Hadoop Distributed File System (HDFS)
HDFS is a very large distributed file system (10k nodes, 100 million files, 10PB).
How does this relate to S3 buckets?
??
it assumes commodity hardware.
Hardware Implementation
Just do Database Sharding
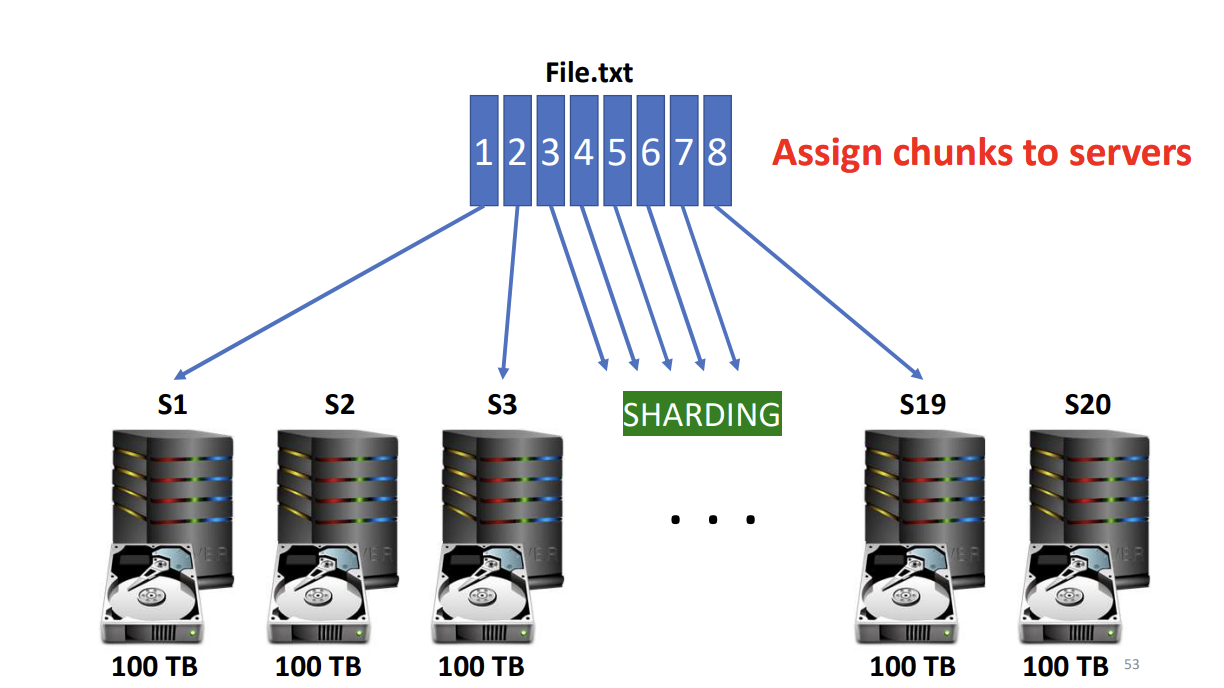
There’s a data coherency problem.
Data coherency
- Write-once-ready-many access model
- Client can only append to existing files
Logbook style.
Files are broken up into blocks (typically 64MB - 128MB block sizes)
- Feels related to how Paging works
HDFS Namenode
This feels like the lookup table that we had → Message Broker. No, more like a Connection Broker
Heart beat message?
The teacher talked about how there’s only 1 namenode. And then there’s a backup namenode if it goes down. Wouldn’t it be better to deploy a cluster of namenodes?
