CUDA Memory
http://thebeardsage.com/cuda-memory-hierarchy/
Introduced well in Chapter 4 of PMPP book.

- Each block is guaranteed to be executed on an SM
There are 3 different kinds of memory (from fastest to slowest)
- Registers
- CUDA Shared Memory (small but fast)
- CUDA Global Memory (large but slow)
Constant Memory
In the diagram, there seems to be constant memory. But constant memory is just global memory with caching. See CUDA Constant Memory.
All processors find their roots in Von Neumann Architecture, and CUDA is no exception.

Why are registers faster than global memory?
Register Assembly Code
fadd r1, r2, r3Global memory Assembly Code
load r2, r4, offset fadd r1, r2, r3
- Notice that the memory needs to be loaded first for global memory
The CUDA version of the Von Neumann
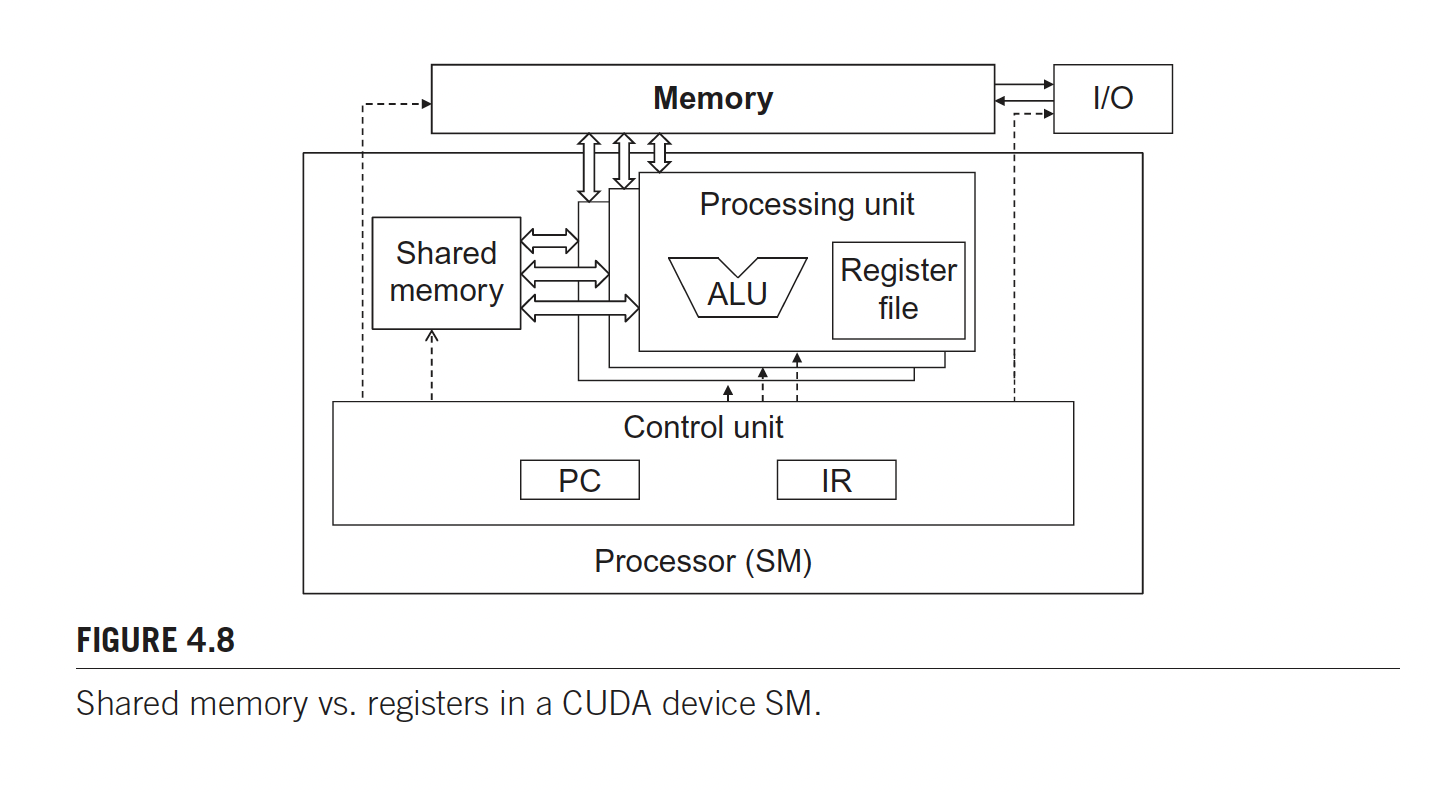
So where does shared memory come in?
Shared memory data are accessible by all threads in a block, whereas register data are private to a thread.
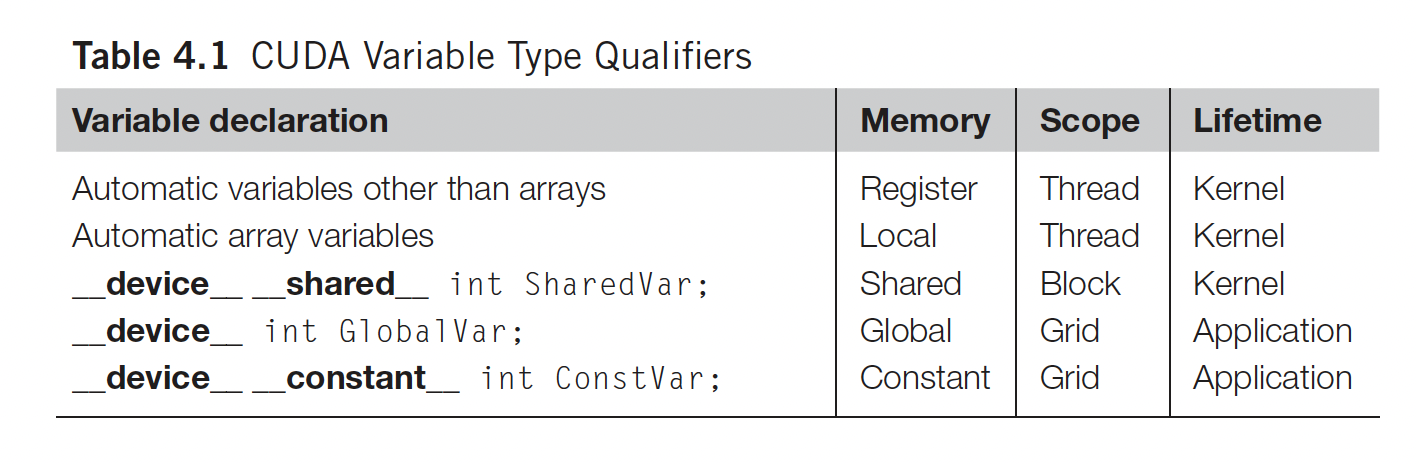
All automatic scalar variables declared in kernel and device functions are placed into registers.
Scope
The scopes of these automatic variables are within individual threads.
Automatic array variables are stored into the CUDA Global Memory and may incur long access delays and potential access congestions.
So there are 3 (+1) kinds of variables
- Automatic Variables
- CUDA Shared Variable (
__shared__) - CUDA Global Variable (anything outside of a cuda kernel)
- CUDA Constant Variable (
__constant__)

Tiling is the COOLEST thing ever.
How is
cudaMemcpyimplemented under the hood?Modern GPUs have sophisticated DMAs to handle copying between the CPU and GPU memory.