Monte-Carlo Learning
Monte-Carlo Learning is a Model-Free Policy Evaluation method. it is unbiased..? (i think every visit is biased?)
Intuition: Takes averages of actual returns over episodes. As more returns are observed, the average should converge to the expected value.
- MC methods learn directly from episodes of experience
- MC learns from complete episodes: no bootstrapping
- Caveat: This means that we can only apply it to episodic MDPs, i.e. all episodes must terminate
- Handles non-markovian domains
MC Policy Evaluation
Goal: learn from episodes of experience under policy
Monte-Carlo policy evaluation uses empirical (the actual) mean return instead of expected return as we saw in Policy Iteration.
- Updates at the end of each episode
- is an estimate of the value function using sample of return to approximate the expectation
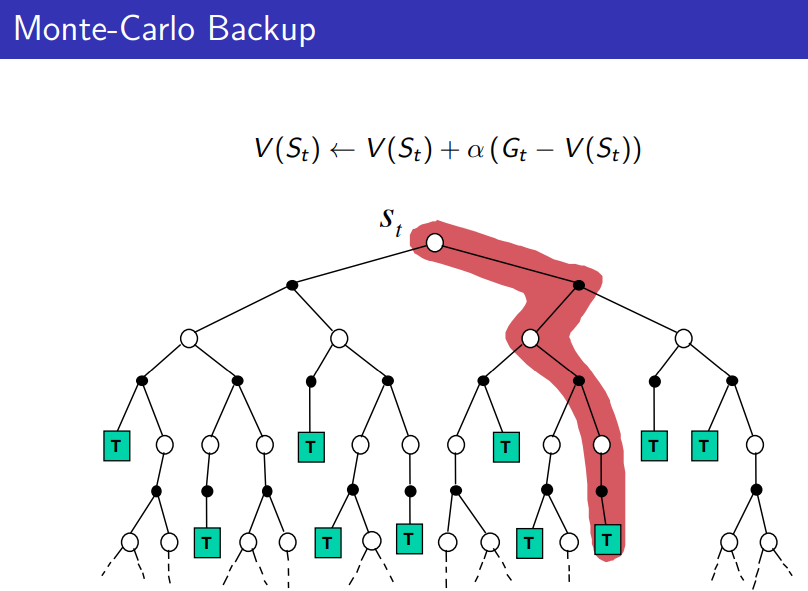
- is an estimate of the value function using sample of return to approximate the expectation
First-Visit Monte-Carlo Policy Evaluation
For each state visited in episode ,
- The first time-step that state is visited in episode
- Increment counter
- Increment total return
- Value is estimated by mean return
- By Law of Large Numbers, as
Properties:
- estimator is an unbiased Estimator of true

Every-Visit Monte-Carlo Policy Evaluation
Same a first-visit, but update is done every time-step that state is visited in episode .
Properties:
- every-visit MC estimator is a biased estimator of but consistent estimator and often has better MSE.
Incremental Monte-Carlo (MC)
Monte-Carlo methods can be implemented incrementally by using the Incremental Mean.
- Update incrementally after episode
- For each state with return
We can replace with to get a more general Incremental MC Policy Evaluation:
- If we set , then we attribute higher weight to newer data
