Perceptron
The perceptron is the simplest neural network: a linear binary classifier that learns a hyperplane by making “lazy” updates only on mistakes.
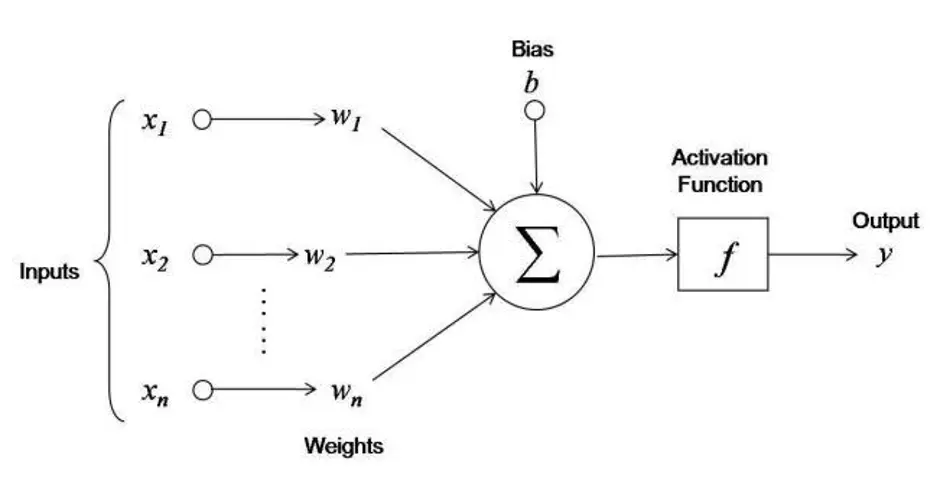
- A MLP just stacks multiple of these per layer, and increases the number of layers
- The simplest perceptron doesn’t even have an Activation Function, the output is just

Setup: Binary Classification
Given pairs with feature vectors and labels . Learn such that .
Assumption
The data is linearly separable: there exists some hyperplane that perfectly splits the classes.
Algorithm
Weight vector , bias . Typically initialize , set .
For each :
- Predict
- Lazy update (only on a mistake): if , then and
Intuition
The update rotates toward . If we got the sign wrong on , nudging in the direction of increases next time, pushing the hyperplane to put on the right side. It is the minimal local correction that makes this one point less wrong.
Padding + Pre-Multiplication Trick
To absorb the bias into the weight vector and simplify the analysis:
- Let and replace with . Then
- Let . Then the goal becomes for all , i.e., entrywise, where is the matrix with rows
Linear Separability and Margin
The dataset is separable with margin if there exists such that for all . The (normalized) margin is
where:
- is the (normalized) margin
- are the (padded, signed) data points
- is a unit-norm candidate separator
Large margin means easy to classify; small margin means hard.
Geometric picture
The margin is the width of the thickest slab you can draw between the two classes. A wide slab means small perturbations in the data cannot flip a point’s side, so any reasonable separator works. A razor-thin slab means the boundary has to be threaded precisely.
Perceptron Convergence Theorem (Mistake Bound)
Theorem. Suppose there exists such that . Then the perceptron correctly classifies the entire dataset after at most
where:
- is the largest data-point norm
- is a margin witness
- is the corresponding separator
Minimizing over the non-unique pairs (note ) gives the bound in terms of the margin:
Intuition:
- a large (points far from the origin) makes each update less effective
- a small margin means fewer directions work
- mistakes are bounded by , not by : feed the algorithm a million easy points and it still halts quickly, while a small but tight dataset can dominate the cost
Termination
When do we stop?
- All points classified correctly (training error stops decreasing)
- Validation error stops decreasing
- Budget exhausted, or weights stop changing
Not linearly separable
The algorithm never halts: perceptron will “cycle.” It is not the right algorithm for non-separable data. Use Logistic Regression or soft-margin SVM instead.
Uniqueness
Perceptron finds some separator, not the best one. SVM picks the max-margin separator, which generalizes better.
Multiclass Extensions
- One-versus-all: train classifiers (dog vs not dog, etc.), predict
- One-versus-one: train pairwise classifiers, take majority vote
From CS480 lec1.