Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (ALOHA)
Led by Mr. Tony Zhao.
- https://tonyzhaozh.github.io/aloha/
- https://mobile-aloha.github.io/
- https://aloha-2.github.io/
- https://aloha-unleashed.github.io/
Papers
Related
Main contributions of the paper:
- Introducing the concept of action chunking to reduce the compounding error problem
“Addressing compounding errors. A major shortcoming of BC is compounding errors, where errors from previous timesteps accumulate and cause the robot to drift off of its training distribution, leading to hard-to-recover states”
- This is due to the autoregressive nature of the models

- So the trajectory goes more and more out of distribution
That’s why Action chunking can help, so it reduces the effective horizon of the task by “k”-fold.
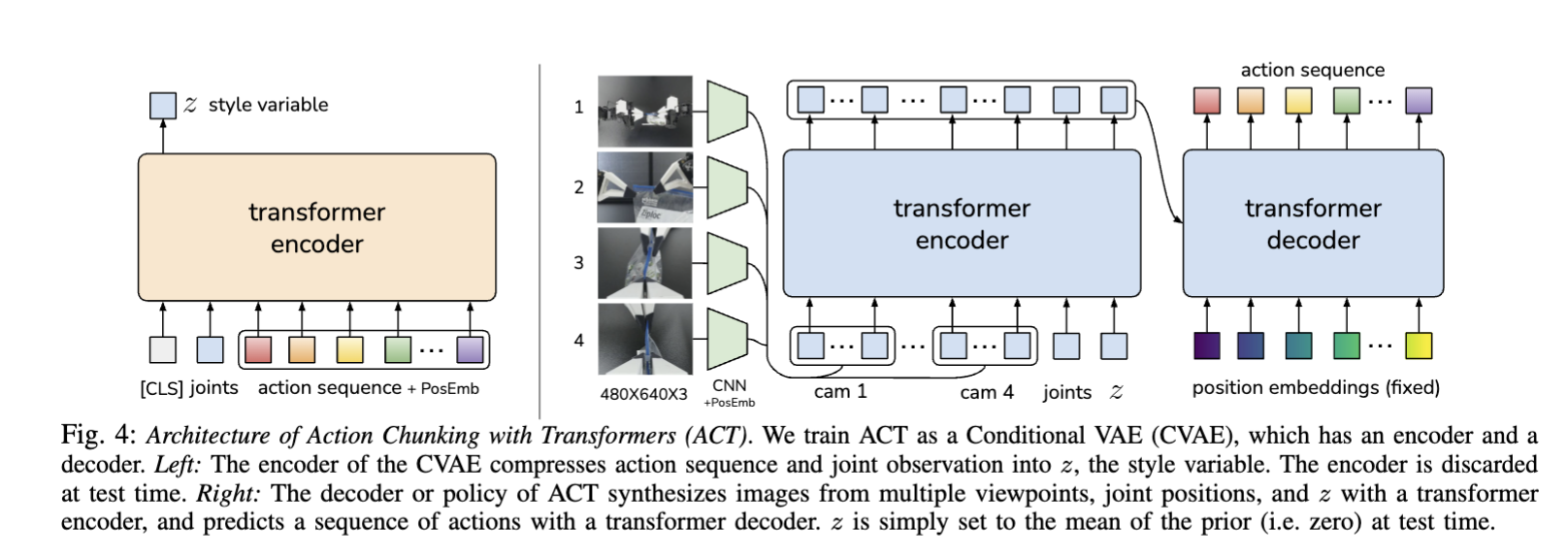
ACT is trained as a cVAE
Links
Resources
So what is action chunking? Action chunking is a technique in robotics and imitation learning where, instead of predicting and executing one action at a time, a robot forecasts and carries out a sequence of actions—referred to as a “chunk”—based on its current observation.
Benefits of action chunking (reference blog):
- Allows your model to control your robot at a much higher frequency given a large model
- You of course don’t get the reactivity, but that’s a bonus
- Better temporal consistency without having to do Proprioceptive History
“Generally, the more information is contained in the observation space, the more likely causal confusion will happen for imitation learning.”