MapReduce
So this exists before CUDA times.
Solve Embarrassingly Parallel problems.
Hemal Shah is telling me that this was one of the revolutionary ideas that enabled us to train neural networks at scale. And the stuff that the Google Brain team was doing was super duper cool.
From CS451
MapReduce is based around Key-Value Pairs.
Map-Reduce v1
The programmer defines two functions (will eventually build up to four):
- map:
- reduce:
For example, consider wordCount (counting the number of words they appear in a corpus of text).
Your mapper will count of the number of times a particular word appears in a line of text):
Input (Mapper)
- : integer (line number)
- : string (line of text)
Output (Mapper) It will emit , where
- is the word
- is the number of times the word is counted

How does the mapper know which input to take?
It’s pretty straightforward. Let’s say you have 10 mappers, then each mapper takes 1/10 of the file.
If you use frameworks like Hadoop, this is abstracted away from you.
At the reducer level, we get the same key . The reducer gets ALL values associated with that key: .
The magic of the reducer
The magic happens because we now have all the values associated with a given key, AND it’s sorted!!
How does this work at a hardware level? See at “hardware implementation” section.

The reducer can then just sum up all the values to get the total word count for a given word . Usually, .
Notice that there is bottleneck in the reducer if we use a single reducer.
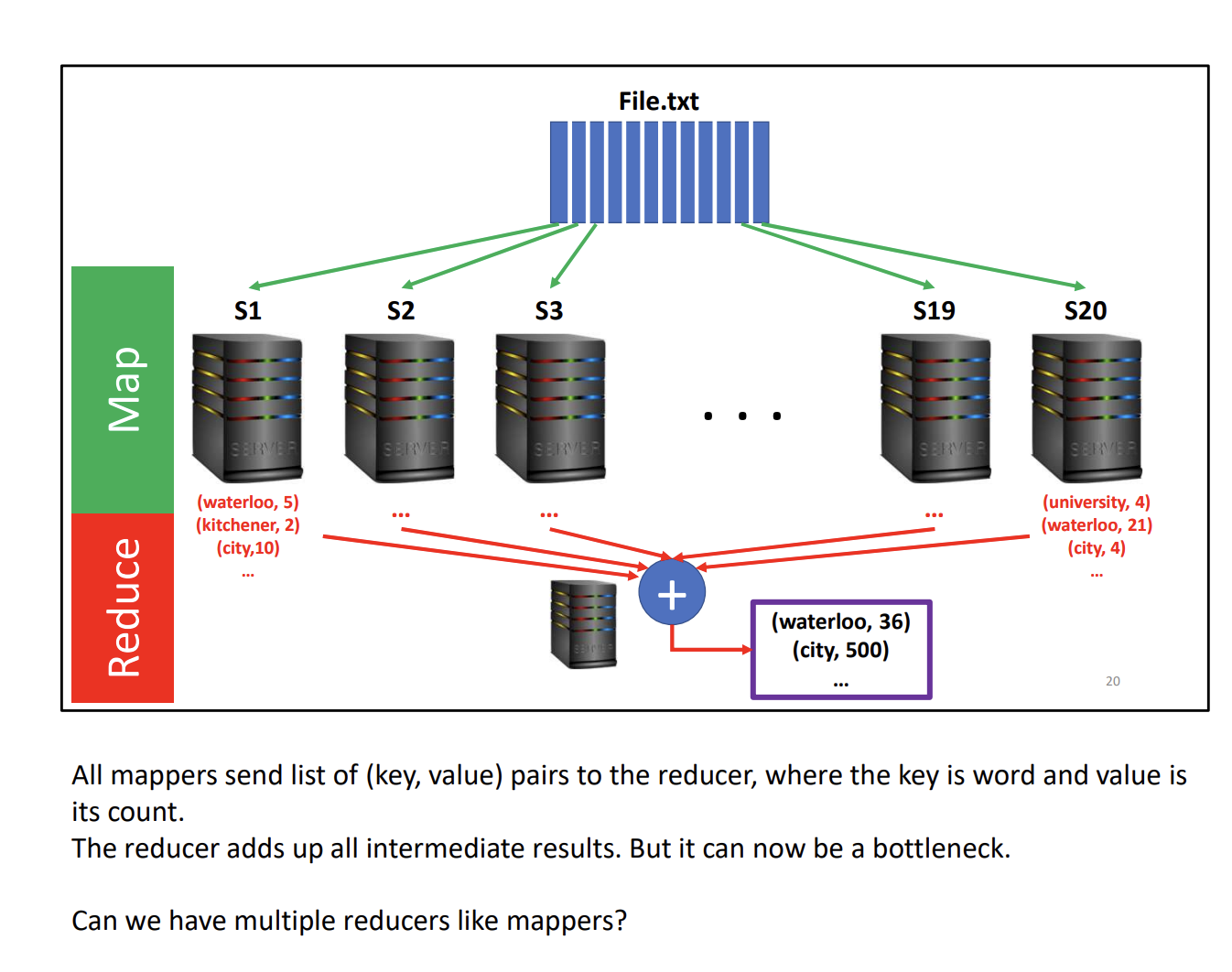
We can implement multiple reducers, but we need to figure out a way to route each mapper to the a correct reducer.
