Multilayer Perception (MLP) / Neural Network (NN)
A neural network is a universal function approximator built from stacked linear layers and nonlinear activations.
Why do we need activations at all?
Without them, stacking linear layers collapses to a single linear layer (). Activation Functions inject nonlinearity so that depth actually buys representational power.

- Credits to https://www.pinecone.io/learn/batch-layer-normalization/ for inspiration on how to draw it
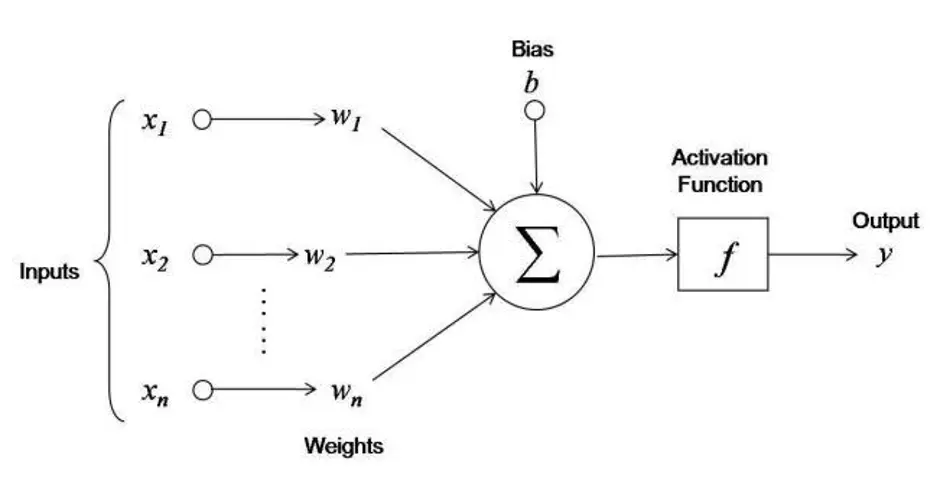
The sum and the + bias are visualized separately but are really the same operation. In matrix form:
where:
- is the weight matrix, the input, the bias vector
Geometric picture
A linear layer rotates, stretches, and shears the input space; the bias shifts the origin; the activation bends it. Stacking layers is stacking these transforms until clusters that were tangled become linearly separable in the final representation.
MLP vs. FFN?
All MLPs are FFNs, but not all FFNs are standalone MLPs. A CNN is a type of FFN composed of convolution and pooling layers followed by an MLP layer.
A fully-connected layer connects every node to every node in the adjacent layers.
For input and hidden dimension , we need and bias :
Concepts
Types of Neural Networks
Steps
- Import the training set which serves as the input layer
- Forward propagate the data from the input layer through the hidden layer to the output layer, producing a predicted value (multiply inputs by weights, apply the activation function)
- Measure the error between the predicted value and the real value
- Backpropagate the error and use gradient descent to modify the connection weights
- Repeat until the error is minimized sufficiently
Why we need them: feature transforms
From the CS231n Lec 4 slides. A linear classifier can’t separate non-linearly-separable data (e.g. red points clustered around the origin surrounded by blue points in a ring). Applying a feature transform makes the data linearly separable.
Neural networks learn the feature transform instead of hand-designing it:
- Hidden layer is the learned feature
- is the linear classifier on top
- Hence “fully-connected nets are stacks of linear layers + nonlinearities”
The rows of are like templates the network compares the input against, and the ReLU gates each template on or off. The last linear layer just combines these learned-feature activations. Classical ML asks humans to design the features; deep learning lets gradient descent discover them.
A 2-layer FC net on CIFAR-10 with hidden dim 100 learns ~100 templates (vs. 10 for a linear classifier) and shares templates between classes: “horse facing left” and “horse facing right” can each be one template, combined by the second layer.
Architecture terminology
The ”-layer” naming counts layers with weights, so the input layer doesn’t count:
- “2-layer net” = “1-hidden-layer net” = input → hidden → output
- “3-layer net” = “2-hidden-layer net” = input → h1 → h2 → output
Also called fully-connected networks or multi-layer perceptrons (MLPs).
Don't shrink the network to prevent overfitting
More hidden neurons = more capacity (more flexible decision boundary). Use a bigger network plus stronger L2 regularization instead. Smaller networks have non-convex landscapes with bad local minima; bigger networks find better solutions and you control overfitting via .
Full forward + backward in ~20 lines (numpy)
import numpy as np
from numpy.random import randn
N, D_in, H, D_out = 64, 1000, 100, 10
x, y = randn(N, D_in), randn(N, D_out)
w1, w2 = randn(D_in, H), randn(H, D_out)
for t in range(2000):
# Forward
h = 1 / (1 + np.exp(-x.dot(w1))) # sigmoid hidden
y_pred = h.dot(w2)
loss = np.square(y_pred - y).sum()
# Backward (analytical gradients)
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h.T.dot(grad_y_pred)
grad_h = grad_y_pred.dot(w2.T)
grad_w1 = x.T.dot(grad_h * h * (1 - h))
# Gradient descent
w1 -= 1e-4 * grad_w1
w2 -= 1e-4 * grad_w2This is the entire deep learning loop. Modern frameworks just automate the backward block via computational graphs + autograd.
Be careful with brain analogies
Biological neurons are dramatically more complex than the model: many cell types, dendrites do nonlinear computation themselves, synapses are stateful dynamical systems. The “neural” in neural network is a loose inspiration, not a model.
Vocabulary
- Input layer: what the machine always knows (e.g. the banking behavior of a customer)
- Hidden layer: where the magic happens
- Output layer: what the machine will predict (e.g. whether or not the customer will quit within 6 months)
- Node/Neuron: a thing that holds a number, represented by a circle
- Gradient descent: the algorithm that updates weights to improve accuracy
- Weights: updated each iteration, represented by the connections between neurons