DINO
I need to actually understand how DINO works https://github.com/facebookresearch/dino
Takes inspiration from BYOL, operates with different similarity matching loss, but exact same architecture for student-teacher.
Like you know how object detection feels basically solved?
Resources
Walkthrough (CS231n 2025 Lec 12)
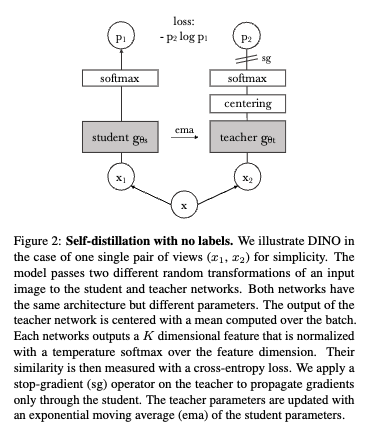
DINO = “self-DIstillation with NO labels”. No explicit negatives, no contrastive loss — a teacher-student setup where the student learns to match the teacher’s output distribution on different views of the same image.
Architecture
- Student and teacher — same architecture (ViT in the DINO paper), different parameters.
- Teacher is an EMA of the student: . No backprop into the teacher — gradient
sg(stop-grad) on the teacher branch. - Both produce a -dimensional output that gets softmaxed into a probability distribution over “prototypes” (no classes — the dimensions are just a learned codebook).
Loss
Draw two augmented views of the same image. Cross-entropy each way:
where (teacher, centered + sharp) and (student).
Why it doesn’t collapse
Without care, the student can collapse to outputting a constant (matching a constant teacher trivially). DINO prevents this with two tricks on the teacher:
- Centering. Subtract a running mean from teacher logits, . Prevents any single dimension from dominating.
- Sharpening. Use a low teacher temperature . Makes the teacher’s output peaked, which pushes the student toward sharper, non-uniform distributions.
Centering alone → uniform collapse. Sharpening alone → one-dim collapse. Together they balance.
Pseudocode (Lec 12 slide 105)
gt.params = gs.params
for x in loader:
x1, x2 = augment(x), augment(x)
s1, s2 = gs(x1), gs(x2)
t1, t2 = gt(x1), gt(x2)
loss = H(t1, s2)/2 + H(t2, s1)/2
loss.backward()
update(gs) # SGD
gt.params = l * gt.params + (1-l) * gs.params # EMA
C = m * C + (1-m) * cat([t1, t2]).mean(dim=0) # center
def H(t, s):
t = t.detach() # stop-grad
s = softmax(s / tps, dim=1)
t = softmax((t - C) / tpt, dim=1) # center + sharpen
return -(t * log(s)).sum(dim=1).mean()Emergent property: unsupervised segmentation
The headline result: the [CLS] token’s self-attention on the last layer of a DINO-trained ViT produces clean object segmentation masks — without any segmentation supervision. ViT 8×8 patches trained with DINO attend exactly to the salient object in the scene. Supervised ViTs don’t do this.
Performance: ViT-Base with DINO → 80.1% ImageNet linear eval (strong). Small ViT with DINO → 78.3% top-1 via k-NN classification of frozen features (no linear head needed).
DINO v2 (Oquab et al. 2023)
Scaled recipe — bigger model, bigger curated dataset. Key emergent property: patch-level features from DINOv2 cluster into semantic parts across images (PCA of patch features matches “wings”, “body”, “wheels” across different pose/style/object instances).
Source
CS231n 2025 Lec 12 slides ~103–106 (DINO architecture diagram, loss, centering+sharpening, PyTorch pseudocode, DINOv2 PCA figure).