This is what the partitioner does.
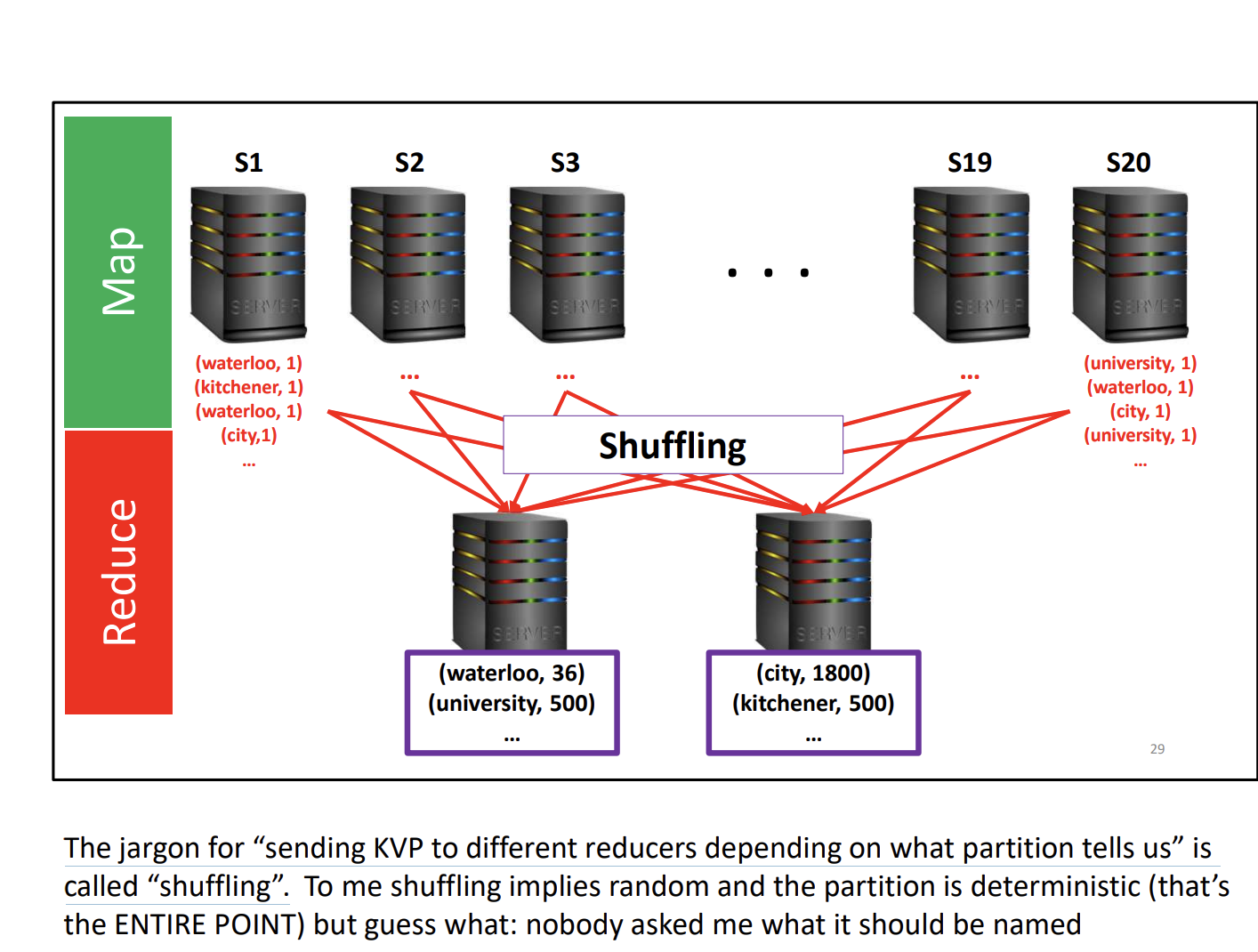
Why is it called shuffling??
The jargon for “sending KVP to different reducers depending on what partition tells us” is called “shuffling”.
So it’s not actually shuffling under the hood, it’s just determining which reducer to send it to based on the key.
Is there a default partition implementation?
Yes, they use this formula:
Partition Number=(Key.hashCode()%Number of Reducers)If they key cannot be hashed, then it will return an error.
So we also have the implement the partition function (though there is a default). Here’s what the code looks like:
def map(pos : Long, text: String):
for word in tokenize(text):
emit(word, 1)
def reduce(key: String, values: Collection of Ints):
sum = 0
for v in values:
sum += v
emit(key, sum)
def partition(key : String, reducer_count: Nat):
return hashcode(key) % reducer_count- Note here that we are now doing
emit(word, 1)instead ofemit(word, wordCount)(keeping track of how many times we’ve seen it in a line, which would require a dictionary)- If you do
emit(word, wordCount), that’s essentially an in-memory combiner!
- If you do
But just use
emit(word,wordCount)no??Because now you have state! Can the mapper hold the keys and values in memory for every single key?
- The very reason we designed MapReduce is because we are not able to process everything in memory.
- So
emit(word, 1)is more suitable for scalability.
But actually,
emit(word, wordCount)is a double edge swordYes, you should avoid remembering things because you might end up trying to remember too much.
- HOWEVER, if you’re sure there won’t be too many things, then you can!
- You use an in-memory combiner
Bigram implementations https://git.uwaterloo.ca/cs451/bespin/-/blob/master/src/main/java/io/bespin/java/mapreduce/bigram/BigramCount.java
But we can do even faster!! Introducing the combiner!!
- Notice that the mapper now emits multiple values for the same key
What if we were able to only have 1 value per key per mapper?
- Note that if we did
(word, wordCount), that would be an in-memory combiner
However, MapReduce prefers you do that in the combiner.
def combine(key, values):
sum = 0
for v in values:
sum += v
emit(key, sum)How combiners help
Combiners improve performance by reducing network traffic.
- Combiners work during file merges. Local filesystem is faster than network access.
- And memory is even faster than the filesystem
MapReduce final version
Programmer defines four functions:
- map:
- Combine:
- reduce:
- partition:
- Combine is an OPTIONAL thing the mapper / reducer MIGHT do when idle.
Note that the signature is the same as reduce, EXCEPT: input and output types are NOT allowed to be different.
Conceptually it should always be producing ONE key-value pair, since the whole point is to combine many values into one for the same key. The signature allows shenanigans and/or malarky. Keep this to a minimum, or avoid entirely.
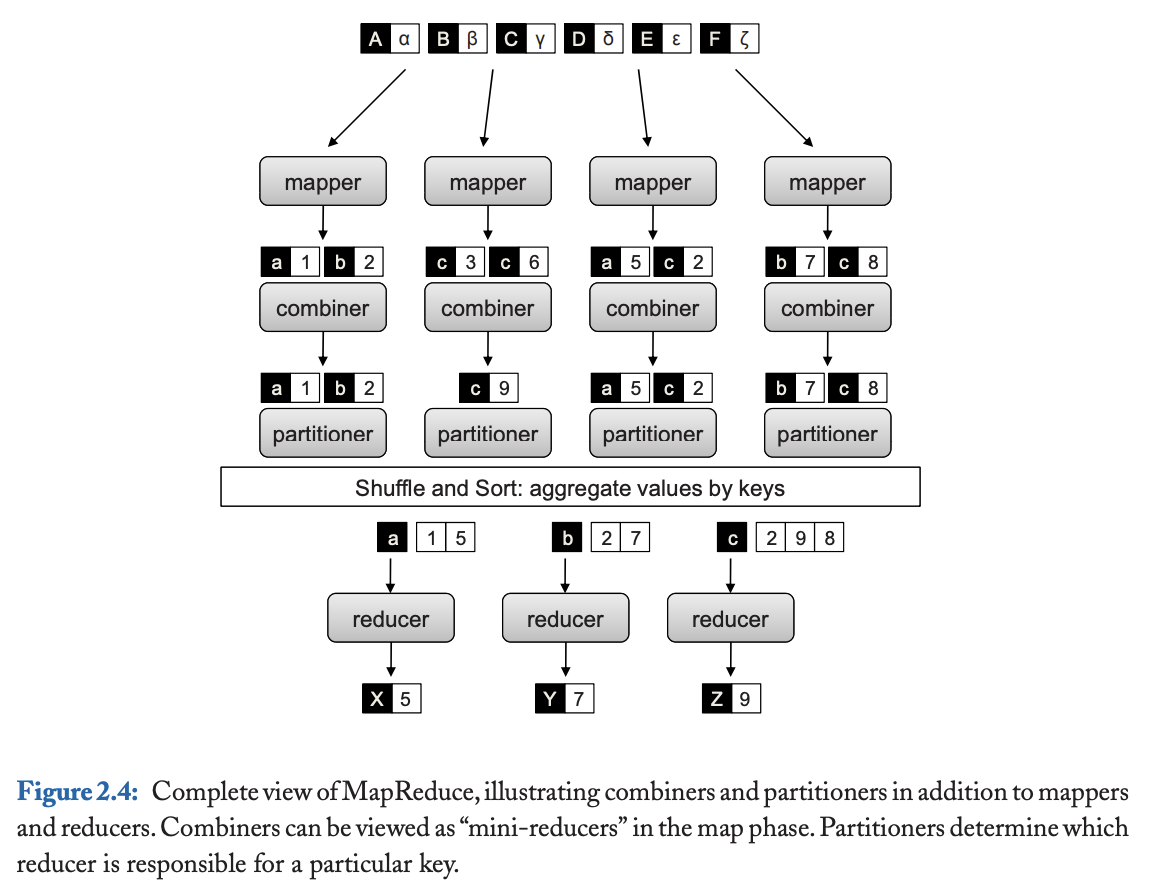
Combiner is a process that runs locally on each Mapper machine to pre-aggregate data before it is shuffled across the network to the various reducer clusters.
Combiners are optional
- May not be run
- May run once
- May run many time
In-Mapper Combiner (IMC)
Combiners
I’m a little confused on the role of combiners. Like the reducer will do that job anyways, so how does a combiner help?
MapReduce Physical view / Hardware Implementation
Also see HDFS, for how files are stored.
In MapReduce, the mapper stores intermediate results on physical disks, organized by key. Where specifically does it store it?
- They’re stored in Spill Files and are grouped and sorted by key to facilitate the reduce phase
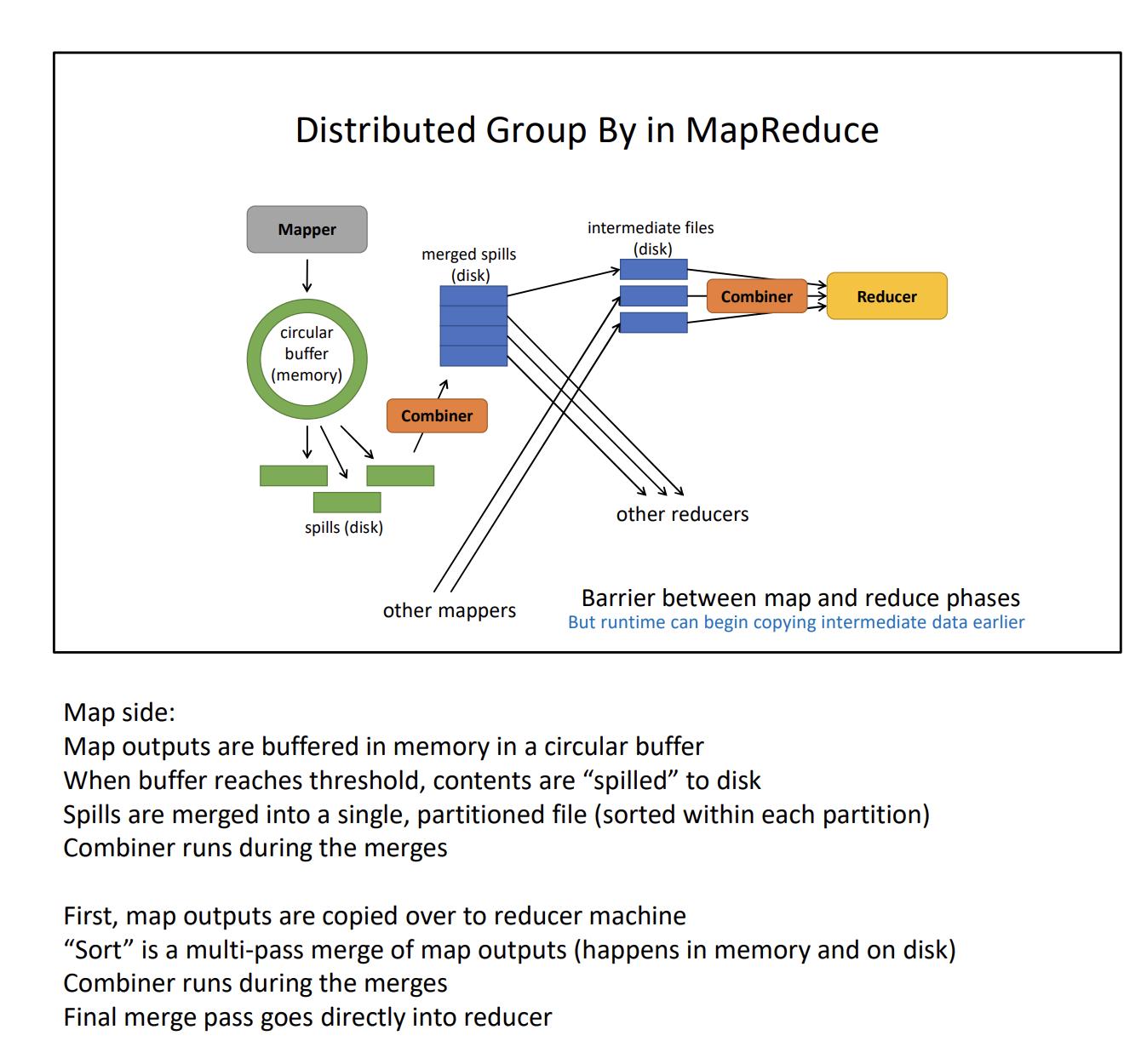
For each key, it is only written to 1 partition on the reducer side.
Note
Where the mapper/combiner (optional) writes to depends on the number of reducers. For example, if there are 4 reducers, the mapper can write to 4 different partitions.
- keys are stored in spill files (not RAM because too large)
- Each key will be “routed” to the correct reducer based on the partitioning scheme
- Reducer also combines keys together (those outputted by mappers)
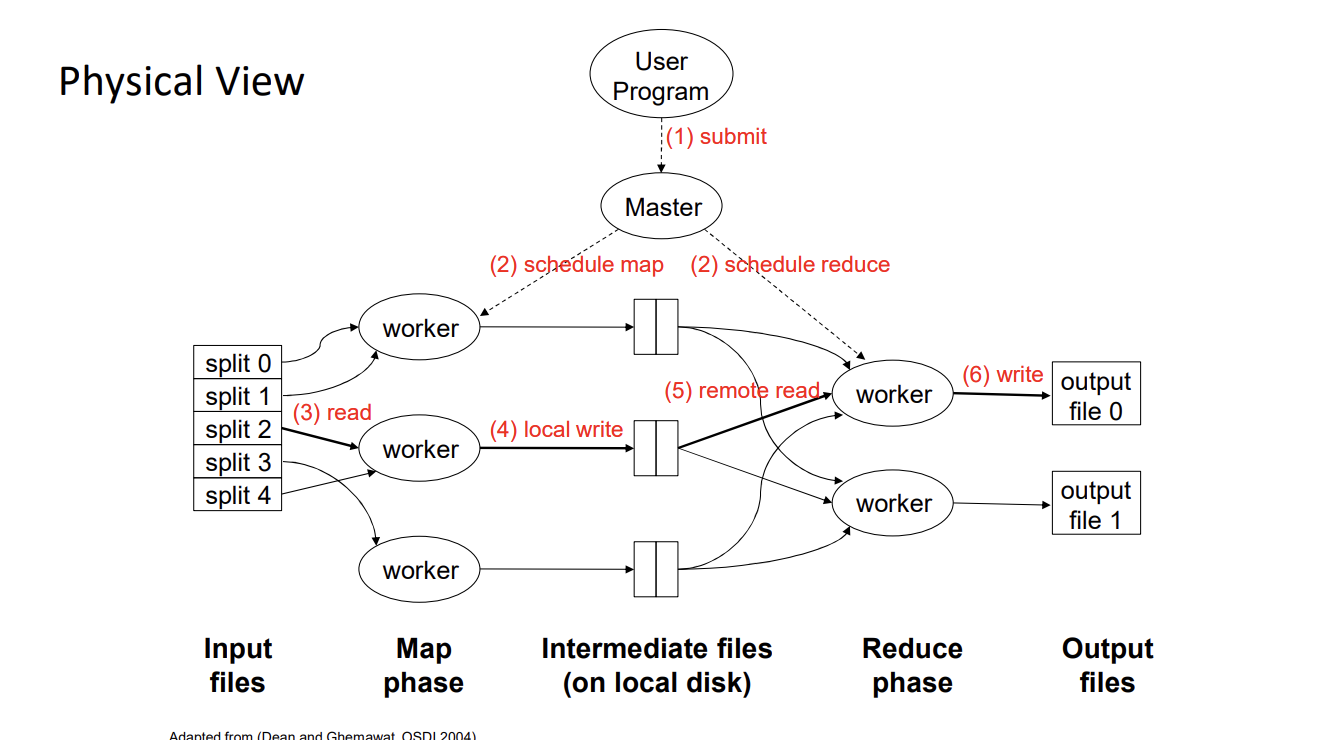
Sorting
The key contribution I feel in MapReduce is this distributed sorting.
In MapReduce, sorting happens at multiple stages, and each stage has specific responsibilities:
- Mapper Sorting
- Reducer Sorting
Mapper Sorting (in-memory sort)
- Who Does It?
- The Map Task (mapper) itself performs an in-memory sort as it processes the key-value pairs.
- When Does It Happen?
- After the mapper produces intermediate key-value pairs, they are written to an in-memory buffer.
- Once the buffer reaches a threshold, the spill-to-disk process occurs. During this spill, the MapReduce framework sorts the key-value pairs by key in memory before writing them to the disk.
- Details of Sorting in the Mapper:
- This sort is a local sort, meaning it only sorts the key-value pairs generated by a single mapper.
- If there are multiple spill files, a merge sort combines them into a single sorted file (per partition).
Reducer Sorting (merge operation)
- Who Does It?
- The Shuffle and Sort phase, which is part of the reducer’s preparation process, performs sorting after the intermediate data is shuffled across the network.
- REMINDER: Here, shuffling = partitioning + merging, i.e. assigning output of mapper to the correct reducer
- The Shuffle and Sort phase, which is part of the reducer’s preparation process, performs sorting after the intermediate data is shuffled across the network.
- When Does It Happen?
- During the Shuffle and Sort phase, intermediate data from all mappers (for a given reducer key) is fetched, merged, and sorted by key before being passed to the reducer function.
- Details of Sorting in the Reducer:
- The reducer merges data from multiple mapper outputs (one per mapper) into a sorted order.
- This global sort ensures that all values for a given key are grouped together for the reduce function.
Refer to this diagram if you not sure
Counting co-occurrence (Pairs)
Term: Co-Occurrence
- : number of times word and word cooccur in some context
- E.g. how many times is followed immediately by in a sentence is , where is the vocabulary
How do you deal with keys that are pairs?
Two options:
- Pair – We’ll be computing individual Cells
- Stripe – We’ll be computing individual Rows
First option: combine the keys into a pair.
Input: Sentence
Output: ((a,b), 1) for all pairs of words a,b in the sentence.
def map(key : Long, value: String):
for u in tokenize(value):
for each v that coöccurs with u in value:
emit((u, v), 1)
def reduce(key: (String, String), values: List[Int]):
for value in values:
sum += value
emit(key, sum)Disadvantage
That’s a lot of pairs to be fair (order matters). The combiner also doesn’t do much?
- The combiner won’t do much because there are N x N potential keys. Most keys will have few entries, so there will be few cases where the combiner reduces the number of pairs.
Second Option: Use Stripes
Input: Sentence Output: , where:
- is a word from the input
- are all words that co-occur with a is the number of times co-occur
- means a map (aka a dictionary, associative array, etc)
def map(key: Long, value: String):
for u in tokenize(value):
counts = {}
for each v that co-occurs with u in value:
counts(v) += 1
emit(u, counts)
def reduce(key: Long, values: List[Map[String->Int]]):
