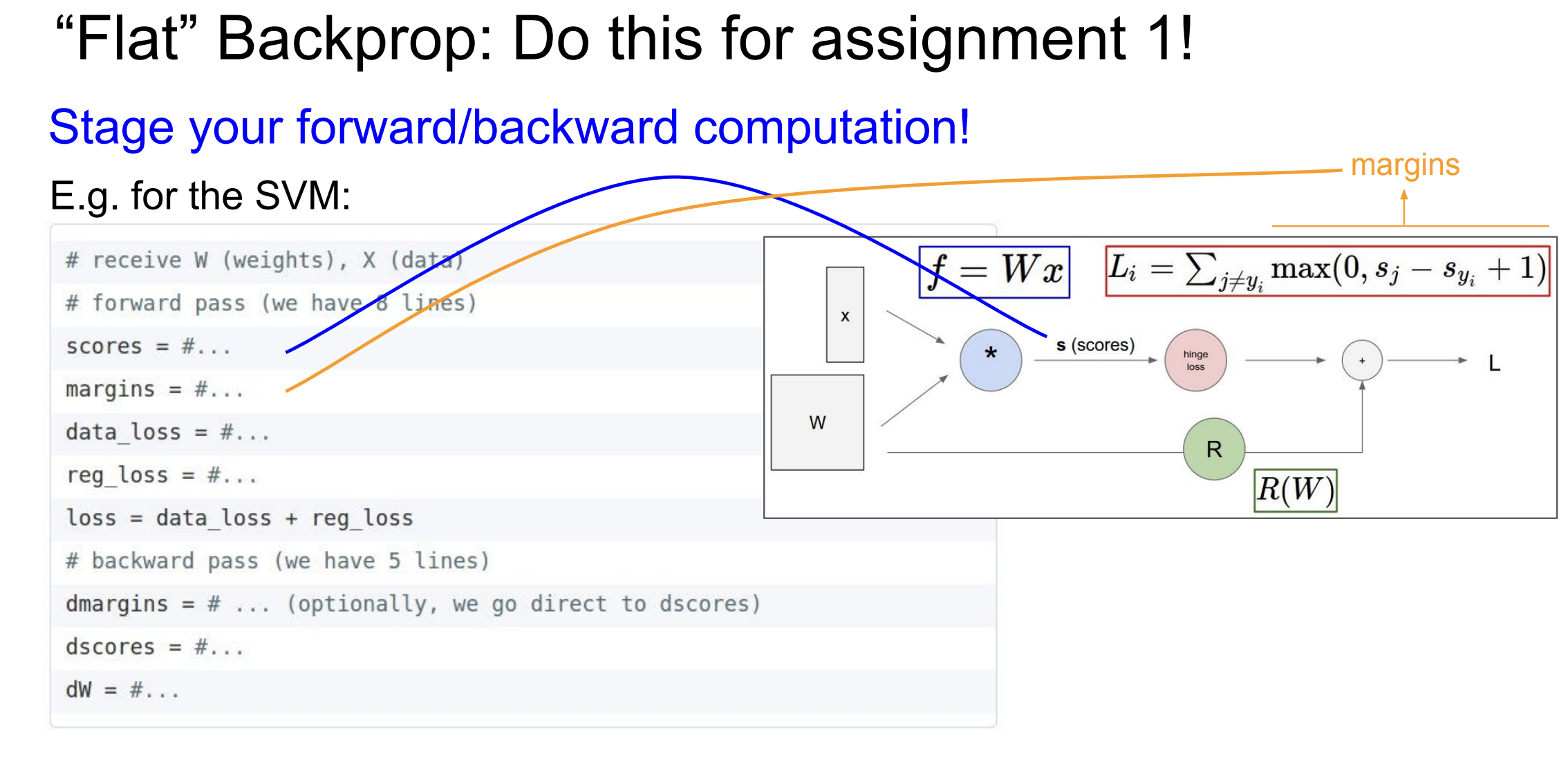
Additional reference: