Temporal-Difference Learning
Intuition: Don’t wait until the end of every episode each time to update. Only wait until the next time step.
- TD learns from incomplete episodes, by Bootstrapping
- TD updates a guess towards a guess
Because of this, unlike the Monte-Carlo Learning,
- TD can learn before knowing the final outcome
- TD can learn without the final outcome
TD exploits the MDP structure.
TD Policy Evaluation
Goal: learn online from experience under policy
Simplest TD learning algorithm TD(0): Update value ) towards the TD Target () where is the TD error between the estimated returns:
Notice the similarity/difference with Monte-Carlo Learning. We just replace with the Bellman Expectation Backup, . Because we do this, the problem has to be MDP. This isn’t mandatory for Monte-Carlo.

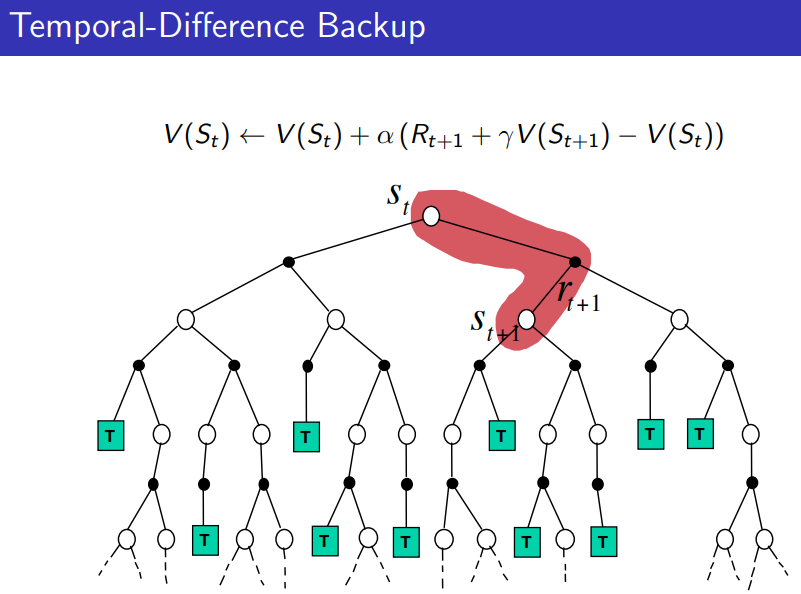
How a TD backup looks like:
TD()
Combines the best out of both world. See Bias - Variance Tradeoff.
TD(
\lambda)\neqtaking the\lambda-step returnForward TD-()looks most similar to -step return, however -return is not quite n-step Reinforcement Learning.
The λ-return combines all n-step returns using weight
You combine all returns into this sort of geometric sum.
You use geometric weighting so the cost is the same as computing TD(0).
There is a forward view and backward view version. Forward-view TD(λ)
Backward-View TD() Keep an Eligibility Trace for every state .
No one talks about td-lambda nowadays?
In deep RL, TD(λ) is rarely used directly, because:
- Neural networks already provide generalization, so the forward-view λ-return trick doesn’t provide the same advantage as in tabular settings.