for value in values:
sum += value
emit(key, sum)- Fewer key-value pairs to send
- Combiners will do more work
- Map is a heavier object than a single
- More computationally intensive for the mappers and combiners.
Intuition
Better CPU utilization in using stripes.
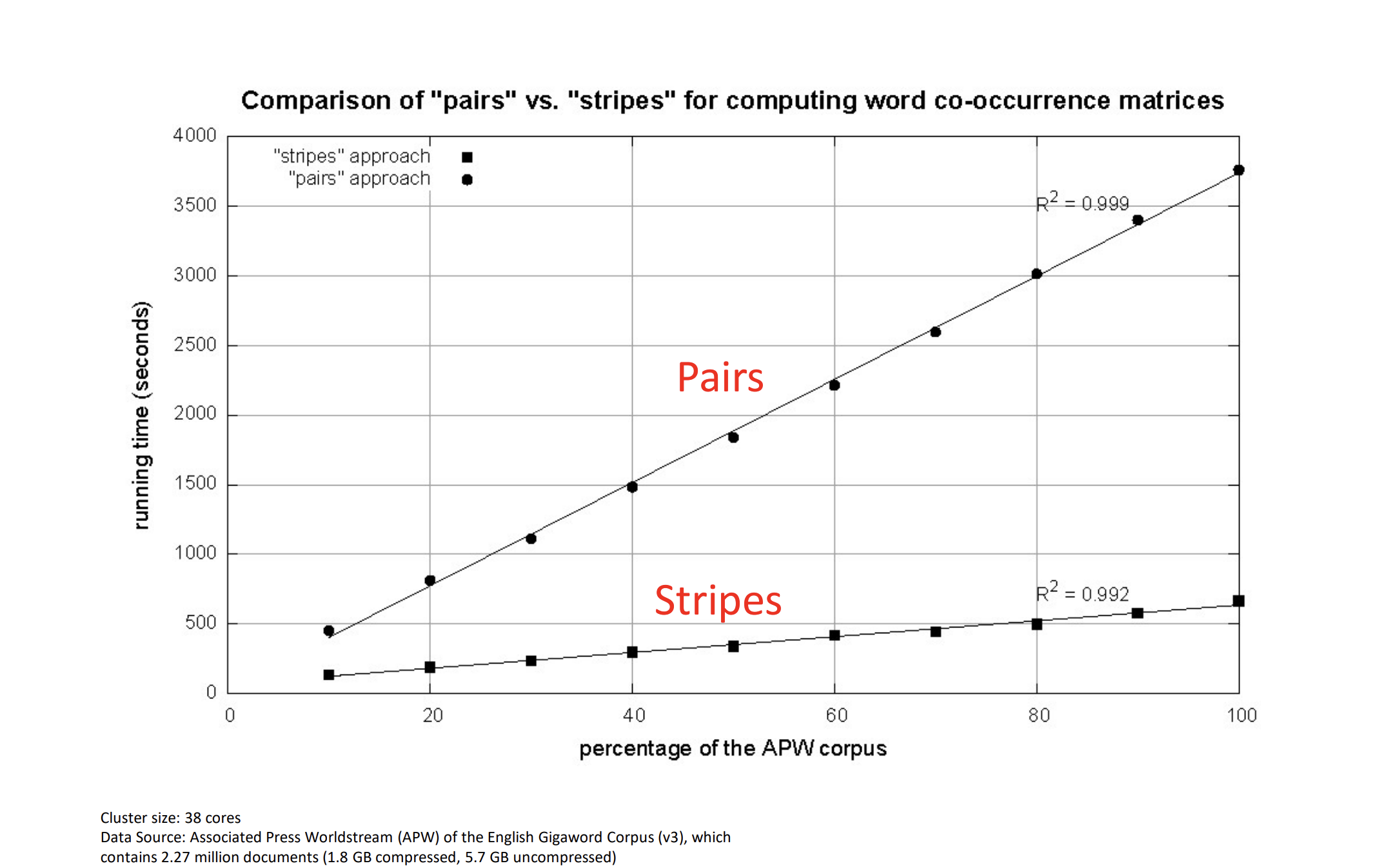
Why doesn’t it grow polynomially? Like don’t you have O(n^2) different pairs?
In a practical MapReduce setup, each mapper processes smaller subsets of the dataset (for example, one document, basket, or chunk of data at a time).
- Suppose there are n words and k sentences
- Each worker processes m = n/k words
- Each mapper does O(m^2) work.
In most real-world datasets, (the number of items per basket/document) is relatively constant or small compared to , which is the total number of baskets/documents.
Thus, the total work done by all mappers across the dataset is roughly proportional to .
So the trick is by reducing the constant time factor.
Should you always use stripes?
It’s a tradeoff. “Easier to understand and implement” is NOT bad. For English words and normal sentence lengths, the stripe fits in memory easily. It won’t always work out that way.
Another Problem, Relative Frequencies Where
- is number of co-occurrences of and , and
- is the sum of over all
Why do we want to do this? How do we make it fit into MapReduce?
#todo CHECK about the two passes thing
We want to do this, but we don’t have access to freq(a) :( This is only known at the reducer level.
DOESN’T WORK
def reduce(key:Pair[String], values: List[Int]):let (a, b) = key
for v in values:
sum += v
emit((b, a), sum / freq(a))We need to do something elaborate.
def map(key: Long, value: String):
for u in tokenize(value):
for v in cooccurrence(u):
emit((u, v), 1)
// emit((u, “*”), 1) // improved using line below
emit((u, “*”), len(cooccurrence(u))
def partition(key: Pair, value: Int, N: Int):
return hash(key.left) % N
marginal = 0
def reduce(key: Pair, values: List[Int]):
let (a, b) = key
for (v in values):
sum += v
if (b == “*”):
marginal = sum
else:
emit((b, a), sum / marginal)- The reducer works! That’s because Hadoop sorts the keys. Pairs will sort lexicographically by the first key, and then the second. So So comes before any because the ASCII code of * is 42.