Resilient Distributed Dataset (RDD)
RDDs allow us to write programs in terms of operations on distributed datasets.
Learned in CS451.
How is RDD different from HDFS?
HDFS is a distributed file system designed to store data across a cluster (so primarily for data storage).
RDD is a processing abstraction for performing distributed computation, optimized for in-memory operations.
- HDFS provides the persistent data layer, while RDD offers the high-performance computation layer.
This is why you load data from hdfs with RDD:
lines = spark.textFile("hdfs://...")linesis a RDD
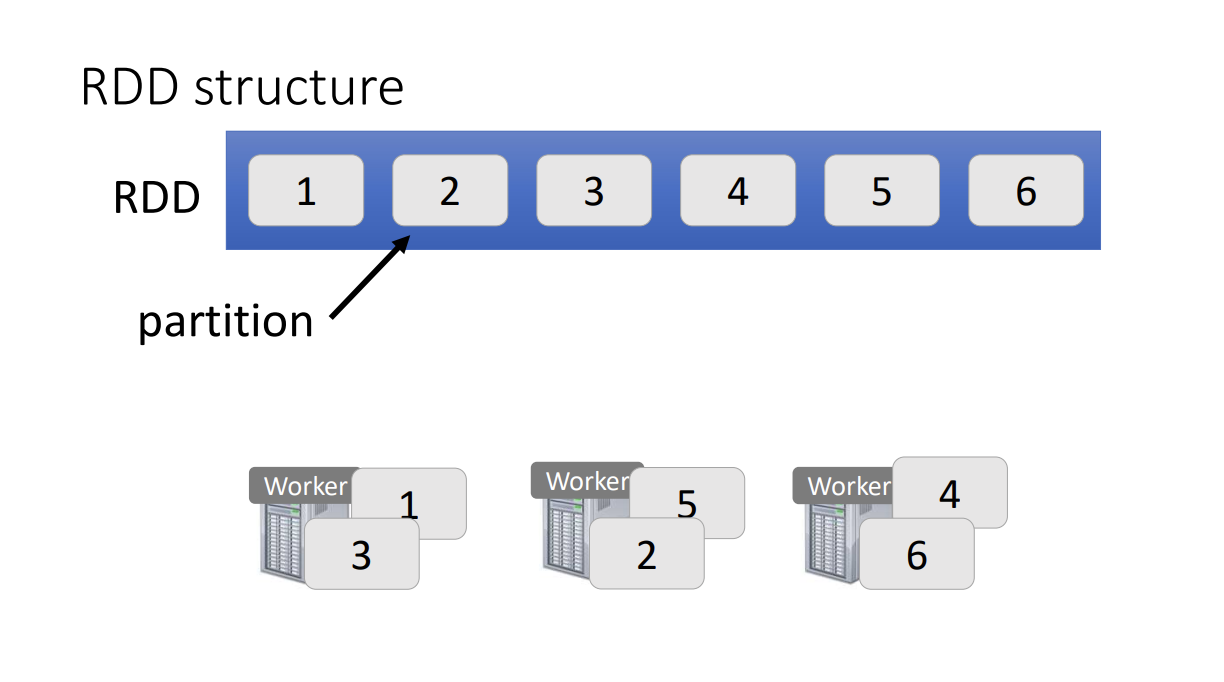
Properties:
- Collections of objects spread across a cluster, stored in RAM or on Disk
- Built through parallel transformations
- Automatically rebuilt on failure
Operations
- Transformations (e.g. map, filter, groupBy)
- Actions (e.g. count, collect, save)
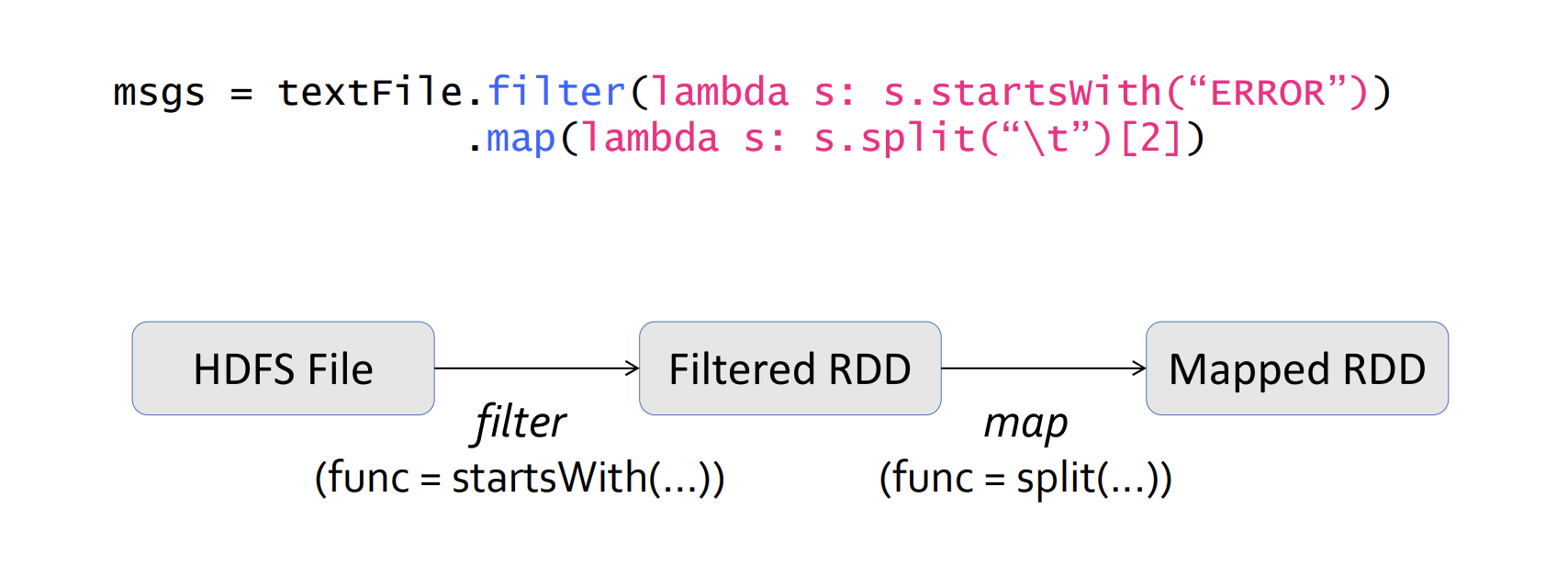
lines = spark.textFile("hdfs://...")
errors = lines.filter(lambda s: s.startswith("ERROR"))
messages = errors.map(lambda s: s.split("\t")[2])
messages.cache() # this caches the messages
messages.filter(lambda s: "mysql" in s).count()
messages.filter(lambda s: "php" in s).count()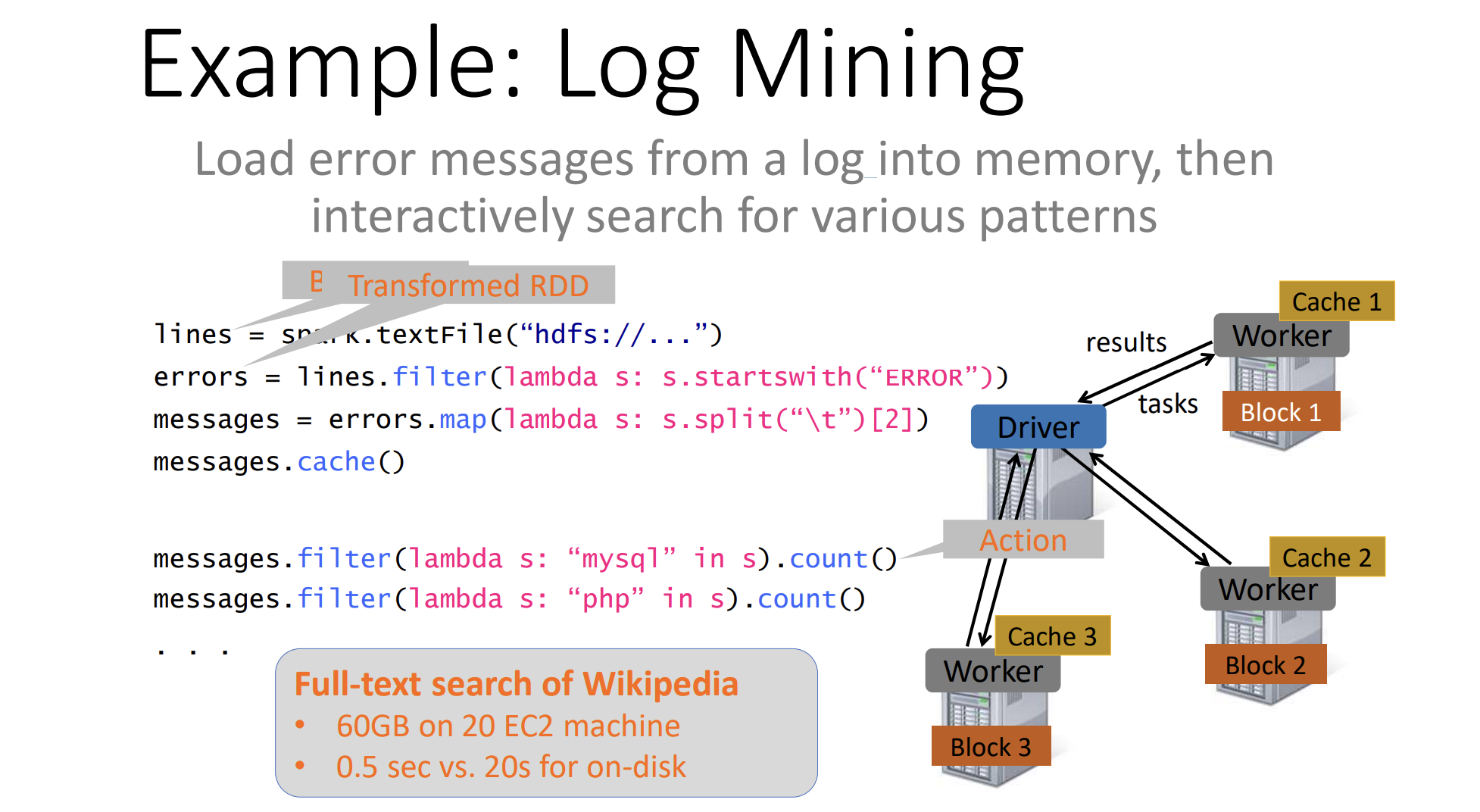
Always cache the branching point.
Fault Recovery
RDDs track lineage information that can be used to efficiently recompute lost data.
Creating RDDs
# Turn a Python collection into an RDD
sc.parallelize([1, 2, 3])
# Load text file from local FS, HDFS, or S3
sc.textFile("file.txt")
sc.textFile("directory/*.txt")
sc.textFile("hdfs://namenode:9000/path/file")Basic Transformations
nums = sc.parallelize([1, 2, 3])
# Pass each element through a function
squares = nums.map(lambda x: x*x) // {1, 4, 9}
# Keep elements passing a predicate
even = squares.filter(lambda x: x % 2 == 0) // {4}
# Map each element to zero or more others
>nums.flatMap(lambda x: => range(x))
# => {0, 0, 1, 0, 1, 2}Basic Actions
nums = sc.parallelize([1, 2, 3])
# Retrieve RDD contents as a local collection (not used often)
nums.collect() # => [1, 2, 3]
# Return first K elements
nums.take(2) # => [1, 2]
# Count number of elements
nums.count() # => 3
# Merge elements with an associative function
nums.reduce(lambda x, y: x + y) # => 6
# Write elements to a text file
nums.saveAsTextFile("hdfs://file.txt")Counts
nums.count()→ this makes each worker count, and then the driver just add it uplen(nums.collect())→ this makes the driver count it
Working with key-value pairs:
pets = sc.parallelize([("cat", 1), ("dog", 1), ("cat", 2)])
pets.reduceByKey(lambda x, y: x + y) # => {(cat, 3), (dog, 1)}
pets.groupByKey() # => {(cat, [1, 2]), (dog, [1])}
> pets.sortByKey() # => {(cat, 1), (cat, 2), (dog, 1)}NOTE: You can write pets.reduceByKey(_ + _) instead of pets.reduceByKey(lambda x, y: x + y).
