Activation Function
An activation function is a non-linear function applied elementwise inside a Neural Network so that stacked layers don’t collapse to a single linear map.
Why does nonlinearity matter?
Without an activation, a 2-layer network is just with , a linear classifier. The activation is what lets the network compose hierarchical, non-linear feature transforms.
Intuition
Each activation is a “gate” with some shape. A linear combination picks a direction in input space, and the activation decides what to do with signals pointing that way: sigmoid says “pass through if positive-ish, else suppress”, ReLU says “pass through unchanged or kill entirely.” Saturation (sigmoid/tanh at extreme inputs) is the enemy of learning because the derivative goes to zero, so gradients can’t flow back through that neuron.
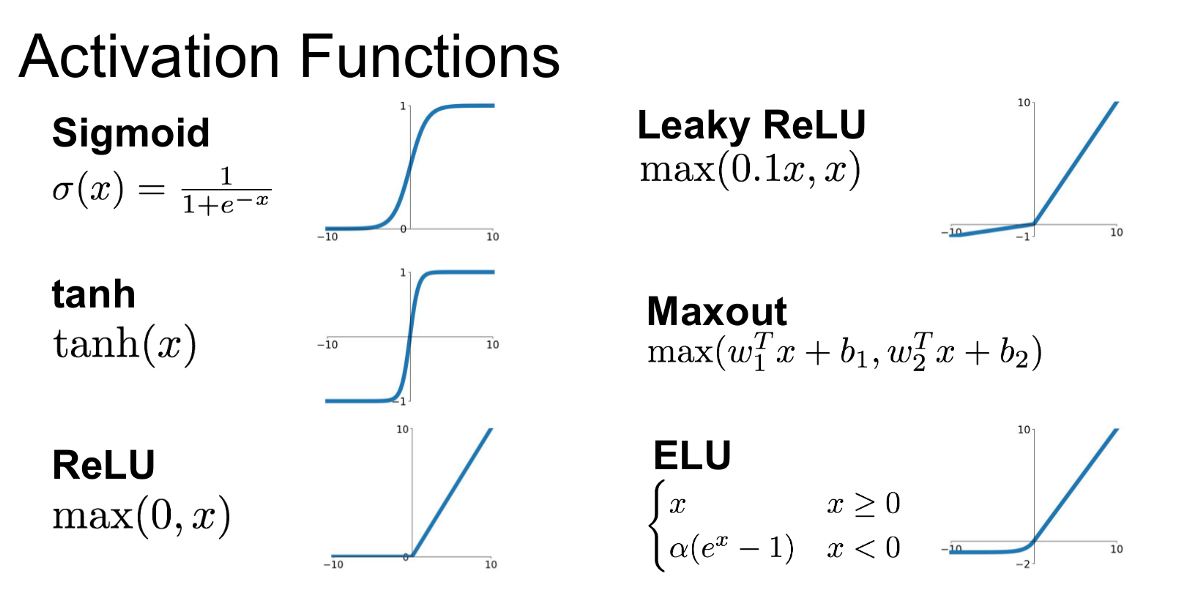
Common activations:
- Sigmoid Function: see the page for drawbacks, no longer used
- : still kills gradients when saturated, but zero-centered (vs sigmoid)
- Rectified Linear Unit (ReLU),
- Does not saturate in the positive region
- Very computationally efficient
- Converges much faster than sigmoid/tanh in practice
- More biologically plausible than sigmoid
- Drawback: not zero-centered, leading to “dead ReLU” units where gradient stays 0
- Leaky ReLU,
- Parametric ReLU,
- Exponential Linear Unit (ELU):
- All benefits of ReLU
- Closer to zero-mean outputs
- Negative saturation regime adds robustness to noise vs Leaky ReLU
- ELU/Leaky ReLU exist because “dead ReLU” is a real failure mode: once a neuron’s pre-activation is always negative, gradient is zero forever and that neuron never recovers. Letting a little negative signal through keeps the neuron alive
- Maxout Neuron
- Softmax Function
In general, just use ReLU and be careful with learning rates.
- From CS231n (?)
Parametric ReLU makes alpha a learnable parameter: https://datascience.stackexchange.com/questions/18583/leakyrelu-vs-prelu
There’s also Mish.
Modern defaults
From the CS231n Lec 4 slides:
- ReLU: safe default for FC/CNN layers, cheap, doesn’t saturate on positives
- GELU, (where is the standard normal CDF): default in Transformers (BERT, GPT), smooth, slightly negative-permitting near the origin
- SiLU / Swish, : used in newer vision models and Llama-style LLMs, smooth like GELU but cheaper
CS231n’s blunt rule of thumb: “ReLU is a good default choice for most problems.”