Segment Anything (SAM)
https://docs.ultralytics.com/models/fast-sam/#example-usage
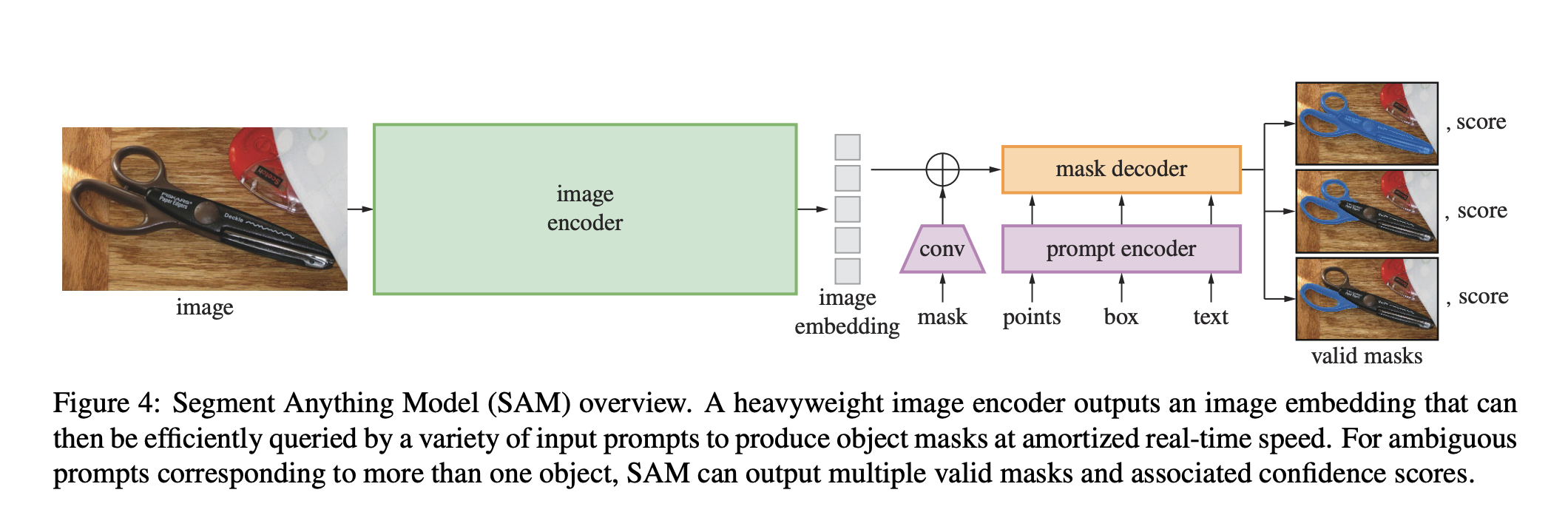
Walkthrough (CS231n 2025 Lec 16)
What changed vs prior segmentation
Pre-SAM segmentation models (e.g. Mask R-CNN trained on COCO) recognize a fixed 80-category vocabulary. SAM is trained on a much larger category set and outputs a mask of whatever object the user prompts for. Two questions to answer:
- How to get this? (i.e. how do you cover such diverse categories at training time)
- How to know this? (i.e. how does the model know which object the user wants)
The answer to the second is prompts: a point, a box, a coarse mask, or a text query.
Architecture
- Image encoder (heavy ViT) — runs once per image and is cached.
- Prompt encoder (lightweight) — encodes points / boxes / masks / text into prompt tokens.
- Mask decoder (lightweight transformer) — fuses image embedding + prompt tokens, outputs mask + confidence.
The asymmetric heavy-image / light-prompt split is what makes interactive use feel real-time: the image embedding is computed once, then any number of prompts are decoded cheaply.
Ambiguity (the key trick)
A point near scissors could mean “the scissors handle,” “the whole scissors,” or “scissors + the surface.” SAM outputs 3 valid masks per prompt with confidence scores. During training, the loss is computed only against the best-matching ground-truth mask out of the 3 — so the model learns to spread its outputs across plausible interpretations rather than averaging them into mush.
SA-1B dataset
1B+ masks across 11M licensed, privacy-respecting images. vs OpenImages V5: 6× more images, 400× more masks. Built with a data engine: model annotates images → humans correct → retrain → repeat. Bootstraps from a small seed of human masks to a billion-scale auto-labeled dataset.
Zero-shot range
Works out-of-distribution on bacteria images, Van Gogh paintings, dense produce piles, umbrellas in crowds — categories not even hinted at in training. This is what gets it grouped with foundation models.
Source
CS231n 2025 Lec 16 slides ~112–131 (prompt-based segmentation, image+prompt encoder + mask decoder, ambiguity → 3 masks + confidence + best-mask loss, SA-1B vs OpenImages, data engine, zero-shot examples).