Programming Massively Parallel Processors (PMPP)
Taking notes from this book to fundamentally learn CUDA and hardware acceleration.
Recommendation by Anne Ouyang. I started with the 3rd edition but moved to the latest 4th edition.
Available locally at file:///Users/stevengong/My%20Drive/Books/GPU-Teaching-Kit-Accelerated-Computing/Wen-mei%20W.%20Hwu,%20David%20B.%20Kirk,%20Izzat%20El%20Hajj%20-%20Programming%20Massively%20Parallel%20Processors.%20A%20Hands-on%20Approach-Elsevier%20(2023).pdf
3rd edition file:///Users/stevengong/My%20Drive/Books/GPU-Teaching-Kit-Accelerated-Computing/EBook%20PMPP%203rd%20Edition.pdf
Quesitons to answer
- How does warp scheduling work with 2D blocks? I see 16x16 block sizes being used, which is 256 threads, but warps are contiguous with 32 threads, so how do things work?
Chapter 1
Sequential programs are the standard paradigm. But you really can’t make them run faster.
CPU are designed to minimize execution latency on a single thread, through cache.
GPUs are throughput machines.
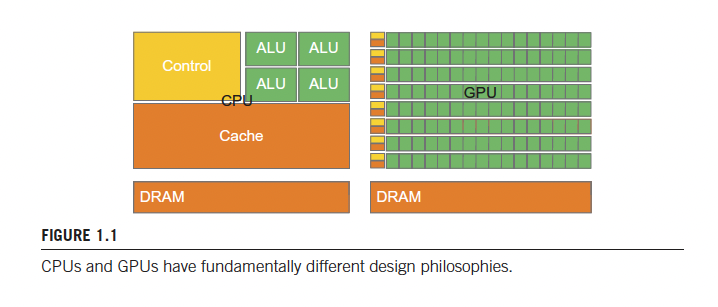
“Until 2006, graphics chips were very difficult to use because programmers had to use the equivalent of graphics application programming interface (API) functions to access the processing units, meaning that OpenGL or Direct3D techniques were needed to program these chips. Stated more simply, a computation must be expressed as a function that paints a pixel in some way in order to execute on these early GPUs.”
- This is what it feels like to be working with Apple’s Metal Shading Language
Why is parallel programming hard? (sect 1.5)
- Designing parallel algorithms with the same algorithmic complexity as sequential programs can be hard
- Execution speed limited by memory access speed
- Input data can be varied
- Real-world is often filled with mathematical recurrences, which are hard to parallelize (think like a Markov Chain or Markov Decision Process)
Chapter 2
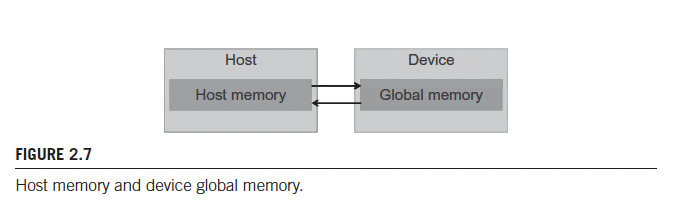
- Device memory and global memory are used interchangeably
Fundamental functions:
cudaMalloc()cudaFree()cudaMemcpy()
When using cudaMemcpy in CUDA programming, it is crucial to specify the correct direction of memory transfer:
cudaMemcpyHostToHost: Copies memory between two locations in the host’s memory.cudaMemcpyHostToDevice: Copies memory from host to device.cudaMemcpyDeviceToHost: Copies memory from device to host.cudaMemcpyDeviceToDevice: Copies memory between two locations in the device’s memory.
If the wrong direction is specified, CUDA runtime API will return an error of type cudaErrorInvalidMemcpyDirection. This error indicates that the direction of the copy does not match the provided source and destination pointers. Here’s what happens

Chapter 3
I need to better understand how these threads are organized from a hardware perspective. So you can do cache-aware programming.