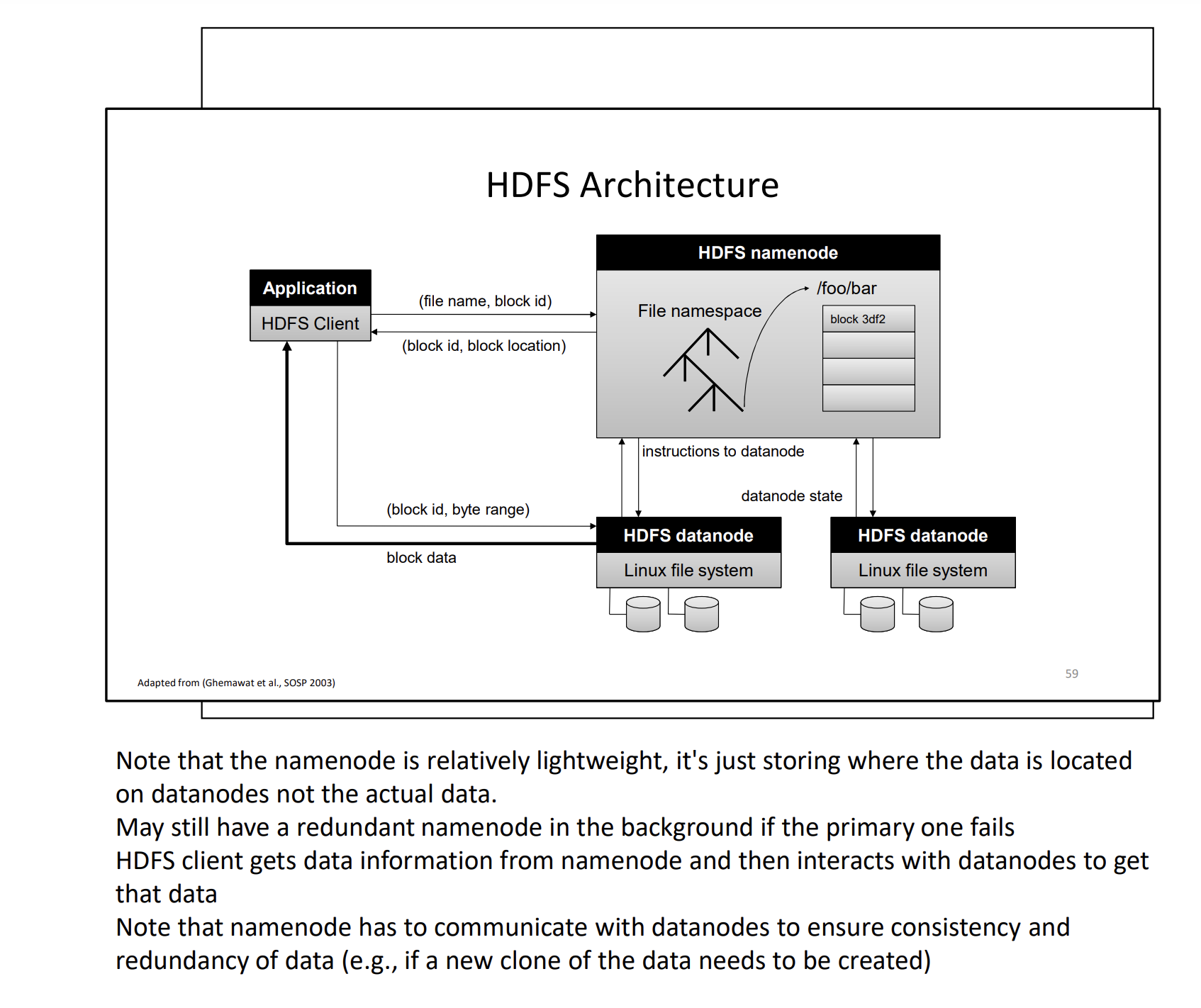
HDFS Datanode
A block server
- Stores data in the local file system
- Stores metadata of a block
- Serves data and metadata to clients
Block Placement Policy
3 replicas will be stored on at least 2 racks
The things that do mapreduce are datanodes.
Replication
The Namenode detects datanode failures. If there are failures, it:
- Chooses new datanodes for new replicas
- Balances disk usage
- Balances communication traffic to datanodes