Convolution (Image Processing)
Not to be confused with Convolution (Signal Processing) (though really, they are the same idea!).
Convolution is just matrix multiplication.
I MUST watch this 3Blue1Brown video about convolution:
- https://www.youtube.com/watch?v=KuXjwB4LzSA&ab_channel=3Blue1Brown
- https://www.youtube.com/watch?v=agYZcJNmbsU&ab_channel=DanielGordon
This operation is applying a filter/kernel of , which reduces the original matrix to .
Remember the Andrew Ng example: Vertical Edge detector by applying a filter, common is
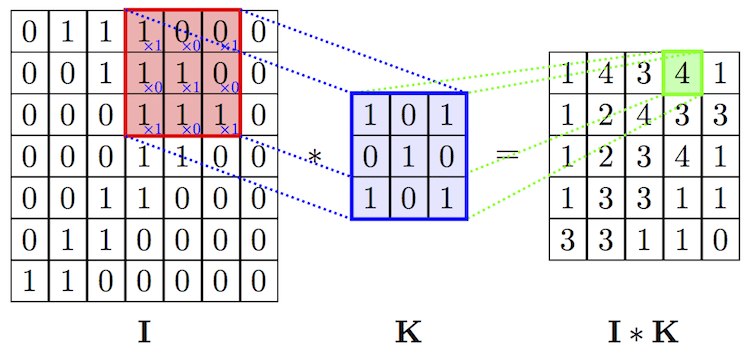 The filter operation: Multiply each element, and them sum the values to produce a smaller size output.
The filter operation: Multiply each element, and them sum the values to produce a smaller size output.
The convolution operation gives you a convenient way to specify how to find these vertical edges in an image. Different filters allow you to find vertical and horizontal edges.
Different Filters:
- Sobel Filter
- Schorr Filter
These filters are square, i.e.
Before the age of NN, CV researchers would hand select these filters. But with CNN, the NN can automatically learn the weights of these filters to best detect the features.
Treating the numbers of the filters as parameters to be learned has been one of the most powerful ideas in computer vision.
Padding
https://d2l.ai/chapter_convolutional-neural-networks/padding-and-strides.html
Your image shrinks every time you apply convolution. We apply padding for the features on the side to ensure the output is the same size as the input.
The padding is , where is the filter size and it is odd-numbered (by convention in CV).
Strided Convolution
You can also make strides, which jumps a stride before each filter application.
Final size: floor()
Note
If you read the CV, sometimes before applying convolution, you do the flip before doing the convolution, and that gives some good properties. For in ML, we don’t need this property, and what we are actually doing is cross-correction, but in the ML literature, other people just call it convolution.
https://d2l.ai/chapter_convolutional-neural-networks/padding-and-strides.html
Convolution Over Volume / RGB Image
You can have a 3D edge detection by having it 3x3x3, RGB image is just split into 3 channels, so its a 3D matrix.
Notations
Conv layer takes 4 parameters:
- = Number of filter
- = filter/kernel size
- = padding
- = stride
Implementation of Convolution
Convolution is slow, the naive implementation. So there are techniques https://towardsdatascience.com/how-are-convolutions-actually-performed-under-the-hood-226523ce7fbf
This video from CS231N also covers it: https://www.youtube.com/watch?v=pA4BsUK3oP4&list=PLkt2uSq6rBVctENoVBg1TpCC7OQi31AlC&index=11&ab_channel=AndrejKarpathy
Krish says im2col is how it is implemented under the hood
Interview from Matician
I was interviewed by them to implement convolution, and I failed miserably.
- This solution is not as fast as it could have been.
- Didn’t delete allocated memory.
- Array of array allocates each row in a different memory location, this breaks cpu cache lines for every row access. A much faster way (esp for bigger rows and cols values) is to allocate one vector but then view it as
[i*cols + j]indices. - Since the unsigned number max range is [0, 255], the results could have been stored in int16 type vectors.
Notes from Cyrill Stachniss


Properties of Convolutions
Convolution is commutative
I skipped the rest of the part. The important details, I checked the other.
Other Things
The difference between kernel and filter is not so clear.
- When you say kernel, it generally refers to the mathematical matrix used for the convolution operator
- When you say filter, it generally a more user-friendly term for image processing tasks.
Filter vs. kernel vs. operator?
I often see those terms used interchangeably.
Both terms, filters and operators, are used in image processing but they are not entirely interchangeable. Filters generally refer to transformations that modify the frequency content or smooth out noise. Operators often refer to transformations that compute a new value for a pixel based on its neighbors, like edge detection.
This distinction is important to know for my VR Headset from scratch.