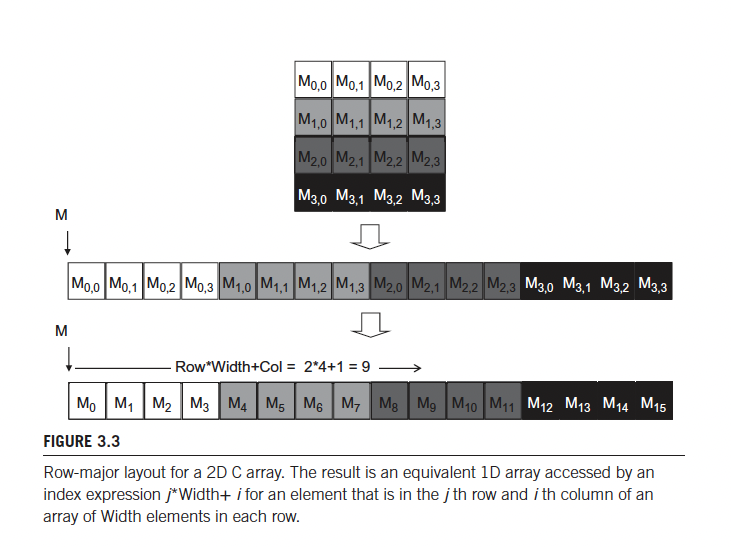
- Row major layout
They start out with an example of how they would process a black and white image.
dim3 dimGrid(ceil(m/16.0), ceil(n/16.0), 1);
dim3 dimBlock(16,16,1);
colorToGreyscaleConversion<<<dimGrid, dimBlock>>>(d_Pin, d_Pout,m,n);How is d_Pin and d_Pout allocated?
- There is
cudaMallocPitch, but I’m not sure they do that
The function call
#define CHANNELS 3
// input image is encoded as unsigned characters [0,255]
__global__
void colorToGrayscaleConversionKernel(unsigned char *Pin, unsigned char *Pout, int width, int height) {
int Col = blockDim.x * blockIdx.x + threadIdx.x;
int Row = blockDim.y * blockIdx.y + threadIdx.y;
if ( Col < width && Row < height) {
// get 1D coordinate for the grayscale image
int greyOffset = Row * width + Col;
// one can think to RGB image having
// CHANNEL times columns than the grayscale image
int rgbOffset = greyOffset * CHANNELS;
unsigned char r = Pin[rgbOffset ]; // red value for pixel
unsigned char g = Pin[rgbOffset + 1]; // green value for pixel
unsigned char b = Pin[rgbOffset + 2]; // blue value for pixel
// perform the rescaling and store it
// we multiply by floating point constants
Pout[grayOffset] = 0.21f*r + 0.71f*g + 0.07f*b;
}Synchronization is done through ___syncthreads().
I am introduced to Barrier Synchronization
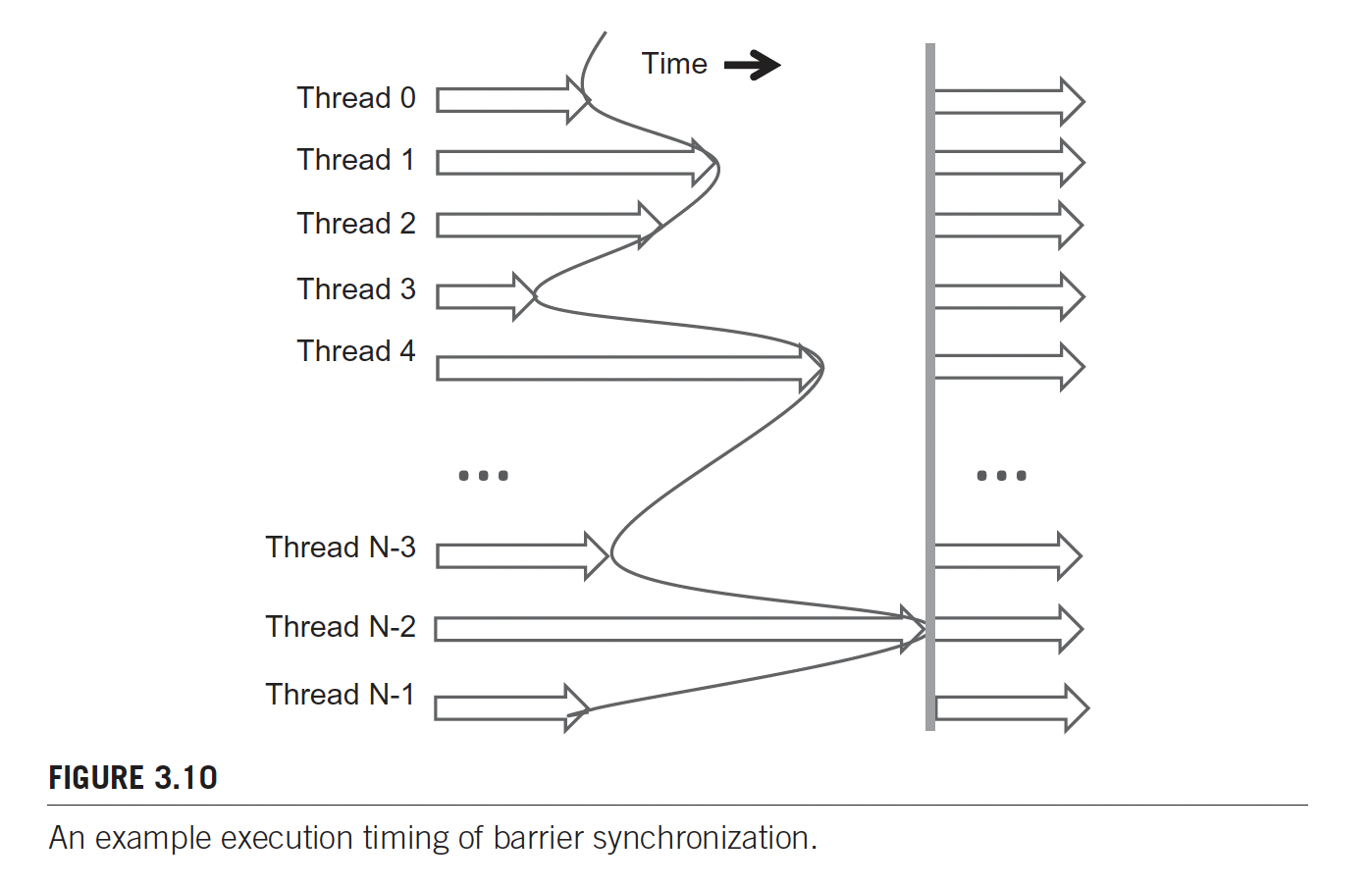
This is fundamental:
implementation.
Warps contain consecutive threads!
Each warp consists of 32 threads of consecutive
threadIdxvalues: thread 0-31 from the 1st warp, 32-63 for the 2nd warp, etc.
Chapter 4
This is the most fundamental chapter, since it talks about memory access. How do you position data for efficient access by a massive number of threads?
Memory-Bound Program
Memory-bound programs are programs whose execution speed is limited by memory access throughput.
One of the fundamental concept is the compute-to-global-memory-access ratio.
Memory is expensive
