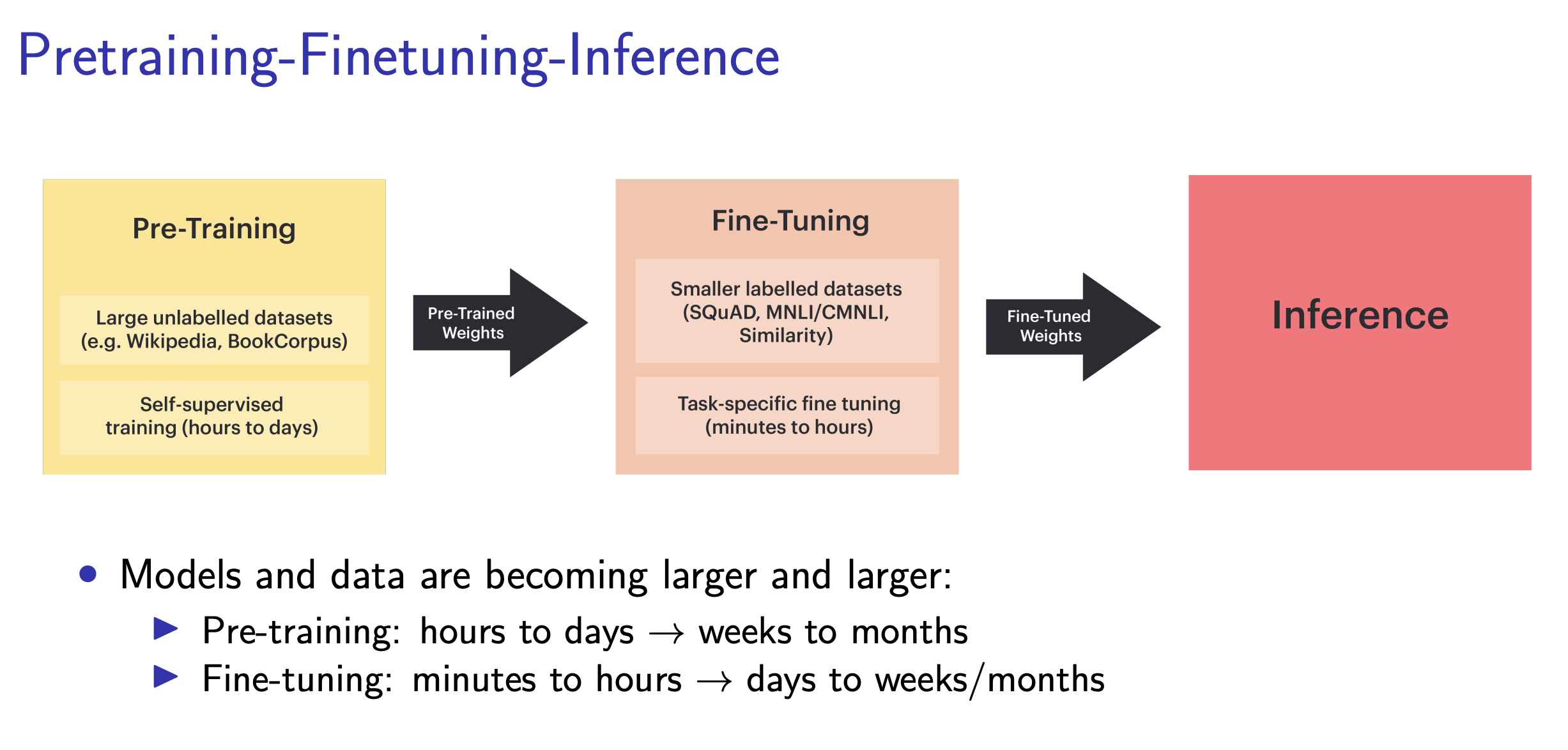
Large Language Models (LLM)
Large Language Models are Transformer-based language models scaled to hundreds of billions of parameters, trained on internet-scale text.
The progression BERT (2018) → GPT-3 (2020) → ChatGPT (2022) shows how bigger models, more data, and alignment post-training transformed NLP.
BERT (Google, Oct 2018), Encoder-Only
Architecture: encoder-only Transformer, 340M parameters. Special tokens [CLS] (classification aggregate) and [SEP] (separator).
Pre-training objectives (self-supervised):
- Masked Language Modeling: predict masked-out tokens from bidirectional context. Static masking (fixed mask per example).
- Next Sentence Prediction: given two sentences, predict whether the second follows the first.
Fine-tuning: replace the MLM/NSP head with a task-specific head; continue training on labeled data (e.g., SQuAD).
Data: BooksCorpus + Wikipedia.
Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
RoBERTa (Facebook/UW, Jul 2019)
“Robustly Optimized BERT”, same architecture, better training recipe:
- Remove NSP objective (didn’t help)
- Dynamic masking (re-mask each epoch)
- 10× more data (16 GB → 160 GB: CC-News, OpenWebText, Stories)
- 15× more tokens (500k steps × batch 8000 vs BERT’s 1M × 256)
Outperforms BERT on GLUE. Paper: RoBERTa.
GPT Family, Decoder-Only
Pre-training objective: next-token prediction (maximum likelihood on ). Autoregressive, unlike BERT’s bidirectional MLM.
Intuition
All you’re doing is predicting the next token given everything before. The surprising thing is that scaling this one loss produces reasoning, translation, code, explanations: emergence from compression under a pure likelihood objective. To predict the next word of a physics proof well, the model effectively has to learn physics.
| Model | Year | Params | Data | Note |
|---|---|---|---|---|
| GPT-1 | 2018 | 117M | BooksCorpus | Pretrain + task fine-tuning |
| GPT-2 | 2019 | 1.5B | WebText (40 GB) | Zero-shot, “English: Hello. French: ” |
| GPT-3 | 2020 | 175B | Filtered CC (570 GB) + WebText2, Books, Wiki | In-context learning |
| ChatGPT | 2022 | ~GPT-3.5 | + RLHF | Consumer breakthrough |
Evaluation Metrics
Perplexity: exponentiated average negative log-likelihood, Lower is better. Geometric-mean inverse probability of tokens.
Read it as “the effective branching factor.” PPL = 20 means the model is about as confused as if it had to pick uniformly among 20 equally-likely next tokens at every step. PPL = 1 is perfect prediction; PPL = vocab size is total ignorance.
Benchmarks: GLUE (BERT era), SuperGLUE, LAMBADA (last-word prediction), MMLU, HELM.
Scaling Laws (Chinchilla, 2022)
Three levers: parameter count , dataset size (tokens), compute (FLOPs). Rule of thumb: (Each token through each parameter: 2 FLOPs forward + 4 FLOPs backward.)
For fixed , which minimizes loss?
- Kaplan et al. 2020: , → scale parameters faster than data
- Chinchilla (Hoffmann et al. 2022): , → scale equally. Corrects Kaplan, most prior models were undertrained
You have a fixed FLOPs budget. A huge model that’s barely trained wastes parameters it never updated; a small model on infinite data plateaus because it lacks capacity. Chinchilla says: the sweet spot is equal scaling, roughly 20 tokens per parameter.
Takeaway: train a smaller model on more data. Paper: Training Compute-Optimal LLMs.
Chain of Thought (Kojima et al. 2022)
Prepending “Let’s think step by step” to the prompt makes the model produce intermediate reasoning steps, and get more answers right. Zero-shot CoT. Later: few-shot CoT with reasoning demonstrations. Paper: Large Language Models are Zero-Shot Reasoners.
A forward pass is fixed compute per token. Reasoning problems need more compute than one token affords, so the model cheats: it writes its scratch work into the context and then reads it back. Each intermediate step is extra serial compute.
Instruction Tuning
Problem: pretrained models continue text, don’t answer questions.
- Prompt: “Write a poem about ML.”
- Raw GPT generation: “Write a short story about data science. Write an essay about neural networks.” (continues the list!)
Fix: fine-tune on (instruction, response) pairs:
FLAN (Google, 2021): instruction-tune T5 on many tasks in instruction format → generalizes to unseen tasks. Paper: FLAN.
RLHF (InstructGPT → ChatGPT)
Problem: instruction-tuning makes the model respond to instructions, but not necessarily in the way humans want (safety, helpfulness, honesty).
Three-step pipeline:
- Supervised fine-tuning (SFT): fine-tune on human-written (prompt, response) pairs
- Reward model: for each prompt, sample completions, have humans rank them, derive pairwise comparisons. Train :
where:
- is the winning response
- is the losing response
- PPO (Proximal Policy Optimization) to maximize reward while staying close to the SFT model: The KL term is the “alignment tax”; it prevents the RL model from drifting too far from coherent language
Intuition
The reward model learns to imitate human preference from pairwise rankings (Bradley-Terry: ). PPO then treats the model as a policy and climbs that reward, while the KL penalty tethers it to the SFT language model so it doesn’t collapse into reward-hacking gibberish. Without the tether, the policy finds the shortest token sequence that scores high and forgets how to write.
Paper: InstructGPT.
Slides from CS480 lec19.
Related Concepts
Models:
- Gemma
- GPT / BERT / RoBERTa / Chinchilla (see above)
How many epochs? Can be only 1, LLMs typically train in the “high-data” regime where each token is seen once. See https://www.reddit.com/r/LocalLLaMA/comments/1ae0uig/how_many_epochs_do_you_train_an_llm_for_in_the/