This is how you can do word count in 2 lines of code!! As opposed to the wordy MapReduce implementation…
lines = sc.textFile("hamlet.txt")
counts = lines.flatMap(lambda line: line.split(" "))
.map(lambda word: (word, 1))
.reduceByKey(lambda x, y: x + y)
.saveAsTextFile("results")val textFile = sc.textFile("hamlet.txt")
textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey((x, y) => x + y)
.saveAsTextFile("results")
// Less verbose
val textFile = sc.textFile("hamlet.txt")
textFile.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+ _)
.saveAsTextFile("results")Other Key-Value Operations
visits = sc.parallelize([("index.html", "1.2.3.4"),
("about.html", "3.4.5.6"),
("index.html", "1.3.3.1")])
pageNames = sc.parallelize([ ("index.html", "Home"),("about.html", "About") ])
visits.join(pageNames)
# ("index.html", ("1.2.3.4", "Home"))
# ("index.html", ("1.3.3.1", "Home"))
# ("about.html", ("3.4.5.6", "About"))
visits.cogroup(pageNames)
# ("index.html", (["1.2.3.4", "1.3.3.1"], ["Home"]))
# ("about.html", (["3.4.5.6"], ["About"]))Setting the Level of Parallelism
All the pair RDD operations take an optional second parameter for number of tasks
words.reduceByKey(lambda x, y: x + y, 5)
words.groupByKey(5)
visits.join(pageViews, 5)
sc.TextFile("file.txt", 5)There is a minimum....
If a file is split into 16 blocks on HDFS, and you open it with textFile(PathString, 10), you’ll still get 16 partitions, not 10.
What is the default level of parallelism?
It uses the same number of partitions for destination as the source has.
- Ex: a
reduceByKeyon an RDD with 8 partitions will result in another RDD with 8 partitions.
If you specify spark.default.parallelism it will use this as the default instead! (For shuffles only, not parallelize textFile or other base RDDs)
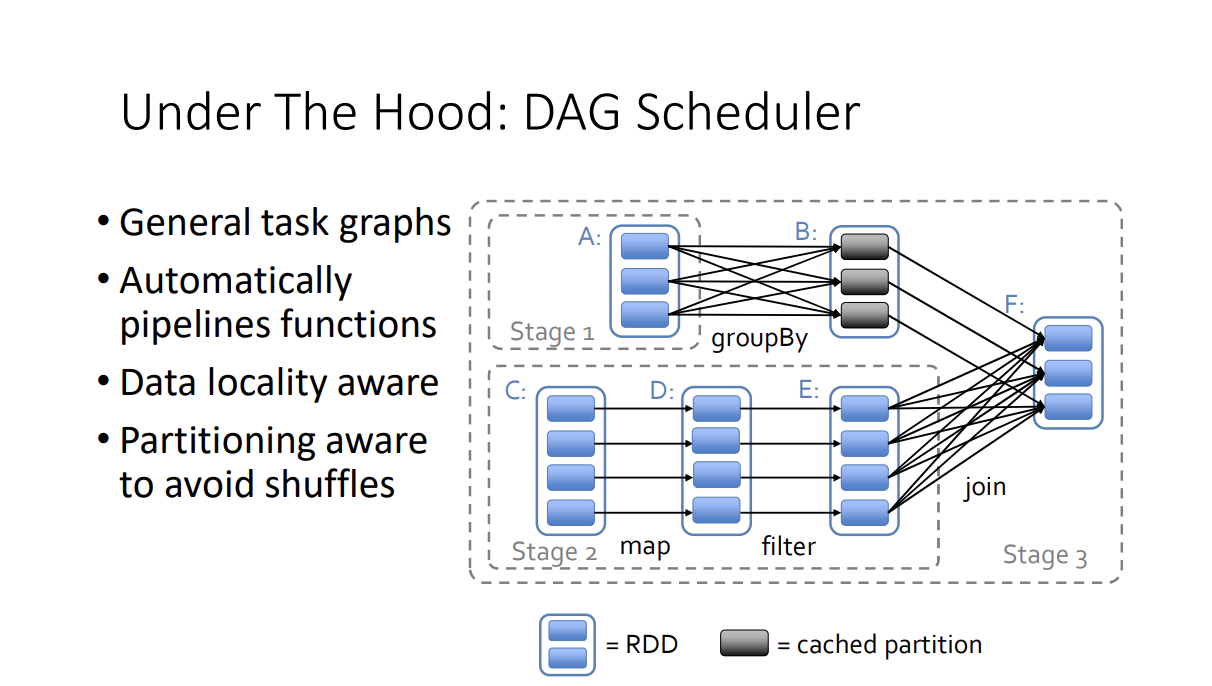
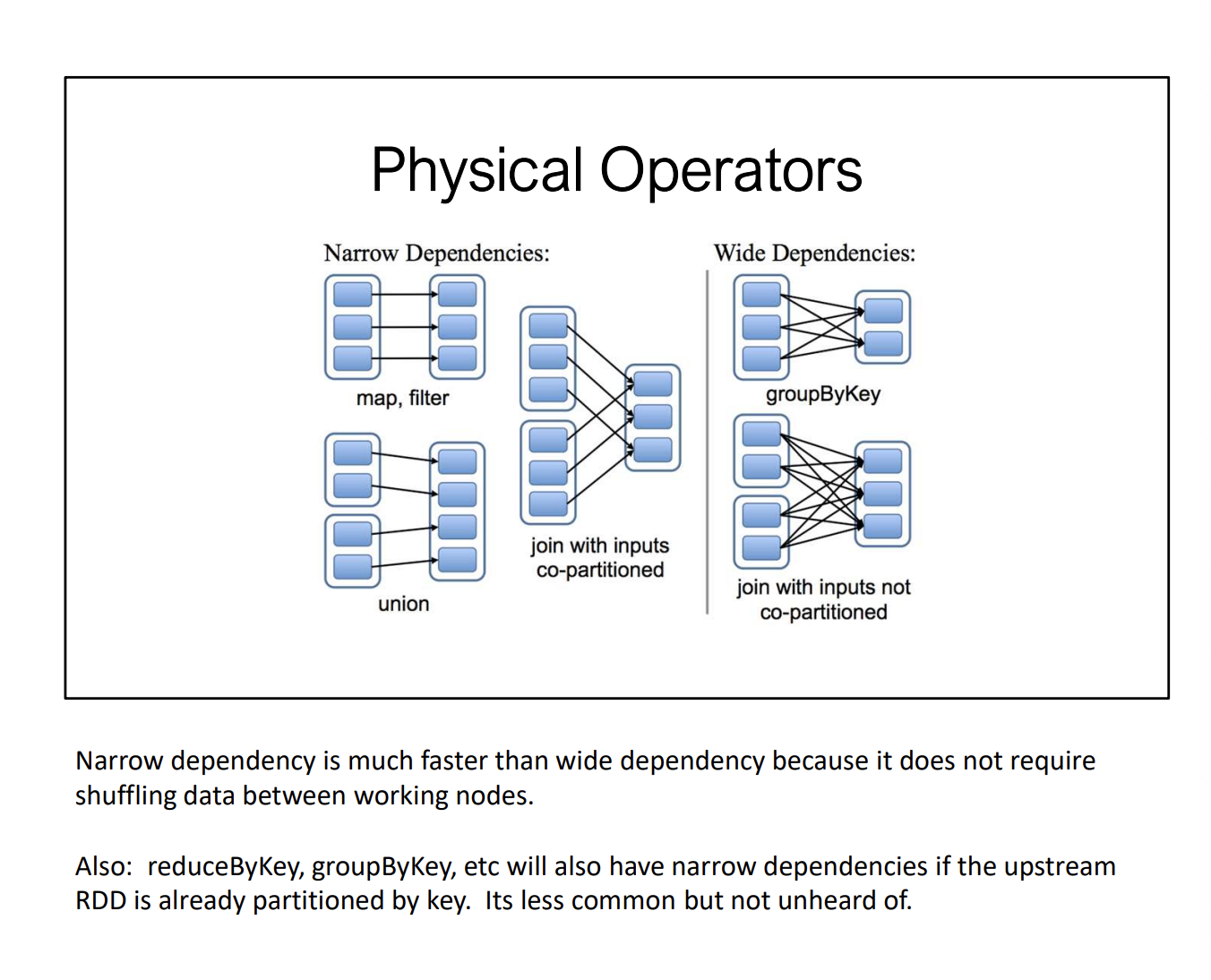
Since Spark is lazy evaluated, we can start building a graph under the hood and be more optimized!