Compute is a lot faster than memory access, so you want this number to be as high as possible.
They motivate this through matrix multiplication.
__global__ void MatrixMulKernel(float* M, float* N, float* P,
int Width) {
// Calculate the row index of the P element and M
int Row = blockIdx.y*blockDim.y+threadIdx.y;
// Calculate the column index of P and N
int Col = blockIdx.x*blockDim.x+threadIdx.x;
if ((Row < Width) && (Col < Width)) {
float Pvalue = 0;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < Width; ++k) {
Pvalue += M[Row*Width+k]*N[k*Width+Col];
}
P[Row*Width+Col] = Pvalue;
}
}The above is slow
Every single time you are reading into
M[...],N[...], orP[...], that is a read from global memory.
EXERCISE: Calculate the compute-to-memory-acess ratio. It is 1.0
Fundamental question to answer
Is memory access done per thread, per block, or per warp?
- It seems to be done per warp basis. More of this is covered in Chapter 5
Chapter 6: Performance Considerations
Fundamental notes are taken in CUDA Memory.
See Tiling for a faster implementation.
When all threads in a warp execute a load instruction, the hardware detects whether they access consecutive global memory locations.
Favorable access pattern
The most favorable access pattern is achieved when all threads in a warp access consecutive global memory locations.
The hardware coalesces all these accesses in a consolidated access to consecutive DRAM locations, more notes in Memory Coalescing.
The question is: how do we effectively use the coalescing hardware?
Also, in the code, if you don’t do Tiling, how are the reads avoided in every thread call? And what if you have a memory write?
So adding two matrices for example
__device__ add(float* d_A, float* d_B, float* d_C, int height, int width) {
int row = threadIdx.y + blockIdx.y * blockDim.y;
int col = threadIdx.x + blockIdx.x * blockDim.x;
d_C[row * width + col] = d_A[row * width + col] + d_B[row * width + col];
}I think the example they are giving is if you are doing a for loop.
5.2. Memory Parallelism
The most fundamental thing to understand is the interaction between parallel thread execution and parallel memory organization.
They talk about memory parallelism, and there are 3 forms of parallel organization:
- DRAM bursting enables Memory Coalescing
- DRAM banks
- DRAM channels
DRAM Channel
Each channel is a memory controller with a bus that connects a set of DRAM banks to the processor.

- This is called interleaved data distribution, where the elements are spread across the banks and channels in the system.
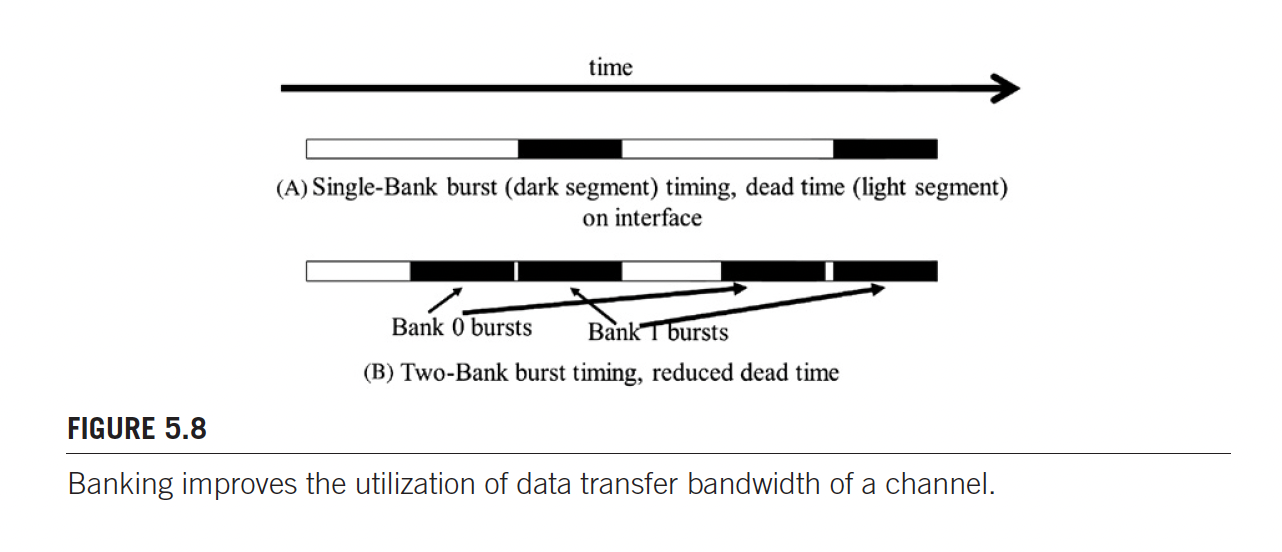
- white color = access latency
- black color = data transfer
Notice that the memory read access is much longer that data transfer.
For this reason, we make use of banks.
When two banks are connected to a channel bus, an access can be initiated in the second bank while the first bank is serving another access.
5.3. Warps and SIMD Hardware
They talk about Control Divergence.
For 1D blocksize, warp starts with thread and ends with thread .
For blocks that consist of multiple dimensions of threads, the dimensions will be projected into a linearized row-major order before partitioning into warps.
- The linear order is determined by placing the rows with larger y and z coordinates after those with lower ones.
- Form the linear order by placing all threads whose
threadIdx.yis 1 after those whosethreadIdx.yis 0. Threads whosethreadIdx.yis 2 will be placed after those whosethreadIdx.yis 1, and so on.
Chapter 7: Convolution
I basically want to take whatever they teach here, and implement it.
Simple Code for 1D Convolution
__global__ void convolution_1D_basic_kernel(float *N, float *M,
float *P, int Mask_Width, int Width) {
int i = blockIdx.x*blockDim.x + threadIdx.x;
float Pvalue = 0;
int N_start_point = i - (Mask_Width/2);
for (int j = 0; j < Mask_Width; j++) {
if (N_start_point + j >= 0 && N_start_point + j < Width) {
Pvalue += N[N_start_point + j]*M[j];
}
}
P[i] = Pvalue;
}Two observations about the above code:
- There is Control Flow Divergence due to the if statement
- Bad Compute-to-global-memory-access ratio